MySQL基础架构详解
目录
一、引言
二、MySQL基础架构图
2.1 MySQL基础架构零件分析
三、基础零件剖析
3.1 连接器
3.2 查询缓存
3.3 分析器
3.4 优化器
3.5 执行器
MySql学习专栏
1. MySQL基础架构详解
2. MySQL索引底层数据结构与算法
3. MySQL5.7开启binlog日志,及数据恢复简单示例
4. MySQL日志模块
一、引言
我们在学习MySQL的时候,迈入MySQL大门的第一步就是了解并安装MySQL客户端,随后才是使用MySQL做一系列数据库操作。但是往往被我们忽略的却是真正了解MySQL基础架构,为什么要这么说呢?因为在对数据库数据CURD操作的时候,也会出现一些问题或异常情况,此时并不是要去盲目的解决问题,而是直戳本质,快速定位并解决问题。
二、MySQL基础架构图
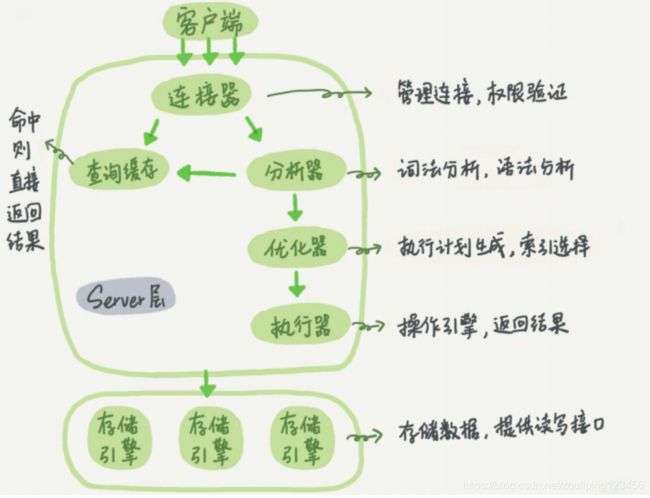
2.1 MySQL基础架构零件分析
Client层
- 连接器: 管理连接,权限验证
Server层
- 分析器: 词法分析,语法分析
- 查询缓存: 命中缓存,返回结果
- 优化器: 执行计划生成,索引选择
- 执行器: 操作引擎,返回结果
存储引擎层
- 存储引擎: 存储数据,提供读写接口
三、基础零件剖析
3.1 连接器
1. 建立连接
使用MySQL数据库,第一步是要连接MySQL数据库,这时候第一个迎接的你就是连接器。连接器负责跟客户端建立连接、获取权限、管理连接等工作
mysql -h$ip -P$port -u$user -p
mysql -h 47.103.20.21 -P 3307 -u root -p2. 获取权限
建立连接后,连接器就要开始进行身份认证,这个时候用的就是我们输入的用户名和密码。
如果用户名或密码不对,你就会收到一个 "Access denied for user" 的错误,然后客户端程序结束执行。如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
3. 维持和管理连接
连接完成后,如果没有后续的动作,这个连接就处于空闲状态,可以通过 show processlist 命令查看连接情况,如下图所示:
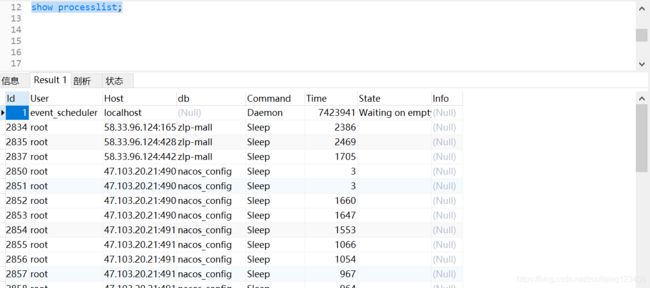
其中的 Command 列显示为“Sleep”的行,代表的是现在系统里面的空闲连接。客户端如果太长时间没动静,连接器就会自动将它断开。
这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果你要继续,就需要重连,然后再执行请求了。
数据库里面,有长连接和短连接的概念。
长连接:是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。
短连接:是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以在使用中要尽量减少建立连接的动作,也就是尽量使用长连接。
但是全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的,这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
解决方案就是 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
3.2 查询缓存
连接建立完成后,假设你正在使用该SQL语句查询一条数据
select * from tb_user where id = 1接下来MySQL执行逻辑就回到了查询缓存中。此时MySQL拿到一个查询请求后,先到查询缓存里看看是否执行过一这条SQL语句,在之前如果执行过这条语句,其结果大概就是以Key-Value(键值对)的形式直接缓存在内存中。这里的Key代指的是查询语句,Value代指的是查询结果。如果你所查询的语句在查询缓存中就命中缓存,它就会把该SQL语句对应的value值结果集返回,这样就并不会执行其他MySQL零部件了,大大提高了查询效率。
但是往往利弊是同时存在的,查询缓存有着一个致命的缺点,那就是查询缓存失效十分频繁。这里所说的查询缓存失效是指的只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此可能你废了很大的劲把结果存起来,还没使用呢,就被一个更新全清空了!大家都知道数据的宝贵,由于这个致命的缺点,导致查询缓存在MySQL8.0版本的时候就被抛弃了,也就是说MySQL8.0版本彻底删除了查询缓存!
需要在my.cnf配置
query_cache_type=0 (OFF)关闭
query_cache_type=1 (ON)缓存所有结果,除非select语句使用SQL_NO_CACHE禁用查询缓存
query_cache_type=2 (DEMAND),只缓存select语句中通过SQL_CACHE指定需要缓存的查询
按需使用缓存
select SQL_CACHE * from employees;查询缓存运行状态
show status like '%Qcache%';3.3 分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
注意: 一般语法错误提示第一个你所需要关注的是紧接着“use near”的内容,因为它会告诉你哪个语法附近有错误!
3.4 优化器
能进到优化器优化环节的SQL语句,说明在分析器分析的时候没有出现任何错误。那么优化器对该SQL语句做了些什么呢?假如一个SQL语句中是有索引的,优化器会根据优化规则选择合适的索引。或者是一个语句夺标关联时,优化器决定了各个表之间的连接顺序。这里我们看一个多表连接的SQL语句:
复制
select * from tb_user join tb_grade on tb_user.id = tb_grade.uid where tb_user.username = 'Ziph' and tb_grade.subject = 'Java';
-
先从tb_user表中取出username=Ziph的记录ID,再根据ID关联到tb_grade表,再判断tb_grade表中的subject是否等于Java
-
先从tb_grade表中取出subject=Java的记录ID,再根据ID关联到tb_user表,再判断tb_user表中的username是否等于Ziph
两种逻辑查询出的结果虽然是一样的,但是执行效率会有所不同,而优化器的作用就是根据自己的优化逻辑判断来决定使用哪一个方案
3.5 执行器
MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
mysql> select * from T where ID=10;
ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如我们这个例子中的表 T 中,如果ID 字段没有索引,那么执行器的执行流程是这样的:
1. 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
2. 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行;
3. 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
你会在数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。
在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。
参考博客
1. Mysql学习专栏之一(Mysql基础架构)