面试题总结 - js基础知识
前言:众所周知,HTML,CSS,JS是学习前端所必备的。js的基础学好了,框架类的vue,react等都会接受的很快,因此js是前端很总要的一个部分,这篇文章将会结合面试题,对js的知识点进行总结
号外号外,这是一篇长长的博客,所以耐心耐心,希望能有收获哦,加油~~~
1. 数据类型和转换
1.1 常见面试题
(1)typeof可以判断哪些数据类型
(2)什么时候使用 == ? 什么时候使用 === ?
(3)值类型和引用类型的区别是什么?
(4)手写深拷贝
1.2 知识点
1.2.1 有哪些数据类型?
- Number,String ,Boolean, Object(Array,Fuction...), Undefined, Null,Symbol
1.2.2 数据类型怎么分类,有什么区别?
(1) 数据类型分为 - 值类型和引用类型
值类型 - undefined, Number, String, Boolean,Symbol
引用类型 - Object, Null
(2) 区别
根据内存空间和cpu的耗时,值类型和引用类型在存储,拷贝等方面都不同
①存储地址
首先,存储空间分为栈和堆,一般情况,栈从上往下排列,堆从下往上排列,两种数据类型在栈堆中的表现各不相同,通过例子来查看
值类型的存储:
例1
let a = 100;
let b = a;
a = 200
console.log(b)打印出来的b显然是100,原因如下图:
值类型直接将值存储在栈中,在赋值过程中,开辟新的存储空间b,将a的值赋值给b,因此在去修改a与b无关了,a和b有各自的存储空间。
一般情况下 - 值类型,占用空间小
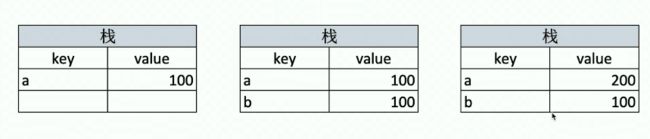
引用类型的存储:
例2
let a = {age: 20};
let b = a;
a.age = 21;
console.log(b)这个时候的b的age已经被改变,为21,原因如下图:
引用类型,是在栈中开辟了一个堆的存储地址,a的存储value假设是0x12(一个16进制), 这个地址在堆中就是age为12,引用类型是将栈的value进行赋值,也就是b的value其实也是ox12,指向了同一个堆的地址,因此a的改变会影响b的改变。也就是,a与b有各自的存储空间,但是他们的数据,其实在堆中都是同一空间
引用类型 - 占用空间可能很大,像json数据,内容空间和cpu的耗时来区分


注意 - Null的指针其实是指向了一个空地址、因此他也是一个引用类型
②拷贝
拷贝有深拷贝和浅拷贝
因为之前已经写过一次拷贝了,所以就不重复写了
https://blog.csdn.net/qq_42625428/article/details/103515192
深拷贝就是拷贝引用类型,像例2一样,赋值后并不想数据相互影响,这个时候就需要深拷贝
1.2.3 typeof
typeof - 判断所有的值类型,判断是否为引用类型,是返回object,能判断函数,是函数,返回function

1.2.4 变量计算 - 类型转换
(1)字符串拼接
let a = 100 + 10 //110
let b = 100 + '10' // '10010'
let c = true + '10' // 'true10'(2) ==
100 == '100' //true
0 == '' //true
0 == false //true
false == '' //true
null == undefined //true 所以,当要进行明确判断的时候,都用===

(3)if和逻辑计算
truly变量 !!变量 === true的变量 - 两次取反为true的变量
falsely变量 !!变量 == false的变量 - l两次取反为false的变量

if判断的是turely变量和falsely变量
逻辑计算,也是判断的truely变量和falsely变量
1.3 面试题答案
(1)typeof可以判断哪些数据类型
typeof可以判断所有的值类型,可以判断是否为引用类型,是则返回object,也可以判断函数,是函数,返回function
(2)什么时候使用 == ? 什么时候使用 === ?
== 存在隐式数据类型转换,因此除了 == null之外,其他的都用 === 最好啦
(3)值类型和引用类型的区别是什么?
值类型和引用类型在存储和拷贝过程中都有区别
存储,值类型是直接将数据存储在栈中
引用类型是将数据的存储在堆中,将存储数据的地址值存储在栈中
拷贝过程:要完全拷贝,对于引用类型需要进行深拷贝
(4)手写深拷贝
function deepClone(obj) {
if(typeof obj !== 'object' || obj == null) {
return obj;
}
let result
if(obj instanceOf Arrary){
result = [];
}else {
result = {};
}
for(let key in obj){
if(obj.hasOwnProperty(key)){
result[key] = deepClone(obj[key])
}
}
return result;
}当然,深拷贝不止这一种方法,这里只是写一下通过递归进行深拷贝
2.原型和原型链
1.1 常见面试题
(1)如何准备判断一个变量是不是数组?
(2)class的原型本质,怎么理解?
1.2 知识点
1.2.1 class和继承
(1) class
class是一个面向对象的一个实现,class本质类似于一个模板,可以去构建(constructor)一些东西(方法,属性)
//定义类
class Student{
constructor(name, number){
this.name = name; //this - 指向实例对象
this.number = number;
}
sayHi() {
console.log(`姓名:${this.name},学号:${number}`);
}
}
通过类声明 多个对象/实例
const lixian = new Student('李现', 20);
console.log(lixian.name, lixian.number);
lixian.sayHi();
const li = new Student('李', 22);
console.log(li.name, li.number);
li.sayHi();(2)继承
继承,是定义一个父类(具有公共特性,如人,都有名字,都有身份证,都能吃饭等等),子类(具有自己的属性,比如学生,需要学习,有学号)继承父类。
继承主要是通过extends关键字,然后利用super继承属性
//定义父类
class People{
constructor(name, id){
this.name = name; //this - 指向实例对象
this.id= id;
}
eat() {
console.log(`${this.name}吃东西了`);
}
}
//子类继承并含有特有的属性和方法
//学生类
class Student extends People {
constructor(name, id, number){
super(name, id);
this.number = number;
}
study() {
console.log('study了')
}
}
//老师类
class Teacher extends People {
constructor(name, id, subject){
super(name, id);
this.subject= subject;
}
teach() {
console.log('上课了')
}
}
//实例化
const s1 = new Student('夏洛', 510524199710125420, 201544901114);
console.log(s1.name, s1.id, s1.number);
s1.eat();
s1.study();
注意的是,class只是es的一个规范,具体怎么实现还是引擎说了算
1.2.2 判断类型instanceof
instanceof是基于原型链进行判断的,判断是否属于一个类,是否属于一个构造函数
基本上面的例子
lixian instanceof People //true
s1 instanceof Student //true
s1 instanceof People //true
s1 instanceof Object //ture
怎么理解instanceof, a instanof b ,是看a是否是b构建出来的,当然,b也可以是构建a的父类(people),Object是所有类的父类,最顶层,是js引擎自己定义的,因此是否是ture,其实是基于原型链进行查找,就可以看下一个知识点 - 原型和原型链
1.2.3 原型和原型链
首先
typeof Student //function
typeof People //function因此,类其实是一个方法,只是是一个特殊的方法
原型和原型链,需要知道的是隐式原型和显示原型,因为之前也非常详细的写过了,所以就暂时不继续写了
关于细节,请看这个 - 》https://blog.csdn.net/qq_42625428/article/details/107806845
当然,对于懒的孩子,我直接将原型和原型链比较重要的几句话,粘贴过来了
1.每个函数(通常指构造函数,如Person)都有一个属性:prototype
2.prototype是一个对象, 里面有constructor , __proto__ 隐式原型
3.构造函数的原型对象指向当前构造函数 Person.prototype.constructor === Person
4.实例对象的隐式原型指向构造函数的显示原型
p1.__proto__ === Person.prototype
5.在构造函数显示原型中添加的方法,所有的实例对象共享
6.访问属性和方法,是基于原型连进行访问 在当前的实例对象去找--》构造函数的原型 ==》.... =》 Object的原型
如果感觉一看这几句话就懂了,就不需要再去看总结的原型和原型链了
这里是一个Student和实例,夏洛的一个图,看了原型和原型啦,在看这个图,就很清楚了
class Student{
constructor(name, age){
this.name = name;
this.age = age;
}
sayHi(){
console.log(this.name, this.age)
}
}
const xialuo = new Student('夏洛', 100)
xialuo.sayHi(); //'夏洛', 100
xialuo.__proto__.sayHi(); //undefined
可能会疑惑,实例对象xialuo执行sayHi有值,并且他就是通过隐式原型去找,为什么会是undefined,这里大家可以看下一个知识点this之后再回来理解
首先,类Student中sayHi的this,指向的实例对象也就是xialuo
因此很好理解xialuo.sayHi() => xialuo就是实例对象,可以理解为执行其实是,xialuo,__proto__.sayHi.call('xialuo')
而xialuo.__proto__ => 他并不是Student的实例对象
1.3 面试题答案
(1)如何准备判断一个变量是不是数组?
a instanceof Arrary
(2)class的原型本质,怎么理解?
class是es6的新特性之一,通过class关键字来定义一个类,可以理解class为一个模板,它的本质就是一个函数,可以通过constructor构造方法来构造一些属性,直接定义方法,定义子类进行继承。
3 作用域和闭包
3.1 常见面试题
(1)this在不同应用场景下如何取值
(2)手写bind函数
(3)闭包在实际开发总的应用场景
(4)创建10个a标签,点击弹出对应的序号
3.2 知识点
3.2.1 作用域和自由变量
作用域:变量的合法使用范围,如下面一个框就是一个作用域
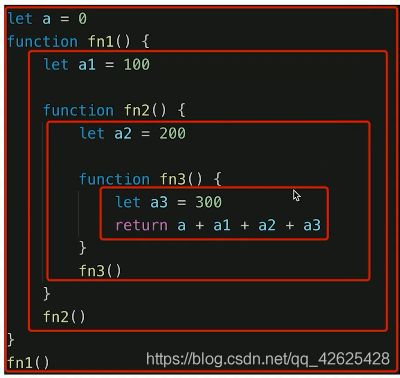
作用域分类 - 全局作用域,函数作用域,块级作用域(es6新增的)
全局作用域 - 整个js文件都可以使用的变量
函数作用域 - 在函数中使用的变量
块级作用域 - es6中的,一般是指一个{}区域内的变量,声明块级作用域的变量 - 用 let
自由变量:作用域内如果没有该变量,从下往上找,如a2,在函数作用域中没有a2,往上一级找,找到为止
3.2.2 闭包
作用域应用的特殊情况,一般有两种情况 - 函数作为参数被传递,函数作为返回值返回,简单解释闭包 - 嵌套函数使用外部的变量
直接看两个题
函数作为返回值
function create () {
let a = 100;
return function () {
console.log(a)
}
}
const fn = create()
const a = 200;
fn() 函数作为参数传递
function print(fn) {
const a = 200;
fn();
}
const a = 100;
function fn(){
console.log(a)
}
print(fn)注意 - 自由变量是在定义的位置向上级作用域查找,而不是在执行的位置,因此上面两道题都是100
如果没有搞懂闭包,可以看下这篇博客,详细的在了解一下闭包 https://blog.csdn.net/qq_42625428/article/details/84300823
3.2.3 this
this的指向在不同情况下,指代的不同,有下列几种情况
(1)作为普通函数
(2)使用call, apply , bind
(3)作为对象方法调用
(4)在class方法中调用
(5)箭头函数
this是什么值,是在函数执行的时候确定的
下面通过例子讲解上面5中情况
(1)作为普通函数,call.bind,apply
function fn(){
console.log(this)
}
fn(); //window
fn.call({x: 100}) //{x: 100}
const fn2 = fn.bind({x: 200})
fn2(); //{x: 200}定义的函数 - 在执行时候,this是指向window
而call,apply,bind是可以改变this指向,this指向调用的对象 ,他们的区别是什么?
apply和call基本是一致的,区别在与传参 - apply把需要传递给fn的参数放到一个数组(或者类数组)中传递进去,而call是单独传递的,第一个参数是更改this的对象
bind和他们的区别是 - bind需要自己调用一次,他是等待执行而不是立即执行,如上的例子,bind是返回了一个新函数,需要在执行新函数fn2
比如
function test(a,b){
console.log(this)
}
test.call({x:100}, 1 , 2)
test.apply({x: 100}, [1,2])(2)对象的this和箭头函数的this
对象中的this是指向对象本身的,而箭头函数的this是指向上一级作用域的this
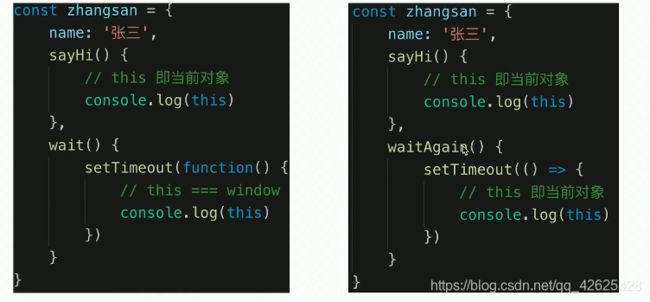
(3)类中的htis - 类中的this是指向实例对象

所以,到现在,记住了this的指向吗,不同情况的this指向不同,要根据确切的情况去判别
3.3 面试题答案
(1)this在不同应用场景下如何取值
作为普通函数 - 指向window
使用call, apply , bind - 指向传入的对象
作为对象方法调用 - 指向对象本身
在class方法中调用 - 指向实例对象
箭头函数 - 指向上级作用域的this
(2)手写bind函数
Function.prototype.bind1 = function() {
//将所有参数的伪数组变为真数组
const args = Array.prototype.slice.call(arguments);
//取出第一个数组
cosnt t = args.shift();
fn.bind()中的fn
const self = this;
//返回一个函数
return function () {
return self.apply(t, args)
}
}
(3)闭包在实际开发总的应用场景,举例说明
(1)隐藏数据
(2)简单做一个缓存工具 - 闭包会缓存值 - 具有特定功能的js文件,将所有的数据和功能封装在一个函数内部,只向外暴露n个对象或者方法
function toCache(){
const data = {} //定义的数据被隐藏,不被外界访问,只能在执行函数去保存修改值
return {
set: function(key, value){
data[key] = value;
},
get: function(key){
return date[key]
}
}
}
const s = toCache();
s.set('a', 100) //存储
s.get('a') //获取值(4)创建10个a标签,点击弹出对应的序号
for(let i = 0; i < 10; i++){
let a = document.createElement('a');
a.innerHTML = i + '
';
a.addEventListener('click', (e) => {
e.preventDefault();
alert(i)
})
document.boy.appendChild(a)
}为什么用var i不能,存在作用域为题,使用let是将每一个循环作为一个块级作用域,可以理解为保存了每个值。如果不是很能理解,可以查看闭包模块的知识点- https://blog.csdn.net/qq_42625428/article/details/84300823
4. 异步和单线程
4.1 常见面试题
(1)同步和异步的区别是什么?
(2手写Promise加载一张图片?
(3)前端使用异步的场景有哪些?
(4)题目 - 输出顺序
console.log(1)
setTimeout(funciton(){
console.log(2)
},1000)
console.log(3)
setTimeout(funciton(){
console.log(4)
},0)
console.log(5)4.2 知识点
4.2.1 单线程和异步
首先js是单线程语言,只能同时执行一件事。js和DOM渲染共用一个线程,因为js可以修改DOM结构,思考一下,如果不用一个线程,如果是在渲染DOM,但是js又修改了DOM那不是就没有意义了。那为什么需要异步??
遇到等待(网络请求,定时任务)不能卡住 - 需要异步 - 解决单线程问题,基于callback(在动动小脑瓜,如果是在请求一个图片或者其他资源的时候,浏览器卡住了,不能点击,不能做任何操作,是不是体验很差,而且等待时长多么的漫长,所以异步存在解决了这个问题)
毕竟等待的过程中,cpu是空闲状态,空闲不是浪费吗,所以异步多么的重要
异步 - 不会阻塞后面代码的执行
console.log(1)
setTimeout(() => {
consloe.log(2)
}, 1000)
consloe.log(3)setTimeout就是典型的异步执行,代码的输出顺序是132
同步- 阻塞后面的代码
consoe.log(1)
alert(2)
consloe.log(3)alert也是典型的同步操作,只有输出了2才能输出3,执行顺序123
4.2.2 应用场景
什么时候需要异步,也就是需要等待的情况
主要是 - 网络请求,像ajax请求
- 定时任务,像setTimeout
4.2.3 回调地狱(callback hell) 和 Promise
回调地狱也是之前已经总结过的,所以不太懂的可以看 https://blog.csdn.net/qq_42625428/article/details/103637357
总的来说 - 回调地狱就是出现了嵌套的网络请求,而Promise的出现解决了这一问题
关于promise没有进行详细的解释,需要掌握它的用法
4.3 面试题答案
(1)同步和异步的区别是什么?
异步不会阻塞代码的执行,同步会阻塞代码的执行
(2手写Promise加载一张图片?
这里的例子写的是加载两个图片哦
function loadImg(srv){
返回一个promise,promise参数是一个函数,函数有两个参数,resolve,reject,也是一个函数
return new Pomise((resolve, reject) => {
const img = document.createElement('img')
img.onload = () => {
resolve(img) //resolve的数据用then接收
}
img.onerror = () => {
reject('加载失败') //用catch接收
}
img.src = src
})
}
loadImg('图片地址').then((img) => {
console.log(img)
return img //return的数据,用then继续接收
}).then((img) => {
consloe.log(img)
return loadImg('图片地址') //return 的是promise对象
}).then((img) =>{
consloe.log(img) //img是加载图片的resolve的数据
}).catch((err) => {
console.log(err)
})
(3)前端使用异步的场景有哪些?
网络请求,像ajax请求
- 定时任务,像setTimeout
(4)题目 - 输出顺序

输入顺序 - 13542
js Web Api
js的规范是ECMA标准规定的,而Web API是操作网页api是W3C规定的
1. DOM操作 - Document Object Model(文档对象模型)
现在的框架,vue,react等其实已经封装了DOM操作,所以在使用框架的时候,其实很多都不需要在自己去操作DOM了,但是作为一个前端工程师,其实DOM操作是最基本的。
1.1 常见面试题
(1)DOM是哪种数据结构
(2)DOM操作的常见api
(3)属性attr和property的区别
(4)一次性插入多个DOM节点,考虑一下性能
1.2 知识点
1.2.1 DOM的本质
介绍之前,先了解另外一种mxl语言,xml也是由标签组成,与html不同的是,它的标签是可以自定义的,而html的标签必须按照标准写。
那什么是DOM? DOM的本质是HTML语言解析的一棵树。
1.2.2 DOM节点操作
(1)获取节点
document.getElementById('id名')
document.getElementsByTagName('标签名')
document.getElementsByClassName('类名')
document.querySelector('选择器') //返回第一个满足css选择器条件的元素
document.querySelectorAll('选择器') //返回所有满足css选择器条件的元素注意的是,除了id名和querySelector以外,其他的都是返回的一个满足条件的元素的伪数组
(2)修改节点
①property - 一种通过js进行修改获取属性的一种形式
const p = document.querySelector('p')
p.style.width = '100px'; //设置属性
cosole.log(p.style.width) //获取属性②attribute - 利用api直接修改获取修改属性
const p = document.getElementById('p')
p.setAtrribute('data-name', 'name') //sss
p.setAtrribute('style', 'font-size: 15px')
console.log(p.getAtrribute('data-name'))③区别
property修改的并不会体现在HTML结构中,attribute会体现在HTML结构中,值得注意的是,两者都会引起DOM的重新渲染
对DOM节点的操作的属性有很多,上面只是讲解了常用部分,更多可以了解官方api - https://www.runoob.com/jsref/dom-obj-all.html
1.2.3 DOM结构操作
(1)新增/插入节点 - appendChild
const div = document.getElementById('div')
const p = document.createElement("p") //创建p
p.innerHTML = 'this is p'
div.appendChild(p) //将p插入div,注意如果是对现有的元素进行append会产生移动(2)获取子节点,父节点 - parentNode, ChildNodes
const p = document.getElmentById('p')
cosole.log(p.parentNode) //获取父节点
const div = document.getElementBy('div')
console.log(div.childNodes) //获取子节点这里需要注意的是,获取子节点的时候空格换行,文本节点
(3)删除节点 - removeChild
const div = document.getElementById('div')
const p = document.getElementById('p')
div.removeChild(p)同理,DOM的增删改查有很多种方法,这里只是列举了一些常见的方法,如果想要了解更多,可以查看文档api - https://www.runoob.com/jsref/dom-obj-attributes.html
1.2.4 DOM的性能
DOM操作占用的cpu很多,频繁操作很容易卡顿。因此在vue,react这些框架中,其实就有自己的diff算法,去更新DOM,提高性能。
提升DOM的性能,我们能做些什么?
对DOM查询做缓存,将频繁操作改为一次性操作(插入多次,改成插入一次等)
1.3 面试题答案
(1)DOM是哪种数据结构
DOM是一种数的结构
(2)DOM操作的常见api
参考上面1.2.3
(3)属性attr和property的区别
property修改的并不会体现在HTML结构中,attribute会体现在HTML结构中,值得注意的是,两者都会引起DOM的重新渲染
(4)一次性插入多个DOM节点,考虑一下性能
const frag = document.createDocumentFragment() //创建文档碎片,其实是一个虚拟DOM
const div = document.getElementById('div')
for(let i = 0; i < 10; i++){
const p = document.createElement('p')
p.innerHtml = 'this p
'
frag.appendChild(p)
}
div.appendChild(frag) //真正插入真实DOM
2 .BOM操作
2.1 常见面试题
(1)如何识别浏览器的类型
(2)分析拆解url的各个部分
2.2 知识点
2.2.1 navigator
查看当前浏览器的信息
navigator.userAgent谷歌浏览器的信息
![]()
2.2.2 screen
屏幕的高度,宽度
console.log(screen.width)
console.log(screen.height)2.2.3 location
location有很多网址信息,可以去选择自己想要的

2.2.4 history
history主要是对方法的使用,前进啊,后退啊,history.back()等等

3.1 面试题答案
(1)如何识别浏览器的类型
navigator.userAgent
(2)分析拆解url的各个部分
location
3.事件绑定
事件绑定的一些api https://www.runoob.com/jsref/dom-obj-event.html
3.1 常见面试题
(1)编写一个通用的事件监听函数
(2)描述实践冒泡的流程
(3)无限下拉的图片列表,如何监听每个图片的点击?
3.2 知识点
3.2.1 事件绑定
let box = document.getElementById('box')
//监听事件绑定
box.addEventListener('click', () => {})
//直接绑定
box.onclick = function(){}3.2.2 事件冒泡
事件冒泡:子级的事件会触发父级的(假设点击事件,父级也有点击事件,则会触发自己的点击事件,也会触发父亲的点击事件)
举个栗子
//结构
子元素
//js代码
let father = document.getElementById('father')
let child = document.getElementById('child')
father.addEventListener('click', () => {
cosole.log('father')
})
child .addEventListener('click', () => {
cosole.log('child')
})当点击p,会打印child,father,这就是事件冒泡
事件冒泡的存在会在一些场景下影响原有逻辑,所以常常我们会阻止事件冒泡 - e.stopPropagation()
child .addEventListener('click', (e) => {
//阻止事件冒泡
e.stopPropagation()
cosole.log('child')
})阻止事件冒泡后,只会打印child
3.2.3 事件代理
一般是在瀑布流的时候,将子元素的事件绑定在父元素身上
let box = document.getElementById("box")
box.addEventListener('cilck', e => {
e.prevenDfault() //阻止默认行为
if(e.target.nodeName === A){
alert(e.target.innerHTML)
}
})事件代理的好处是什么 - 代码简洁,减少浏览器内存占用(只绑定一次事件)
其实在jquery中,想想是不是对未来元素绑定事件也是绑定在父元素中的~
3.3 面试题答案
(1)编写一个通用的事件监听函数
//满足普通绑定和事件代理绑定,并且this永远指向触发元素
function bindEvent(el, type, selector, fn){
if(fn == null){
fn = selector
selector = null
}
el.addEventListener(type, event => {
const target = event.target
if(selector){
//触发元素是否与选择器相同,代理绑定
if(target.matches(selecotr)){
fn.call(target, event)
}
}else {
fn.call(target, event)
}
})
}(2)描述实践冒泡的流程
事件冒泡是基于DOM的树形结构,事件会顺着触发元素往上冒泡
(3)无限下拉的图片列表,如何监听每个图片的点击?
利用事件代理-如上例子
4.ajax
4.1 常见面试题
(1) 手写一个简易的ajax
(2) 跨域的常见方法
4.2 知识点
关于ajax的知识点,之前写过一篇基础使用和封装以及jquery的ajax: https://blog.csdn.net/qq_42625428/article/details/103214802
4.2.1 XMLHttpRequest
这里写一个基本的ajax的请求
get
//创建一个实例
const xhr = new XMLHttpRequerst()
//写入请求地址
xhr.open('GET', 'URL地址', true) //异步请求,false是同步
//监听状态
xhr.onreadystatechange = function() {
if(xhr.readyState === 4){
if(xhr.status === 200){
console.log(xhr.responseText)
}
}
}
xhr.send()post
var xhr = new XMLHttpRequest();
xhr.open("post",'./server/mydate.json');
xhr.setRequestHeader('Content-Typ','application/x-www-form-urlencoded'); //设置请求头
xhr.send('username=name&age=12'); //传入参数
xhr.onreadystatechange = function(){
if(xhr.readyState === 4 && xhr.status === 200){
console.log(xhr.responseText);
}
}区别:
1.post 比 get在传递的时候多了一个头部结构
2.传递参数的方式不同 get: 传递在地址的后面 www.baidu.com?参数=值&参数=值
post: 传递在send()方法的里面 xhr.send('参数=值&参数=值')
3.get因为是地址传递 - 铭文传递 -不安全 - 传递的数据量小
4.2.2 状态码
2xx - 表示成功处理请求,如200
3xx - 需要重定向 301 302 304
4xx - 客户端请求错误,如404 403
5xx - 服务器端错误 500 501
4.2.3 跨域 - 同源策略和其解决方案
跨域的知识点,之前总结了一篇超级详细的博客,所以就不重复写了:https://blog.csdn.net/qq_42625428/article/details/108099755
4.2.4 ajax的工具
工具都是直接用就行了,还是比较简单,只是在这总结一下工具,具体的可以直接看官网
(1)jquery的ajax
(2)fetch -
官网: https://developer.mozilla.org/zh-CN/docs/Web/API/Fetch_API/Using_Fetch

(3)axios
官网 - http://www.axios-js.com/zh-cn/docs/
对axios的总结 - https://blog.csdn.net/qq_42625428/article/details/103870313
4.3 面试题答案
(1) 手写一个简易的ajax
let obj = {
url: './server/mydate.json',
type: 'get',
data: {
name: 'aaa',
age: 18
}
}
//结合一下promise
function ajax(obj) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequrest()
//初始化参数
let params = '';
if (obj.data != ''){
for (key in obj.data) {
params += `${key}=${obj.data[key]}&`;
}
params = params.substring(0, params.length - 1);
}
//接收传递类型并转为小写
let type = obj.type.toLowerCase();
xhr.open(type ,type == 'get' ? `${obj.url}?${params}` : obj.url);
// post - 设置请求头
if (type === 'post') {
xhr.setRequestHeader('Content-Typ', 'application/x-www-form-urlencoded');
}
type == 'get' ? xhr.send() : xhr.send(params);
xhr.onreadystatechange = function () {
if (xhr.readyState === 4 && xhr.status === 200) {
let result = xhr.responseText;
resolve(result)
}else {
reject('错误')
}
}
})
}
ajax(obj).then(res => {}).catch(err => {})(2) 跨域的常见方法
jsonp,cors,proxy等等
5.存储
5.1 常见面试题
(1)描述一下cookie,localStorage,sessionStorage的区别
5.2 知识点
web端的存储技术的总结 - https://blog.csdn.net/qq_42625428/article/details/103264536
5.2.1 cookie
本身是用于浏览器和server通讯,是被借用到本地存储。现在一般是用于身份标识
前端设置修改:
document.cookie = "a=200;b=100"每一次是追加,不是覆盖,每次刷新,cookie是赋值后,不断刷新是继续存在的,因此可以利用来做本地存储
cookie只能存储4kb,并且是http请求的时候,cookie都会发送到服务端,增加了请求数据量
随意存储还是尽量不要用cookie
5.2.2 localStorage和sessionStorage
.这两个h5专门为存储设计的,最大可以存储5M
设置和获取
localStorage.setItem(key,value)
lcoalSotrage.getItem(key)
sessionStorage.setItem(key,value)
sessionSotrage.getItem(key)区别也很简单 - sessionStorage是临时存储,关闭浏览器清空
- localStorage是永久存储,只能手动删除
5.3 面试题答案
(1)描述一下cookie,localStorage,sessionStorage的区别?
容量: cookie只有4kb, 临时存储和永久存储5M
cookie会被http请求发送到后端
临时存储,关闭浏览器清空,localStorage只能手动清空
3.浏览器相关
前端的运行环境 - 浏览器(server端有nodejs) - 下载网页代码,渲染页面,并在次期间执行js,要保证代码在浏览器种稳定且高效
1 页面加载过程
1.1 常见面试题
(1)从输入url到渲染出页面的整个过程
(2)window.onload和DOMContentLoad的区别
1.2 知识点
1.2.1 加载资源的形式
前端加载资源 - 一般有htmld代码,媒体文件(图片,视频等等),js,css
1.2.2 加载资源的过程
DNS解析: 域名 -》 IP地址 (将域名转换为ip地址)
浏览器根据IP地址向服务器发起http服务(操作系统在发,三次握手等等)
服务器接收,处理http请求,并返回给浏览器
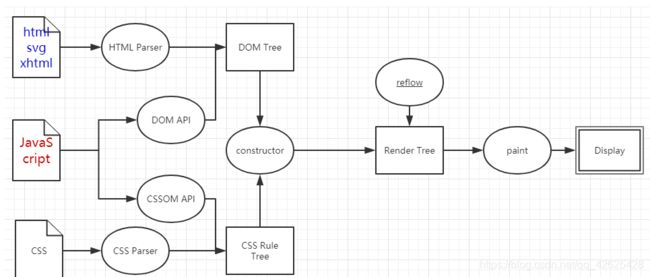
1.2.3 渲染页面的过程
根据html代码生成DOM Tree
根据css生成CSSOM(层叠样式表对象模型)
将DOM Tree 和 cssOM整合成renderDOM
根据Render Tree 渲染页面
遇到script标签,暂停渲染,优先加载并执行js代码(浏览器是单线程的 .js代码可能会改变css)
直到把Render Tree渲染完成
1.3 面试题答案
(1)从输入url到渲染出页面的整个过程?
①dns解析域名为ip地址
②浏览器根据ip地址向服务器发起http请求
③建立连接,服务器处理请求并返回
④浏览器对返回解析,解析DOM树,解析css,构建render Tree
⑤遇到script标签,暂停渲染加载执行js,在进行渲染,直至全部渲染完成
(2)window.onload和DOMContentLoad的区别?
window,.onload是资源(图片等)全部加载完成才会执行
DOMContentLoad是DOM加载结束就执行
2 安全
常见的web前端攻击方式有哪些?
2.1 XSS跨站请求攻击
什么是XSS攻击?
xss攻击通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。
举个栗子一篇博客网站,发表了一篇博客,其中嵌入了