【Python pyppeteer爬虫实战】抓取纵横小说图书信息,并存储到MySQL数据库
写在前面
本篇博客只是为练习pyppeteer的用法,其中的实践案例用其他的更简单方法也可以实现。
最近也是看完了崔庆才爬虫52讲里面pyppeteer的部分,就想着实战演练一遍(主要是里面的案例无法使用,哭唧唧),找了一下经常爬取的网站,例如淘宝,知网什么的,但是这些网站都需要登录,难度偏大一点,就给否决掉了,最后选到了纵横小说排行榜这个网站,因为这个网站没有什么反爬,不需要登录而且比较符合初始页加详情页这样常用的抓取数据的方法。
网站分析
初始列表页的url
![]()
翻页观察
![]()
多翻几个页面之后,发现初始页面的url规律十分明显
http://www.zongheng.com/rank/details.html?rt=1&d=1&p={page}
详情页面的url
![]()
随便多开几个详情页,规律也都是一样的
http://book.zongheng.com/book/{id}.html
实现思路
构造url列表请求初始页面,获取到详情页面的id,再请求详情页面,拿到想要的数据即可。
因为我们这边用的是pyppeteer模拟浏览器进行请求的,没有必要抓包分析了,直接分析elements拿到详情页面的url即可。

通过简单分析过后,很容易就可以拿到详情页面的url。
之后我们请求详情页拿到想要的数据,因为这只是练习一下pyppeteer的使用,随便抓点数据即可。
获取这个些数据的方法也很简单,直接分析elements就可以了,在这里我就不详细的分析了,最后再把数据存储到MySQL就可以了。
代码实现
附带上源代码,注释很清晰,和selenium做了比较,方便对比学习。
from pyppeteer import launch
import asyncio
import logging
from pyppeteer.errors import TimeoutError
import pymysql
logging.basicConfig(level=logging.INFO,format="%(asctime)s-%(levelname)s:%(message)s")
INDEX_URL = "http://www.zongheng.com/rank/details.html?rt=1&d=1&p={page}"
TIMEOUT = 10
TOTAL_PAGE = 10
WINDOW_WIDTH, WINDOW_HEIGHT = 1366,768
HEADLESS = False
browser, tab = None, None
# 初始化数据库
db = pymysql.connect(host='localhost', user='root', database='zongheng_top100', autocommit=True)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor.execute("DROP TABLE IF EXISTS DATA")
# 使用预处理语句创建表
sql = """CREATE TABLE DATA (
NAME CHAR(20) NOT NULL,
AU_NAME CHAR(20),
BOOK_LABEL CHAR(100),
NUM CHAR(20),
RECOMMEND CHAR(20),
TOTAL_HITS CHAR(20),
RECOMMEND_WEEK CHAR(20),
BRIEF_INTRODUCTION VARCHAR(2000),
URL CHAR(50)
)"""
cursor.execute(sql)
# 初始化pyppeteer
async def init():
global browser, tab
# browser对象是用来定义浏览器窗口 用法相当于selenium里面的option
browser = await launch(headless=HEADLESS,args=['--disable-infobars',f'--window-size={WINDOW_WIDTH},{WINDOW_HEIGHT}'])
# 开启一个页面
tab = await browser.newPage()
await tab.setViewport({
'width':WINDOW_WIDTH,'height':WINDOW_HEIGHT})
# 定义通用的爬取方法
async def scrape_page(url,selector):
logging.info('scraping %s', url)
try:
# tab.goto(url)相当于selenium driver.get(url)
await tab.goto(url)
# waitForSelector相当于selenium里面显性等待
await tab.waitForSelector(selector,option={
'timeout': TIMEOUT*10000
})
except TimeoutError:
logging.error('error occurred while scraping %s', url, exc_info=True)
# 定义爬取列表页的方法
async def scrape_index(page):
url = INDEX_URL.format(page=page)
await scrape_page(url, '.rankpage_box')
# 定义解析列表页的方法
async def parse_index():
"""
querySelectorAllEval方法接受两个参数
第一个参数是selector,代表要选择的节点对应的CSS选择器
第二个参数pageFunction,代表要执行的JavaScript方法
"""
# querySelectorAllEval相当与find_elements_by_
# nodes=>nodes.map(node=>node.href)相当与selenium里面遍历elements并执行.get_attribute('href')方法
return await tab.querySelectorAllEval('.rank_d_book_img a','nodes=>nodes.map(node=>node.href)')
# 定义访问详情页的方法
async def scrape_detail(url):
await scrape_page(url, '.book-top')
# 解析详情页拿到数据
async def parse_detail():
url = tab.url
# node=>node.innerText相当于selenium里面的element.text
name = await tab.querySelectorEval('.book-name','node=>node.innerText')
au_name = await tab.querySelectorEval('.au-name a','node=>node.innerText')
# nodes=>nodes.map(node=>node.innerText)相当与selenium里面遍历elements并执行.text方法
book_label = ",".join(await tab.querySelectorAllEval('.book-label a',"nodes=>nodes.map(node=>node.innerText)"))
num = await tab.querySelectorEval('.nums span:nth-of-type(1) i','node=>node.innerText')
recommend = await tab.querySelectorEval('.nums span:nth-of-type(2) i','node=>node.innerText')
total_hits = await tab.querySelectorEval('.nums span:nth-of-type(3) i','node=>node.innerText')
recommend_week = await tab.querySelectorEval('.nums span:nth-of-type(4) i','node=>node.innerText')
brief_introduction = await tab.querySelectorEval('.book-dec p','node=>node.innerText')
data = (name,au_name,book_label,num,recommend,total_hits,recommend_week,brief_introduction,url)
return data
# 存储数据到mysql
async def save_data(detail_data):
sql = "INSERT INTO DATA" \
"(NAME, AU_NAME, BOOK_LABEL, NUM, RECOMMEND, TOTAL_HITS, RECOMMEND_WEEK, BRIEF_INTRODUCTION, URL) " \
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
# 执行sql语句
cursor.execute(sql,detail_data)
# 执行sql语句
db.commit()
async def main():
await init()
try:
for page in range(1,TOTAL_PAGE+1):
await scrape_index(page)
detail_urls = await parse_index()
logging.info('detail_urls %s',detail_urls)
for detail_url in detail_urls:
await scrape_detail(detail_url)
detail_data = await parse_detail()
logging.info('data %s',detail_data)
await save_data(detail_data)
db.close()
finally:
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
再添加一点pyppeteer常用的方法:
鼠标点击操作
# 第一个参数表示选择器,第二个参数操作的方法
await page.click('.item .name',options={
'button':'right',
'clickCount':1, # 1or2 单击或双击
'delay':3000, # 毫秒
})
文本输入操作
# 第一个参数选择器,第二个参数输入的文字
await page.type('#q','iPad')
想要了解更多的操作直接去看官方文档吧
总结
pyppeteer可以实现异步爬取,速度上比selenium要快上很多,而且使用pyppeteer没有必要专门下载chrome浏览器和chromedriver驱动,在某些特定的网站确实要比selenium好用,但pyppeteer提取数据,鼠标操作等方法过于复杂,不如selenium简单,不便于记忆,而且pyppeteer可以实现的方法selenium基本都可以实现。总之pyppeteer可以学习,但没必要死记硬背其中的方法,用到的时候直接翻阅相关文档即可。
附上
运行过程
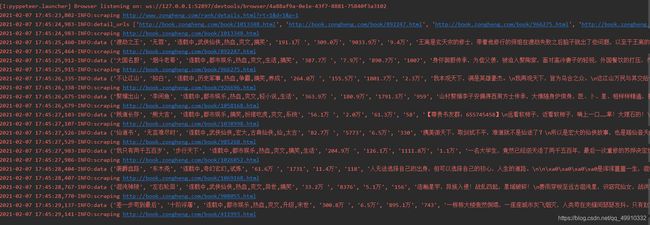
速度确实要快很多,和requests直接爬取的速度基本一样了!
PS:第一次运行pyppeteer程序会下载一个Chromium浏览器,速度慢一点,之后运行就不需要了,速度会快很多。