数据在内存中的存储(详细版)
数据在内存中的存储
- 一、整型在内存中的存储
-
- 1、字节序
-
- (1)小端字节序
- (2)大端字节序
- (3)写一个程序判断是否为大端字节序
- 2、原码补码反码
-
- (1)补码
- (2)补码的意义
- 二、浮点型在内存中的存储
-
- 1、浮点型
- 2、浮点数的比较
一、整型在内存中的存储
(32位系统)
在VS2013中,使用调试->窗口->内存,来观察内存的具体情况。
让我们通过内存窗口来看看整型在内存中的存储,
定义一个整形变量int a= 10;。
注意:可以在地址栏中使用&来找到目标变量的内存情况。
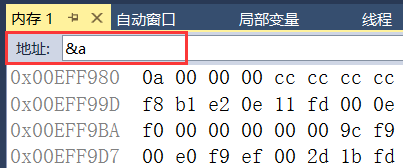
a的地址:0x00EFF980
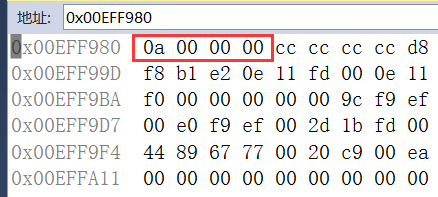
int型在内存中是以4个字节为单位存储的,内存中用16进制表示。可以看到a的值为0a(16进制),换算成十进制就是10。
1、字节序
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
(1)小端字节序
小端(存储)模式:
数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地址中。
我们输入一个十六进制数,来观察一下在内存中的情况
int a = 0x11223344
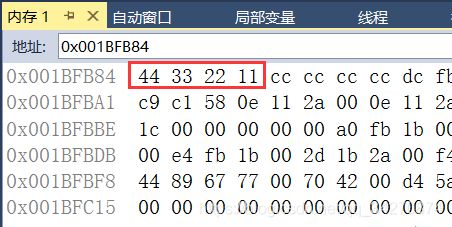 可以看到高位11保存在内存的高地址中,低位44保存在内存的低地址。
可以看到高位11保存在内存的高地址中,低位44保存在内存的低地址。
(2)大端字节序
大端(存储)模式:
数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
int a = 0x11223344;
以上例子在大端字节序中的存储是这样的:
 在日常生活中,大部分的pc都是使用小端字节序。
在日常生活中,大部分的pc都是使用小端字节序。
(3)写一个程序判断是否为大端字节序
规定:返回0不是,返回1是。
#include 2、原码补码反码
计算机中的符号数有三种表示方法即原码、补码、反码。正数的原、反、补码都相同。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位三种表示方法各不相同。
原码:直接将二进制按照正负数的形式翻译成二进制就可以。
反码:将原码的符号位不变,其他位依次按位取反就可以得到了。
补码:反码+1就得到补码。
(1)补码
对于整形来说:数据存放内存中其实存放的是补码。
-10在内存中的存储:
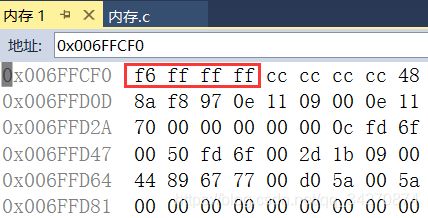 在内存中我们可以看到在内存的存储的值为 f6 ff ff ff 。
在内存中我们可以看到在内存的存储的值为 f6 ff ff ff 。
在上面已经为大家介绍了小端字节序,因为我的计算机是小端字节序。
所以它的值就为ff ff ff f6。
用二进制的方式表示:
1111 1111 1111 1111 1111 1111 1111 0110
-10的原码:
1000 0000 0000 0000 0000 0000 0000 1010
-10的反码:
1111 1111 1111 1111 1111 1111 1111 0101
-10的补码(反码+1):
1111 1111 1111 1111 1111 1111 1111 0110
可以看到和上面ff ff ff f6转换成二进制的结果相同。
(2)补码的意义
为什么对于整形来说,数据存放内存中其实存放的是补码呢?
数据存放内存中其实存放的是补码在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
补码存在的意义就是让硬件实现简单。
比如:把负数按补码表示,可以统一±为+。
例子:
1-10=1+(-10)


二、浮点型在内存中的存储
1、浮点型
根据国际标准IEEE(电气和电子工程协会),任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是101.0,相当于1.01×2^2。 那么,按照上面V的格式,可以得出s=0,M=1.01,E=2。
十进制的-5.0,写成二进制是-101.0,相当于-1.01×2^2。 那么,s=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。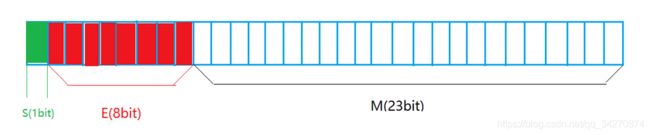
对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。

M占用的比特位越多,数据精度越高。
E占用的比特位越多,数据范围越大。
所以在实际开发中使用double较多。
2、浮点数的比较
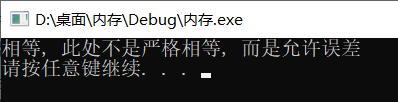
使用这种方式来存储的时候,会带来一个很大的问题,保存的小数往往不是一个精确值,而只是一个近似值。
示例:
#include 实际上11.0/3.0*3.0肯定等于11.0。
但是我们看看运行结果:
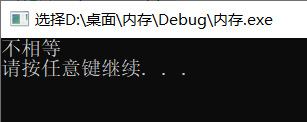 所以,浮点数在内存中存储的时候,很多时候是有误差的。
所以,浮点数在内存中存储的时候,很多时候是有误差的。
正确的比较方法:
使用做差的方法,然后判断差值是不是在允许误差范围内,如果在的话,就相等。
#include