【路径规划】基于狼群算法之三维路径规划matlab源码
1、狼群算法中的狼种类分为以下几种:
头狼、探狼、猛狼。
2、猎物分配规则:论功行赏,先强后弱。
3、狼群算法的主体构成:探狼游走、头狼召唤、猛狼围攻3种智能行为,“胜者为王”的头狼角逐规则和“优胜劣汰”的狼群更新规则。
Step1:在解空间中随机初始化狼群的空间坐标,依据目标函数值的大小角逐出人工头狼。
Step2:探狼开始随机游走搜索猎物,若发现某个位置的目标函数值大于头狼的目标函数值,将更新头狼位置,同时头狼发出召唤行为;若未发现,探狼继续游走直到达到最大游走次数,头狼在原本的位置发出召唤行为。
Step3:听到头狼召唤的猛狼以较大的步长快速向头狼奔袭,若奔袭途中猛狼的目标函数值大于头狼的目标函数值,则将对头狼位置进行更新;否则,猛狼将继续奔袭直到进入围攻范围。
Step4:靠近头狼的猛狼将联合探狼对猎物(把头狼位置视为猎物)进行围捕,围捕过程中若其他人工狼的目标函数值大于头狼的目标函数值,则对头狼位置进行更新,直到捕获猎物。
Step5:淘汰狼群中目标函数值较小的人工狼,并在解空间中随机生成新的人工狼,实现狼群的更新。
Step6:最后判断头狼的目标函数值是否达到精度要求或算法是否达到最大迭代次数。
4、人工狼群算法的若干规则:
(1)头狼产生规则
初始解空间中,具有最优目标函数值的人工狼即为头狼;在迭代过程中,将每次迭代后最优狼的目标函数值与前一代中头狼的值进行比较,若更优则对头狼位置进行更新,若此时存在多匹的情况,则随机选一匹成为头狼。头狼不执行3种智能行为,直接进入迭代,直到被其他更强的人工狼代替。
(2)游走行为
除头狼外最佳的S_sum匹人工狼视为探狼,S_sum随机取[n/α+1,n/α]之间的整数,α为探狼比例因子。
计算探狼 的目标函数值
的目标函数值 ,若大于头狼的目标函数值
,若大于头狼的目标函数值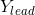 ,则更新头狼,=,探狼替代头狼发起召唤;若>,则探狼向h个方向分别前进一步(游走步长为
,则更新头狼,=,探狼替代头狼发起召唤;若>,则探狼向h个方向分别前进一步(游走步长为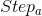 ),记录没前进一步后的函数数值,那么向第p(p=1,2,...,h)个方向前进后探狼所处的位置为
),记录没前进一步后的函数数值,那么向第p(p=1,2,...,h)个方向前进后探狼所处的位置为
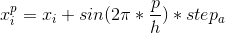 (1)
(1)
此时,探狼所在位置的函数值为 ,选择函数值最大且大于当前函数值的方向前进一步,更新探狼的状态
,选择函数值最大且大于当前函数值的方向前进一步,更新探狼的状态 ,重复以上的游走行为直到某匹探狼的函数值>或游走次数达到最大游走次数
,重复以上的游走行为直到某匹探狼的函数值>或游走次数达到最大游走次数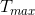 。
。
由于每匹探狼的猎物搜寻方式存在差异,因此 的取值不同,实际中可取
的取值不同,实际中可取![[h_{min},h_{max}]](http://img.e-com-net.com/image/info8/2c0100e373424c40a7e44eeabf12d8e2.gif) 之间的随机整数,越大探狼搜寻得越精细但同时速度也相对较慢。
之间的随机整数,越大探狼搜寻得越精细但同时速度也相对较慢。
(3)召唤行为
头狼召集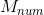 匹猛狼向头狼所在位置迅速靠拢,其中
匹猛狼向头狼所在位置迅速靠拢,其中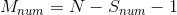 ;猛狼以相对较大的奔袭步长
;猛狼以相对较大的奔袭步长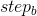 快速逼近头狼所在位置。
快速逼近头狼所在位置。
猛狼第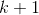 次迭代时,所处的位置为
次迭代时,所处的位置为
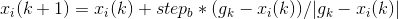 (2)
(2)
式中,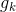 为第k代头狼的位置。式(2)由2部分组成,前者为人工狼的当前位置,后者表示人工狼逐渐向头狼位置聚集的趋势。
为第k代头狼的位置。式(2)由2部分组成,前者为人工狼的当前位置,后者表示人工狼逐渐向头狼位置聚集的趋势。
奔袭途中,若猛狼的函数值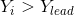 ,则
,则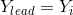 ,该猛狼转化为头狼并发起召唤行为;若
,该猛狼转化为头狼并发起召唤行为;若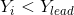 ,则猛狼继续奔袭直到其与头狼
,则猛狼继续奔袭直到其与头狼 之间的距离
之间的距离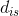 小于
小于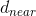 时转入围攻行为。
时转入围攻行为。
设待寻优的变量取值范围为[lb,ub],则判定距离可由式(3)估计得到
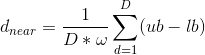 (3)
(3)
式中, 为距离判定因子,增大会加速算法收敛,但过大会使得人工狼很难进入围攻行为。
为距离判定因子,增大会加速算法收敛,但过大会使得人工狼很难进入围攻行为。
(4)围攻行为
经过奔袭的猛狼距离猎物较近,此时猛狼要联合探狼对猎物进行围攻,并捕获。这里将离猎物最近的狼,即头狼的位置视为猎物移动的位置。具体地,对于第k代狼群,设猎物的位置为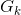 ,则狼群的围攻行为可用方程(4)表示:
,则狼群的围攻行为可用方程(4)表示:
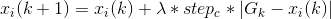 (4)
(4)
式中,为[]间均匀分布的随机数;为人工狼执行围攻行为时的攻击步长。若实施围攻行为后人工狼感知到的猎物气味儿浓度大于其原位置状态所感知的猎物气味浓度,若不然,人工狼位置不变。
5、人工狼群算法的具体步骤:
step1 数值初始化;
step2 选取头狼以及S_num匹人工狼为探狼并执行游走行为,直到某只探狼侦察到底额猎物气味浓度大于头狼所感知的猎物气味浓度或达到最大游走次数,结转step3;
step3 人工猛狼根据式(2)向猎物奔袭,若途中猛狼感知的猎物气味浓度,则,替代头狼发起召唤行为;若,则人工猛狼继续奔袭直至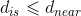 ,结转step4;
,结转step4;
step4 按式(4)对参与围攻行为的人工狼的位置进行更新,执行围攻行为;
step5 按“胜者为王”的头狼产生规则对头狼位置进行更新;再按照“强者生存”的狼群更新机制进行群体更新;
step6 判断是否达到优化精度要求或最大迭代次数,否则,结转到step2。
%% 清空环境
clc
clear all
close all
%% 数据初始化
%下载数据
load HeightData
% HeightData=HeightData';
%网格划分
LevelGrid=10;
PortGrid=21;
%起点终点网格点
starty=6;starth=1;
endy=8;endh=21;
m=1;
%算法参数
PopNumber=10; %种群个数
BestFitness=[]; %最佳个体
iter=100;
%初始信息素
pheromone=ones(21,21,21);
dim=PortGrid*2;
Max_iter=100;
ub=PortGrid;
lb=1;
% initialize alpha, beta, and delta_pos
Alpha_pos=zeros(1,dim);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,dim);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,dim);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the path of search agents
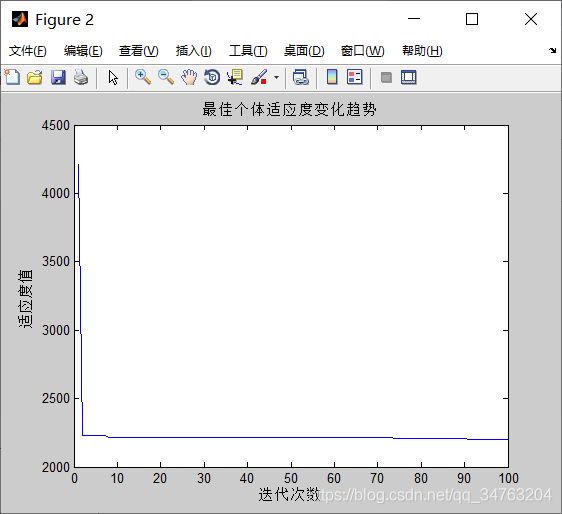
Convergence_curve=zeros(1,Max_iter);
l=0;% Loop counter
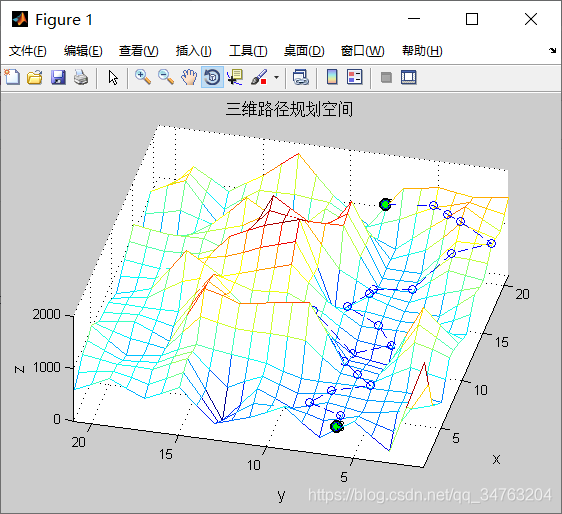
%% 初始搜索路径
[path,pheromone]=searchpath(PopNumber,LevelGrid,PortGrid,pheromone, ...
HeightData,starty,starth,endy,endh);
fitness=CacuFit(path); %适应度计算
[bestfitness,bestindex]=min(fitness); %最佳适应度
bestpath=path(bestindex,:); %最佳路径
BestFitness=[BestFitness;bestfitness]; %适应度值记录
l=0;% Loop counter
% Main loop
while lub;
Flag4lb=path(i,:)Alpha_score && fitness