 【摘要】本文将介绍如何维护Ansible的Inventory,来管理不同业务的不同机器;如何使用Ansible的一些常用组件,完成一些基本的自动化运维工作;如何编写和使用Playbook,来完成复杂环境下的自动化运维工作;如何利用Facts组件来采集被管客户端的设备信息,来实现配置管理系统(CMDB)的自动采集能力等等。
【摘要】本文将介绍如何维护Ansible的Inventory,来管理不同业务的不同机器;如何使用Ansible的一些常用组件,完成一些基本的自动化运维工作;如何编写和使用Playbook,来完成复杂环境下的自动化运维工作;如何利用Facts组件来采集被管客户端的设备信息,来实现配置管理系统(CMDB)的自动采集能力等等。
转自公众号@TWT社区;作者:邓毓。
1、Ansible Inventory维护
- Inventory文件
在日常维护中,Ansible通过Inventory(可管理的主机集合),对远端服务器或者主机进行统一操作和管理。在Ansible中,描述主机的默认方法是将他们列在一个文本文件中,这个文件称为Inventory文件,默认的路径和文件为:/etc/ansible/hosts,可以通过ANSIBLE_HOSTS环境变量来指定,也可以在ansible.cfg文件中通过inventory参数指定,或者在运行ansible和ansible-playbook的时候使用-i参数来临时指定。
下面举例说明,如何在inventory组件的/etc/ansible/hosts文件中定义主机和主机组:

第一行定义了一个主机X.X.X.100,并使用inventory内置变量ansible_ssh_pass定义了该主机的登录密码,如果建立了互信,则不需要这个参数;
第二、三、四行定义了一个名为groupname1的主机组,其中包含X.X.X.101-X.X.X.109,X.X.X.201-X.X.X.209共计18台主机;
第五、六行为groupname1的主机组定义了一个共同的变量:ansible_ssh_pass,以定义该组内所有主机的登录密码;
第七、八行定义了一个更大的组:groupname2,其下包含了groupname1组下的所有主机。
定义好之后,我们在ansible命令行和ansible-playbook中,可以非常灵活的使用,便于批量操作。例如批量查看groupname1组下所有主机的当前时间:
ansible groupname1 -a date
- Inventory内置参数
除了前面介绍的ansible_ssh_pass参数,Ansible Inventory内置了一些参数,这些参数在我们实际工作中也会经常使用,我们可以直接在Inventory文件中定义它。

我们也可以在ansible.cfg文件中的[defaults]部分更改一些Inventory内置参数的默认值,可以支持更改的有:

- 动态Inventory
在实际的应用中,会存在大量的主机列表信息,如果手动维护Ansible中的Inventory文件将会非常的繁琐,所以支持动态Inventory将会让问题变得统一、清晰、简单许多。动态Inventory也就是Ansible所有的Inventory文件里面的主机列表和变量信息都支持从外部拉取,例如我们常用的CMDB,我们可以通过定义的脚本,将外部CMDB等其他运维系统中的主机信息同步至Ansible中。在实际的配置中仅需要更改ansible.cfg文件中的inventory参数为一个可执行的脚本即可。
[defaults]
inventory = /etc/ansible/inventory.sh
脚本的内容不受任何编程语言限制,但该脚本必须支持以下规范的参数,脚本的执行结果也有一定的要求:
--list或者-l,脚本运行该参数须显示所有主机和组的信息(Json格式)。
--host或者-H,脚本的该参数后需指定一个主机,运行结果也会返回该主机的所有信息(同样也必须为Json格式)。
脚本调试好之后,ansible将利用inventory变量所指向的脚本,获取主机和组信息(或者通过-i参数指定),来向主机执行命令。
- Inventory分割
如果我们想要同时使用常规Inventory文件和动态Inventory脚本,或者按不同业务/系统分割成的多个Inventory文件,我们可以把所有这些文件全部都放到同一个目录,并配置ansible.cfg文件的hostfile参数,让Ansible使用hostfile参数所指定的目录作为Inventory即可,也可以在命令行中使用-i命令来指定特定的Inventory文件。Ansible将会处理目录里所有的文件并将结果合并为一个完整的Inventory。
[defaults]
hostfile = /etc/ansible/inventory
2、Ansible Ad-Hoc命令使用
Ansible系统由控制主机对被管节点的操作方式可分为两类,即 Ad-Hoc和Playbook:
Ad-Hoc模式使用单个模块,支持批量执行单条命令。
Playbook模式是Ansible主要管理方式,也是Ansible功能强大的关键所在,Playbook通过多个Task集合完成一类功能,如 Web 服务的安装部署、数据库服务器的批量备份等,可以简单地把 Playbook理解为通过
组合多条Ad-Hoc操作的配置文件。
下面将通过两个小节的内容,来说明如何使用Ad-Hoc和Playbook。其中Ad-Hoc将重点介绍命令参数和几个常用的模块。
通常我们会以命令行的形式使用Ansible模块,或者将Ansible命令嵌入到脚本中去执行。Ansible自带了很多模块,我们可以直接使用他们。当我们不知道如何使用这些模块时,可以ansible-doc命令获取帮助,
例如:使用“ansible-doc -l”命令可以显示所有自带的模块和相关简介,使用“ansible-doc 模块名”命令可以显示该模块的参数及用法等内容。
- Ansible Ad-Hoc命令参数
我们可以使用“ansible -h”命令来列出所有的命令参数,下面列举了常用的一些参数,部分参数如果不指定将采用ansible.cfg中的设置值,或者采用原始默认值。

- Ansible常用模块介绍
连通性测试
通常采用Ping模块来测试远程主机的运行状态:
ansible ip -m ping
执行命令
执行命令可以采用四种方式,第一种方式是利用Command模块在远程主机上执行命令,但Command模块不支持管道命令,例如,查看某个主机的日期:
ansible ip -m command -a date -o
值得注意的是,Ansible默认的模块是Command,所以上面的命令可以简化为:
ansible ip -a date -o
第二种方式是利用Shell模块,切换到某个Shell执行远程主机上的Shell/Python脚本,或者执行命令,Shell支持管道命令,功能较Command更强大灵活,例如:
ansible ip -m shell -a 'bash /root/test.sh' -o
ansible ip -m shell -a 'echo "123456"|passwd --stdin root'
第三种方式是利用Raw模块,Raw支持管道命令。Raw有很多地方和Shell类似,但是如果是使用老版本Python(低于2.4),无法通过Ansible的其他模块执行命令,则需要先用到Raw模块远程安装Python-sim-plejson后才能受管;又或者是受管端是路由设备,因为没有安装Python环境,那就更需要使用Raw模块去管控了。例如:
ansible ip -m raw -a "cd /tmp;pwd"
第四种方式是利用Script模块,传输Ansible中控端上的Shell/Python脚本到远端主机上执行,即使远端主机没有安装Python也可以执行,有点类似Raw模块。但Script只能执行脚本,不能调用其他指令,且不支持管道命令,例如:
ansible ip -m script -a '/root/test.sh' -o
removes参数用来判断远端主机上是不是存在test.sh文件,如果存在,就执行管控机上的test.sh,不存在就不执行:
ansible ip -m script -a 'removes=/root/test.sh /root/test.sh' -o
creates用来判断远端主机上是不是存在test.sh文件,如果存在,就不执行,不存在就执行管控机上的test.sh文件:
ansible ip -m script -a 'creates=/root/test.sh /root/test.sh' -o
复制文件
常用的文件操作模块就是Copy模块,它主要用于将本地或远程机器上的文件拷贝到远程主机上。其主要参数有以下几个:
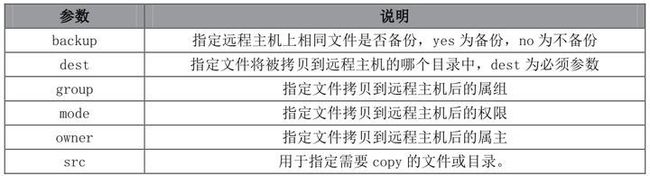
复制本地文件的到远程主机:
ansible ip -m copy -a 'src=/root/test.sh dest=/tmp/test.sh'
复制并修改文件的权限:
ansible ip -m copy -a 'src=/root/test.sh dest=/tmp/test.sh mode=755'
复制并修改文件的属主:
ansible ip -m copy -a 'src=/root/test.sh dest=/tmp/test.sh mode=755 owner=root'
复制文件前备份:
ansible ip -m copy -a 'src=test.sh backup=yes dest=/tmp'
服务管理
在Ansible Ad-Hoc中,Service模块可以帮助我们管理远程主机上的服务。例如,启动或停止远程主机中的某个服务。但是该服务本身必须要能够通过操作系统的管理服务的组件所管理,例如Redhat6中默认通过SysV进行服务管理,Redhat7中默认通过Systemd管理服务,如果该服务本身都不能被操作系统的服务管理组件所管理,那么也不能被Service模块管理。该模块的几个常用参数如下:

启动服务:
ansible all -m service -a "name=sshd state=started"
停止服务:
ansible all -m service -a "name=sshd state=stopped"
开启服务自启动:
ansible all -m service -a "name=sshd enable=yes"
安装包管理
在Ansible Ad-Hoc中,可以通过Yum模块实现在远程主机上通过Yum源管理软件包,包括安装、升级、降级、删除和列出软件包等。该模块的几个常用参数如下:

安装软件包:
ansible all -m yum -a 'name=nginx state=installed’
卸载软件包:
ansible all -m yum -a 'name=nginx state=removed'
临时启用local yum源安装最新版软件包:
ansible all -m yum -a 'name=nginx state=latest enablerepo=local'
用户管理
在Ansible Ad-Hoc中,可以通过User模块帮助我们管理远程主机上的用户,比如创建用户、修改用户、删除用户、为用户创建密钥对等操作。该模块的几个常用参数如下:

增加用户、组和密码:
ansible ip -m group -a "name=testg”
ansible ip -m user -a "name=test group=testg password=123456 home=/home/test”
删除用户和用户主目录:
ansible ip -m user -a "name=test state=absent remove=yes"
3、Ansible Playbook使用
在Ansible Ad-Hoc中,可以通过Yum模块实现在远程主机上通过Yum源管理软件包,包括安装、升级、降级、删除和列出软件包等。该模块的几个常用参数如下:
我们在使用Ansible时,绝大部分时间将花费在编写Playbook上,Playbook是一个Ansible术语,指的是用于配置管理的脚本。Ansible的Playbook是使用YAML语法编写的。YAML是一种类似于Json的文件格式,不过YAML更适合人来读写。我们在开始编写Playbook时,需要对YAML的语法有一定的了解,否则将经常碰到语法错误。下面首先通过一个安装和配置ntpd服务的Playbook案例来介绍:


第一行仅表示该文件为YAML格式文件,非必须。
第二行定义了该Playbook所针对的主机,all表示所有,也可以填写Inventory文件中的IP地址或者主机组名称。
第三行表示下面开始定义Task任务。
第四、五行定义了一个具体Task任务(通过Yum安装ntpd服务),包含任务名称和执行动作,其中任务名称为非必须,可以直接定义执行动作。
第六、七、八、九行定义了另一个具体Task任务(同步ntpd配置文件模板),并更改文件的属主、属组和文件权限。notify和下面的handlers为配对使用,当ntpd配置文件模板同步至远端主机后,文件的MD5值将发生变化,触发restart ntpd service这个handler。
第十、十一、十二行定义了上述handler的具体内容,包括名称和执行动作,也就是利用service模块来重启ntpd服务。
编制好了Playbook,我们需要使用--syntax-check参数来对该脚本进行语法检查:
ansible-playbook ntpd.yaml --syntax-check
playbook: ntpd.yaml
语法检测过后,可以用--list-task参数来查看该Playbook中的所有Task:

确认无误后,开始使用命令运行名为ntpd.yaml的Playbook:
ansible-playbook ntpd.yaml
后续如果我们的ntpd.conf.j2配置模板需要变更,并需要批量分发下去,我们可以指定copy ntp.conf这个Task,只运行该Task:
ansible-playbook ntpd.yaml --start-at-task=’copy ntp.conf’
除了上述参数之外,ansible-playbook还有几个常用的参数:
--step同一时间只执行一个Task,每个Task执行前都会提示确认一遍。
--tags=TAGS当Play和Task的Tag为该参数指定的值时才执行,多个Tag以逗号分隔。
--skip-tags=SKIP_TAGS当Play和Task的Tag不匹配该参数指定的值时才执行。
根据前面的案例,我们对Playbook的大体写法和用法有了一个大致的认识,下面重点介绍几个Play-book常用的使用要点:
- Playbook的组成
一个Playbook包括一个或多个Play。一个Play由Host的无序集合与Task的有序列表组成。每一个Task仅由一个模块构成。见下图所示:

- Tasks List和Action
Play的主体部分是Task列表,Task列表中的各任务按次序逐个在Hosts中指定的主机上执行,即在所有主机上完成第一个任务后再开始第二个任务。在运行Playbook时(从上到下执行),如果一个Host执行Task失败,整个Task都会回滚,我们需要修正Playbook中的错误,然后重新执行即可。Task的目的是使用指定的参数执行模块,而在模块参数中可以使用变量,模块执行时幂等等,这意味着多次执行是安全的,因为其结果一致。
另外,按照规范写法,每一个Task必须有一个名称Name,虽然这不是必须的,但这样在运行Playbook时,从其输出的任务执行信息中可以很好的辨别出是属于哪一个Task。如果没有定义Name,Action的值将会用作输出信息中标记特定的Task,结果不好分辨。定义一个Task,常见的格式为“module: options”,例如:“yum: name=httpd”。值得注意的是,Ansible的自带模块中,Command模块和Shell模块无需使用key=value格式,直接编写要执行的命令即可。
- Handlers
Handlers也是一些Task的列表,和一般的Task并没有什么区别。它是由通知者进行的Notify,如果没有被Notify,则Handlers不会执行,如果被Notify了,则Handlers被执行。不管有多少个通知者进行了Notify,等到Play中的所有Task都执行完成之后,Handlers也只会被执行一次。例如:
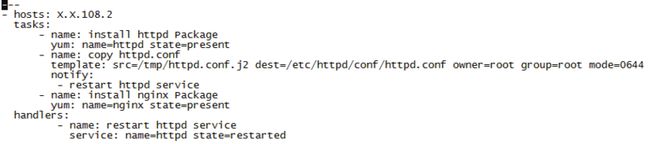
- 变量引用
我们可以在PlayBook中通过“vars: 变量名”的方式声明变量,并通过“{{变量名}}”的方式使用已声明的变量。另外,我们还可以直接引用Ansible的变量,包括采集到的主机Fact中的变量,例如:通过ansible_all_ipv4_address来获取IPV4地址,或者通过ansible_distribution、ansible_distribution_version来获取操作类型和版本信息。除此之外,还能引用已编辑好的Inventory文件中定义的主机变量,这样当安装完一些软件,需要根据主机中定义的变量来做一些自动化配置时,将会非常好用。例如:
vi /etc/ansible/hosts #定义Inventory文件中的变量与值
X.X.108.2 hostname="test"

上面的案例是通过vars的方式定义了package和service两个变量,并在下面的yum和service两个Task中进行引用,第三个Task则是直接引用setup生成的Fact变量和来自Inventory文件中定义的主机变量hostname,来实现将内容信息传递至远端主机的文件中,输出结果如下:
cat /tmp/test.txt
test:RedHat 7.2
- 条件判断
我们可以在PlayBook中通过“when: 变量==值”的方式声明一个条件判断,可以看出when的值是一个条件表达式,如果条件判断成立,Task就执行,如果判断不成立,则task不执行。例如当我们需要根据变量、Facts(setup)或此前任务的执行结果来作为某Task执行与否的前提时,则要用到条件判断,这时可以在Playbook中使用when子句:在Task后添加when子句。另外,when子句支持jinjia2表达式或语法。

- 迭代
当我们有需要重复性执行的任务时,可以使用迭代机制。其使用格式为将需要迭代的内容定义为item变量引用,并通过with_items语句指明迭代的元素列表即可。例如:


- Templates
Jinja是基于Python的模板引擎。Template类是Jinja的另一个重要组件,可以看作一个编译过的模块文件,用来生产目标文本,我们可以传递Python的变量给模板去替换模板中的标记。例如,我们在做Nginx安装与配置时,有些监听端口、服务名称等配置可以通过变量的方式在Inventroy文件中为不同主机预定义好,当我们定义好了一个模板,并将模板中的监听端口和服务名称设置为变量后,在运行Template这个Task时,将会把不同主机的这些变量信息传递到模板中使用,实现配置的自动化。例如:
vi /tmp/httpd.conf.j2 #定义模板中的变量
Listen {{http_port}}
ServerName {{server_name}}
MaxClients {{access_num}}
vi /etc/ansible/hosts #定义Inventory文件中的变量与值
[test]
X.X.X.2 http_port=X.X.X.2:80 access_num=50 server_name="test:80"
安装Nginx时,将把Inventory文件中主机定义好的变量与值传递到模板中,并拷贝至该远端主机:

- Tags
在一个Playbook中,我们一般会定义很多个Task,如果我们只想执行其中的某一个Task或多个Task时就可以使用Tags标签功能了,例如:

ansible-playbook test.yml --tags="nginx"
4、Ansible Facts使用
Facts组件是Ansible用于采集被管主机设备信息的一个功能,当Ansible采集Fact的时候,它会收集被管主机的各种详细信息:CPU架构、操作系统、IP地址、内存信息、磁盘信息等,这些信息保存在被称作Fact的变量中。Ansible使用一个名为Setup的特殊模块来实现Fact的收集,在Playbook中默认会调用这个模块进行Fact收集,在命令行中可以通过“ansible ip -m setup”来进行手动收集,整个Facts信息被包装JSON格式的数据结构中, Ansible Facts是最上层的值。例如:

Facts还支持通过filter参数来查看指定信息,例如下面只查看远端主机的操作系统和版本:

查看远端主机的CPU和内存大小:

查看远端主机的各文件系统大小和剩余容量:

在Playbook中,Facts组件默认会收集很多的主机的基础信息,可以通过前面的Fact缓存机制,将这些信息缓存到本地目录或者内存数据库中,在做配置管理的时候进行引用,也可以用来将获取的主机基础信息自动同步到CMDB中去,实现基础信息的自动采集功能。下面通过通过演示,说明如何通过ansible-cmdb插件,实现远端主机CPU自动同步至外部CMDB系统中。
首先,我们需要安装ansible-cmdb插件,下载链接如下:
其次,开始安装ansible-cmdb插件:
gzip -dc ansible-cmdb-1.27.tar.gz|tar -xvf -
cd ansible-cmdb-1.27
python setup.py install
生成所有主机的Fact信息并用filter过滤出主机CPU值:
ansible all -m setup -t /tmp/factout
ansible all -m setup -a “filter=ansible_processor_count” -t /tmp/cpu
通过ansible-cmdb插件以csv或sql格式输出IP地址和CPU颗数值:
PATH=/usr/local/bin:$PATH
ansible-cmdb -t csv -c name,cpus /tmp/cpu >/tmp/cpu.csv
ansible-cmdb -t sql /tmp/cpu >/tmp/cpu.sql
以csv格式或者sql格式导入信息至外部CMDB系统中(根据支持方式灵活选用),这里以postgres数据库为例,通过转csv格式为sql格式导入至外部CMDB系统:

当然,以上仅仅是简单的示例,事实上,我们可以利用好Ansible Fact的功能,实现更加复杂的CMDB自动化采集功能。