简介: 记录这一年闲鱼消息的优化之路
- 背景
======
在2020年年初的时候接手了闲鱼的消息,当时的消息存在各种问题,网上的舆情也是接连不断:“闲鱼消息经常丢失”、“消息用户头像乱了”、“订单状态不对”(相信现在看文章的你还在吐槽闲鱼的消息)。所以闲鱼的稳定性是一个亟待解决的问题,我们调研了集团的一些解决方案,例如钉钉的IMPass。直接迁移的成本和风险都是比较大,包括服务端数据需要双写、新老版本兼容等。
那基于闲鱼现有的消息架构和体系,如何来保证它的稳定性?治理应该从哪里开始?现在闲鱼的稳定性是什么样的?如何衡量稳定性?希望这篇文章,能让大家看到一个不一样的闲鱼消息。
- 行业方案
========
消息的投递链路大致分为三步:发送者发送,服务端接收然后落库,服务端通知接收端。特别是移动端的网络环境比较复杂,可能你发着消息,网络突然断掉了;可能消息正在发送中,网络突然好了,需要重发。

在如此复杂的网络环境下,是如何稳定可靠的进行消息投递的?对发送者来说,它不知道消息是否有送达,要想做到确定送达,就需要加一个响应机制,类似下面的响应逻辑:
- 发送者发送了一条消息“Hello”,进入等待状态。
- 接收者收到这条消息“Hello”,然后告诉发送者说我已经收到这条消息了的确认信息。
- 发送者接收到确认信息后,这个流程就算完成了,否则会重试。
上面流程看似简单,关键是中间有个服务端转发过程,问题就在于谁来回这个确认信息,什么时候回这个确认信息。网上查到比较多的是如下一个必达模型,如下图所示:
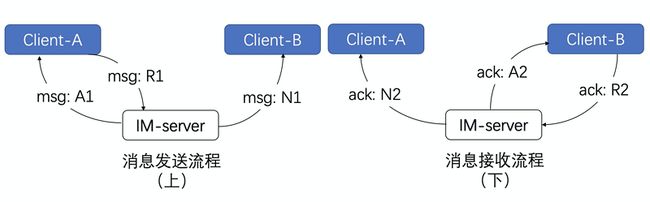

[发送流程]
- A向IM-server发送一个消息请求包,即msg:R1
- IM-server在成功处理后,回复A一个消息响应包,即msg:A1
- 如果此时B在线,则IM-server主动向B发送一个消息通知包,即msg:N1(当然,如果B不在线,则消息会存储离线)
[接收流程]
- B向IM-server发送一个ack请求包,即ack:R2
- IM-server在成功处理后,回复B一个ack响应包,即ack:A2
- 则IM-server主动向A发送一个ack通知包,即ack:N2
一个可信的消息送达系统就是靠的6条报文来保证的,有这个投递模型来决定消息的必达,中间任何一个环节出错,都可以基于这个request-ack机制来判定是否出错并重试。看下在第4.2章中,也是参考了上面这个模型,客户端发送的逻辑是直接基于http的所以暂时不用做重试,主要是在服务端往客户端推送的时候,会加上重试的逻辑。
- 闲鱼消息的问题
===========
刚接手闲鱼消息,没有稳定相关的数据,所以第一步还是要对闲鱼消息做一个系统的排查,首先对消息做了全链路埋点。

基于消息的整个链路,我们梳理出来了几个关键的指标:发送成功率、消息到达率、客户端落库率。整个数据的统计都是基于埋点来做的。在埋点的过程总,发现了一个很大的问题:闲鱼的消息没有一个全局唯一的ID,导致在全链路埋点的过程中,无法唯一确定这条消息的生命周期。
3.1 消息唯一性问题
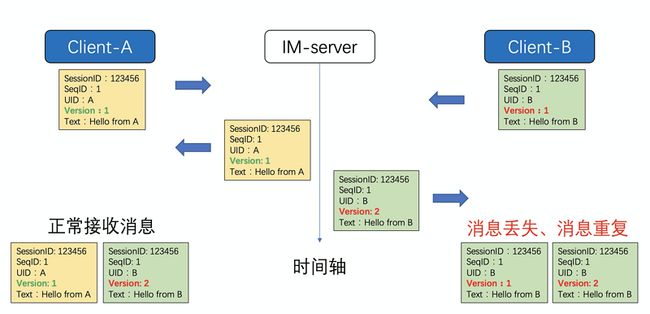
之前闲鱼的消息是通过3个变量来唯一确定一个消息
- SessionID: 当前会话的ID
- SeqID:用户当前本地发送的消息序号,服务端是不关心此数据,完全是透传
- Version:这个比较重要,是消息在当前会话中的序号,已服务端为准,但是客户端也会生成一个假的version
以上图为例,当A和B同时发送消息的时候,都会在本地生成如上几个关键信息,当A发送的消息(黄色)首先到达服务端,因为前面没有其他version的消息,所以会将原数据返回给A,客户端A接收到消息的时候,再跟本地的消息做合并,只会保留一条消息。同时服务端也会将此消息发送给B,因为B本地也有一个version=1的消息,所以服务端过来的消息就会被过滤掉,这就出现消息丢失的问题。
当B发送消息到达服务端后,因为已经有version=1的消息,所以服务端会将B的消息version递增,此时消息的version=2。这条消息发送给A,和本地消息可以正常合并。但是当此消息返回给B的时候,和本地的消息合并,会出现2条一样的消息,出现消息重复,这也是为什么闲鱼之前总是出现消息丢失和消息重复最主要的原因。
3.2 消息推送逻辑问题
之前闲鱼的消息的推送逻辑也存在很大的问题,发送端使用http请求,发送消息内容,基本不会出问题,问题是出现在服务端给另外一端推送的时候。如下图所示,
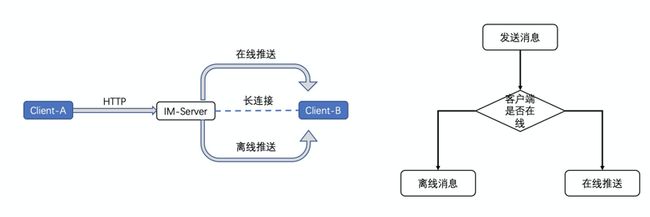
服务端在给客户端推送的时候,会先判断此时客户端是否在线,如果在线才会推送,如果不在线就会推离线消息。这个做法就非常的简单粗暴。长连接的状态如果不稳定,导致客户端真实状态和服务端的存储状态不一致,就导致消息不会推送到端上。
3.3 客户端逻辑问题
除了以上跟服务端有关系外,还有一类问题是客户端本身设计的问题,可以归结为以下几种情况:
- 多线程问题
反馈消息列表页面会出现布局错乱,本地数据还没有完全初始化好,就开始渲染界面
- 未读数和小红点的计数不准确
本地的显示数据和数据库存储的不一致。
- 消息合并问题
本地在合并消息的时候,是分段合并的,不能保证消息的连续性和唯一性。
诸如以上的几种情况,我们首先是对客户端的代码做了梳理与重构,架构如下图所示:
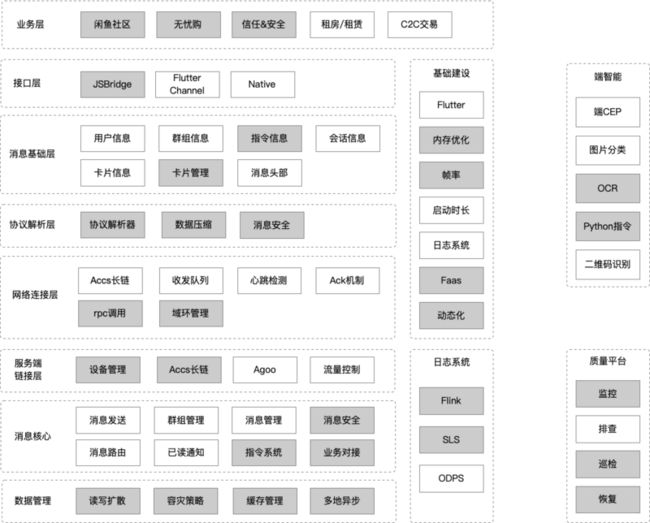
- 我们的解法 - 引擎升级
================
进行治理的第一步就是,解决闲鱼消息的唯一性的问题。我们也调研了钉钉的方案,钉钉是服务端全局维护消息的唯一ID,考虑到闲鱼消息的历史包袱,我们这边采用UUID作为消息的唯一ID,这样就可以在消息链路埋点以及去重上得到很大的改善。
4.1 消息唯一性
在新版本的APP上面,客户端会生成一个uuid,对于老版本无法生成的情况,服务端也会补充上相关信息。
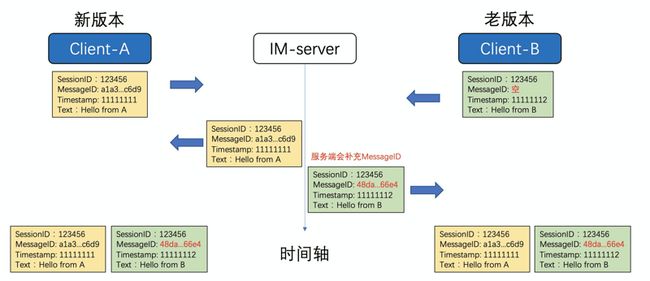
消息的ID类似a1a3ffa118834033ac7a8b8353b7c6d9,客户端在接收到消息后,会先根据MessageID来去重,然后基于Timestamp排序就可以了,虽然客户端的时间可能不一样,但是重复的概率还是比较小。
- (void)combileMessages:(NSArray*)messages {
...
// 1. 根据消息MessageId进行去重
NSMutableDictionary *messageMaps = [self containerMessageMap];
for (PMessage *message in msgs) {
[messageMaps setObject:message forKey:message.messageId];
}
// 2. 消息合并后排序
NSMutableArray *tempMsgs = [NSMutableArray array];
[tempMsgs addObjectsFromArray:messageMaps.allValues];
[tempMsgs sortUsingComparator:^NSComparisonResult(PMessage * _Nonnull obj1, PMessage * _Nonnull obj2) {
// 根据消息的timestamp进行排序
return obj1.timestamp > obj2.timestamp;
}];
...
} 4.2 重发重连
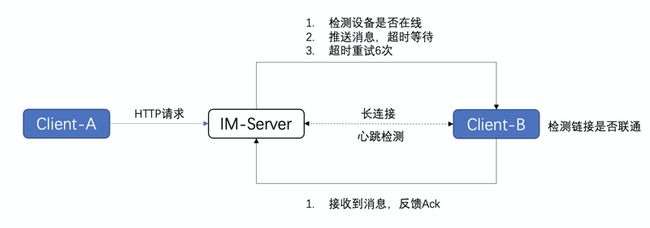
基于#2中的重发重连模型,闲鱼完善了服务端的重发的逻辑,客户端完善了重连的逻辑。
- 客户端会定时检测ACCS长连接是否联通
- 服务端会检测设备是否在线,如果在线会推送消息,并会有超时等待
- 客户端接收到消息之后,会返回一个Ack
已经有小伙伴发表了一篇文章:《向消息延迟说bybye:闲鱼消息及时到达方案(详细)》,讲解了下关于网络不稳定给闲鱼消息带来的问题,在这里就不多赘述了。
4.3 数据同步
重发重连是解决的基础网络层的问题,接下来就要看下业务层的问题,很多复杂情况是通过在业务层增加兼容代码来解决的,闲鱼消息的数据同步就是一个很典型的场景。在完善数据同步的逻辑之前,我们也调研过钉钉的一整套数据同步方案,他们主要是由服务端来保证的,背后有一个稳定的长连接保证,大致流程如下:
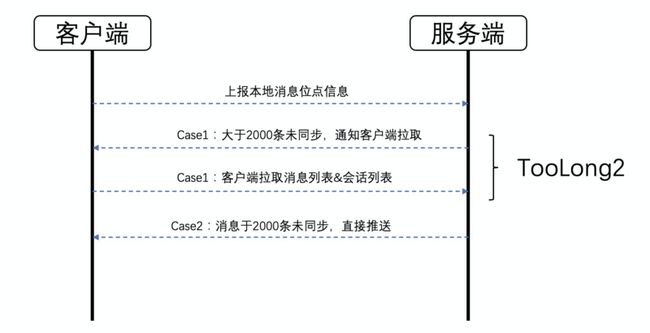
闲鱼的服务端暂时还没有这种能力,原因详见4.5的服务端存储模型。所以闲鱼这边只能从客户端来控制数据同步的逻辑,数据同步的方式包括:拉取会话、拉取消息、推送消息等。因为涉及到的场景比较复杂,之前有个场景就是推送会触发增量同步,如果推送过多的话,会同时触发多次网络请求,为了解决这个问题,我们也做了相关的推拉队列隔离。
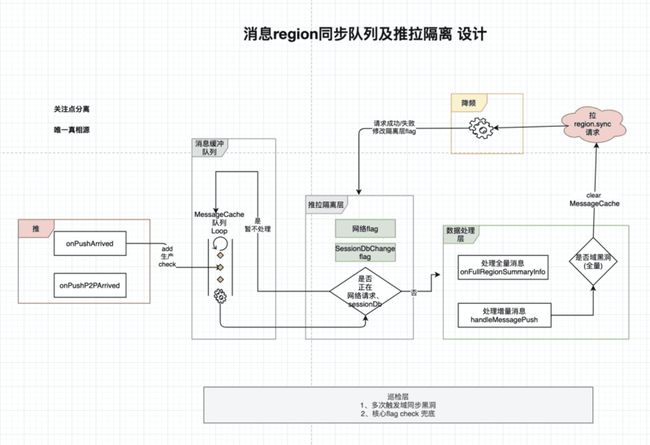
客户端控制的策略就是如果在拉取的话,会先将push过来的消息加到缓存队列里面,等拉取的结果回来,会再跟本地缓存的逻辑做合并,这样就可以避免多次网络请求的问题。之前同事已经写了一篇关于推拉流控制的逻辑,《如何有效缩短闲鱼消息处理时长》,这里也不过多赘述了。
4.4 客户端模型
客户端在数据组织形式上,主要分2中:会话和消息,会话又分为虚拟节点、会话节点和文件夹节点。
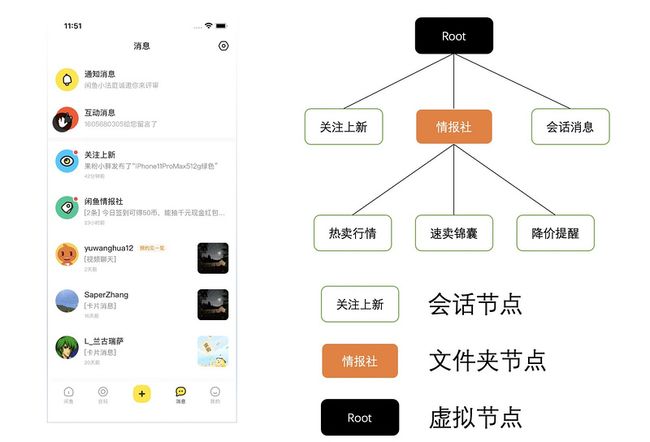
在客户端会构建上图一样的树,这棵树主要保存的是会话显示的相关信息,比如未读数、红点以及最新消息摘要,子节点更新,会顺带更新到父节点,构建树的过程也是已读和未读数更新的过程。其中比较复杂的场景是闲鱼情报社,这个其实是一个文件夹节点,它包含了很多个子的会话,这就决定了他的消息排序、红点计数以及消息摘要的更新逻辑会更复杂,服务端告知客户端子会话的列表,然后客户端再去拼接这些数据模型。
4.5 服务端存储模型

在4.3中大概讲了客户端的请求逻辑,历史消息会分为增量和全量域同步。这个域其实是服务端的一层概念,本质上就是用户消息的一层缓存,消息过来之后会暂存在缓存中,加速消息读取。但是这个设计也存在一个缺陷,就是域环是有长度的,最多保存256条,当用户的消息数多于256条,只能从数据库中读取。
关于服务端的存储方式,我们也调研过钉钉的方案,是写扩散,优点就是可以很好地对每位用户的消息做定制化,比如钉的逻辑,缺点就是存储量很很大。闲鱼的这套解决方案,应该是介于读扩散和写扩散之间的一种解决方案。这个设计方式不仅使客户端逻辑复杂,服务端的数据读取速度也会比较慢,后续这块也可以做优化。
- 我们的解法 - 质量监控
================
在做客户端和服务端的全链路改造的同时,我们也对消息线上的行为做了监控和排查的逻辑。
5.1 全链路排查

全链路排查是基于用户的实时行为日志,客户端的埋点通过集团实时处理引擎Flink,将数据清洗到SLS里面,用户的行为包括了消息引擎对消息的处理、用户的点击/访问页面的行为、以及用户的网络请求。服务端测会有一些长连接推送以及重试的日志,也会清洗到SLS,这样就组成了从服务端到客户端全链路的排查的方案,详情请参考《消息质量平台系列文章|全链路排查篇》。
5.2 对账系统
当然为了验证消息的准确性,我们还做了对账系统。
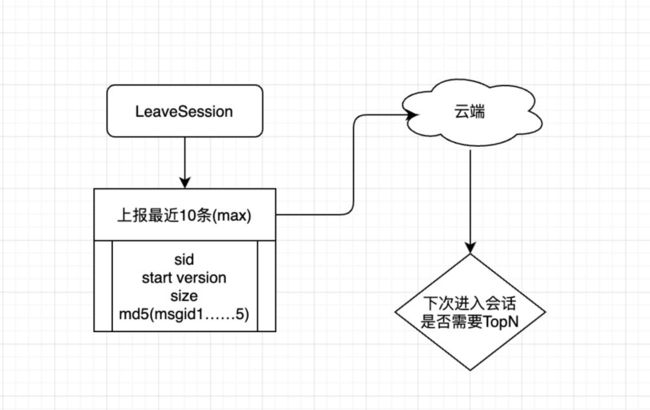
在用户离开会话的时候,我们会统计当前会话一定数量的消息,生成一个md5的校验码,上报到服务端。服务端拿到这个校验码之后再判定是否消息是正确的,经过抽样数据验证,消息的准确性基本都在99.99%。
6 核心数据指标
我们在统计消息的关键指标的时候,遇到点问题,之前我们是用用户埋点来统计的,发现会有3%~5%的数据差;所以后来我们采用抽样实时上报的数据来计算数据指标。
消息到达率=客户端实际收到的消息量/客户端应该收到的消息量
客户端实际收到的消息的定义为消息落库才算是
该指标不区分离线在线,取用户当日最后一次更新设备时间,理论上当天且在此时间之前下发的消息都应该收到。

最新版本的到达率已经基本达到99.9%,从舆情上来看,反馈丢消息的也确实少了很多。
7. 未来规划
========
整体看来,经过一年的治理,闲鱼的消息在慢慢的变好,但还是存在一些待优化的方面:
- 现在消息的安全性不足,容易被黑产利用,借助消息发送一些违规的内容。
- 消息的扩展性较弱,增加一些卡片或者能力就要发版,缺少了动态化和扩展的能力。
- 现在底层协议比较难扩展,后续还是要规范一下协议。
- 从业务角度看,消息应该是一个横向支撑的工具性或者平台型的产品,规划可以快速对接二方和三方的快速对接。
在2021年,我们会持续关注消息相关的用户舆情,希望闲鱼消息能帮助闲鱼用户更好的完成二手交易。
作者:闲鱼技术——景松
原文链接
本文为阿里云原创内容,未经允许不得转载