kl散度度量分布_使用 Batch Normalization 防止变分自编码器中 KL 散度的消失

喜欢就关注我们吧!
本论文由腾讯 AI Lab 主导,和佛罗里达大学合作完成。作者利用通过直接计算KL散度在数据集中的期望并使其有一个大于0的下界从而解决这个问题。
作者基于此提出了BN-VAE,在编码器的输出使用batch normalization。在没有增加额外的训练参数和训练量的情况下有效缓解了KL消失的问题。
A Batch Normalized Inference Network Keeps the KL Vanishing Away
变分自编码器(VAE)是一种很常用的生成模型,它希望构建一个从隐变量空间到数据空间的映射。因为其可以从分布中采样,每次都有一定的随机性,所以在多样性文本生成中有一席之地。
然而在文本生成中,decoder一般为很强的自回归模型比如RNN家族 (LSTM,GRU等)或者最近的Transformer结构。
当VAE与他们配合使用时往往会产生KL散度消失的现象,因为decoder的自回归性,往往会忽略掉VAE中的隐变量部分。
之前已经有很多很好的工作来试图解决这个问题,但是都需要增加额外的参数或者训练过程。
如何不增加训练负担并且有效地防止KL散度的消失是本文研究的动机。VAE需要优化边际似然概率的下界,即Evidence Lower Bound(ELBO):
![]()
在我们实际运用VAE时,正态分布往往是一个通常的选择,从来上式中KL的项可以由如下计算:

式中变量为在隐空间的第i维的后验分布的均值和标准差。在实际计算中,我们往往会用到batch训练,所以上式在训练过程中可以进一步进行计算得到:

当batch size很大时,上式中的KL项将会近似于整个数据集的KL的均值。由此,我们可以通过限制均值和方差的分布来限制KL在数据集中的分布。这样KL就相当于是一个关于隐变量的后验分布参数的分布。
此外当batch size足够大时上式可以表示成如下:

由于加号后的一项恒大于等于0,所以不等式成立。通过这个变换不难想到可以使用batch normalization来对均值的分布进行约束。对后验分布中的均值进行如下操作:
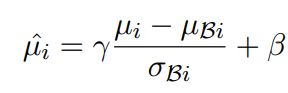
式中gamma和beta为batch normalization中的参数,分别可以控制mu分布的方差和均值。将上式中的mu替换到KL的计算式子中我们可以得到:

至此,我们可以通过更改gamma和beta参数来控制KL分布的期望的下界。整体流程可以总结为:

同样,我们可以将这个方法应用于CVAE中,具体证明过程在此不赘述。算法如下:

为了验证BN-VAE方法的有效性我们进行了语言模型,用隐变量进行文本分类以及对话生成的实验。

表一:在 Yahoo 和 Yelp 数据集上语言模型的结果。

表二:在 Yahoo 和 Yelp 数据集上训练模型的时间。
从上面两张表中可以看出,BN-VAE取得了很好的效果并且训练时间和VAE相差无几。
在用隐变量进行文本分类中BN-VAE同样表现十分出色,结果如下表。

表三:在 Yelp(采样) 数据集中的分类结果。

表四:不同算法下的采样回复。
在对话实验中,由于BN-VAE可以得到相对可控的KL值,使得采样出来的回答更加符合原文语义。样例如表4。
▼ 往期精彩回顾 ▼ Linux 内核对 Rust 的支持有新进展,双方进行深入探讨送书|爱上读书,每天都是读书日!10本技术书(云计算、大数据等)任你选!为破除“谷歌控制说”,Istio 重组指导委员会挑战树莓派?首个运行 Linux 系统的 RISC-V 架构微型计算机 PicoRio 发布29 年超 100 万次 commit,Linux 内核何以发展至今?

觉得不错,请点个在看呀