爬虫实战:要不是热爱学习,谁会爬小姐姐。分析Ajax来爬取今日头条街拍美图(python)
有些网页我们请求的html代码并没有我们在浏览器里看到的内容。
因为有些信息是通过Ajax加载并通过JavaScript渲染生成的。
一.目标站点分析
头条街拍
查看的Ajax请求
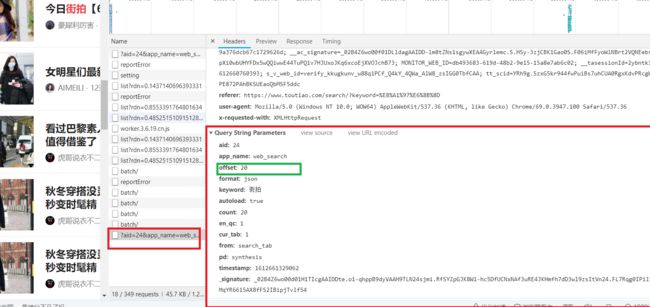
选择network 勾选preserve log 再勾选XHR ,数据链接如左侧aid格式

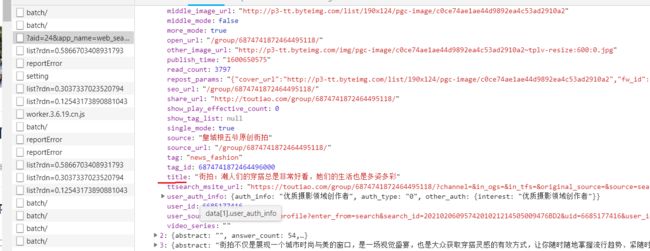
在data下面能够找到title
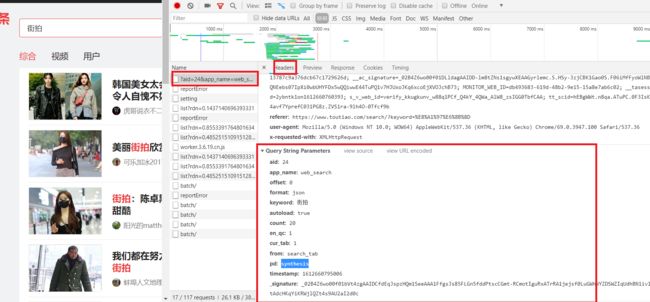
我们网页不断下滑,发现请求有offset有20,40,60变化。如图。
我们可以认为改变offset的值就能拿到不同数据。

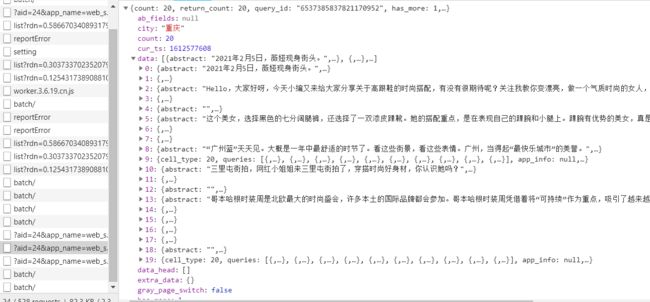
通过观察data,发现数据是json数据。
实战
一.抓取索引页内容
1.查看URL
蓝色为基本url,其他为参数

这些参数在下图
急需下拉网页,只有offset在变化,每次变化20
获取html代码如下
from urllib.parse import urlencode
import requests
from requests.exceptions import ConnectionError
def get_page(offest,keyword):#获取请求并返回解析页面,offest,keyword为可变参数
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offest,#页数
'format': 'json',
'keyword': keyword,#关键词,本例子为街拍
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1612660795006',
'_signature': '_02B4Z6wo00f01bVt4zgAAIDCfdEqJspzHQm1SeeAAA1FfgsJs85FLGn5fddPtscCGmt-RCmotIguRxATrRA1jejsf0LuGWhNYZDSWZIqUdhBN1ivlGKkDtAdcHKqYiKRWjlQZt4s9AU2aI2d0c'
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
base_url = 'https://www.toutiao.com/api/search/content/?'
url = base_url + urlencode(params)
try:
response = requests.get(url,headers = headers)
if response.status_code == 200 :
return response.text
except ConnectionError:
print('程序错误')
return None
def main():
base_url = 'https://www.toutiao.com/api/search/content/?'
html=get_page(0,'街拍')
print(html)
if __name__ =='__main__':
main()
 可以发现结果中有很多超链接
可以发现结果中有很多超链接

二.数据解析
回到浏览器,查看返回结果Respnse响应,数据格式为json格式
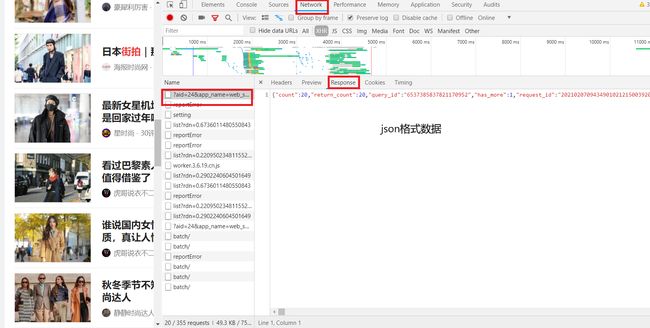
在Preview找到data

对data进行展开,其中的0,1,2.。均为一组街拍

展开0
图片url在image_list里
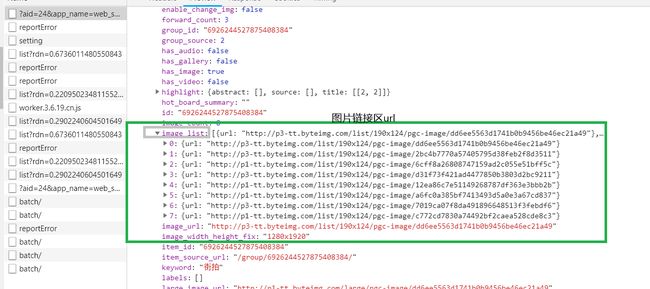
图片名titlie

#数据解析
import json
def parse_page_index(html):
data=json.loads(html)#转换为json对象
if data and 'data'in data.keys():#判断响应里的data是否存在
for item in data.get('data'): # 用item循环每一条,即0,1,2...
# 这里需要判断image_list是否为空
title = item.get('title')
if 'image_list' in item and item['image_list'] != []:
images = item['image_list']
for image in images:
yield {
'image': image.get('url'),
'title': title
} # 返回的一个字典
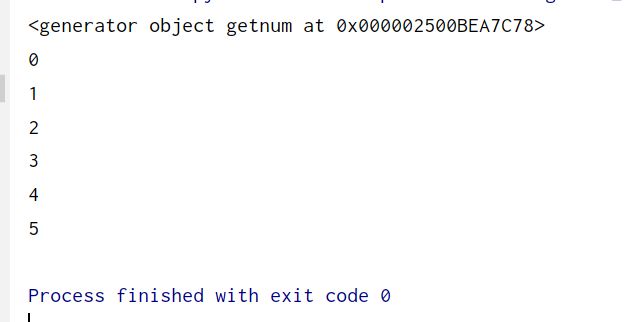
yield用法见例子
返回的是一个可以迭代的对象
def getnum(n):
i = 0
while i <= n:
yield i
i += 1
a = getnum(5)
print(a)
for i in a:
print(i)
三.图片保存
import os
from hashlib import md5
def save_image(item):
#os.path模块主要用于文件的属性获取,exists是“存在”的意思,
#所以顾名思义,os.path.exists()就是判断括号里的文件夹'picture'+str(offset)是否存在的意思,括号内的可以是文件路径。
if not os.path.exists(item.get('title')):#判断当前文件夹下是否有该文件
os.mkdir(item.get('title'))#如果不存在就创建该文件夹
try:
response=requests.get(item['image']) #get函数获取图片链接地址,requests发送访问请求,上面那个字典
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
# md5摘要算法(哈希算法),通过摘要算法得到一个长度固定的数据块。将文件保存时,通过哈希函数对每个文件进行文件名的自动生成。
# md5() 获取一个md5加密算法对象
# hexdigest() 获取加密后的16进制字符串
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
print('图片保存路径是: ', file_path)
else:
print('图片已经下载',file_path)
except requests.ConnectionError:
print('图片保存失败')
md5(response.content).hexdigest()摘要算法(哈希算法),通过摘要算法得到一个长度固定的数据块。将文件保存时,通过哈希函数对每个文件进行文件名的自动生成。
示例
from hashlib import md5
hash_functions = [md5]
def get_hash_code(s):
result = []
hash_obj = md5(s)
hash_hex = hash_obj.hexdigest()
result.append((hash_obj.name, hash_hex, len(hash_hex)))
return result
if __name__ == '__main__':
s = "123"
result = get_hash_code(s.encode("utf-8"))
print(result)

总的代码
from urllib.parse import urlencode
import requests
from requests.exceptions import ConnectionError
import json
def get_page(offest,keyword):#获取请求并返回解析页面,offest,keyword为可变参数
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offest,#页数
'format': 'json',
'keyword': keyword,#关键词,本例子为街拍
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1612660795006',
'_signature': '_02B4Z6wo00f01bVt4zgAAIDCfdEqJspzHQm1SeeAAA1FfgsJs85FLGn5fddPtscCGmt-RCmotIguRxATrRA1jejsf0LuGWhNYZDSWZIqUdhBN1ivlGKkDtAdcHKqYiKRWjlQZt4s9AU2aI2d0c'
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
base_url = 'https://www.toutiao.com/api/search/content/?'
url = base_url + urlencode(params)
try:
response = requests.get(url,headers = headers)
if response.status_code == 200 :
return response.text
except ConnectionError:
print('程序错误')
return None
#数据解析
import json
def parse_page_index(html):
data=json.loads(html)#转换为json对象
if data and 'data'in data.keys():#判断响应里的data是否存在
for item in data.get('data'): # 用item循环每一条,即0,1,2...
# 这里需要判断image_list是否为空
title = item.get('title')
if 'image_list' in item and item['image_list'] != []:
images = item['image_list']
for image in images:
yield {
'image': image.get('url'),
'title': title
} # 返回一个字典
import os
from hashlib import md5
def save_image(item):
#os.path模块主要用于文件的属性获取,exists是“存在”的意思,
#所以顾名思义,os.path.exists()就是判断括号里的文件夹'picture'+str(offset)是否存在的意思,括号内的可以是文件路径。
if not os.path.exists(item.get('title')):#判断当前文件夹下是否有该文件
os.mkdir(item.get('title'))#如果不存在就创建该文件夹
try:
response=requests.get(item['image']) #get函数获取图片链接地址,requests发送访问请求,上面那个字典
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
# md5摘要算法(哈希算法),通过摘要算法得到一个长度固定的数据块。将文件保存时,通过哈希函数对每个文件进行文件名的自动生成。
# md5() 获取一个md5加密算法对象
# hexdigest() 获取加密后的16进制字符串
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
print('图片保存路径是: ', file_path)
else:
print('图片已经下载',file_path)
except requests.ConnectionError:
print('图片保存失败')
def main():
for offest in range(0, 60, 20):
html = get_page(offest, '街拍')
a = parse_page_index(html)
for item in a:
save_image(item)
if __name__ =='__main__':
main()
 结果文件夹
结果文件夹
 打开一个文件夹
打开一个文件夹

文件夹太多,我们修改为一个文件夹
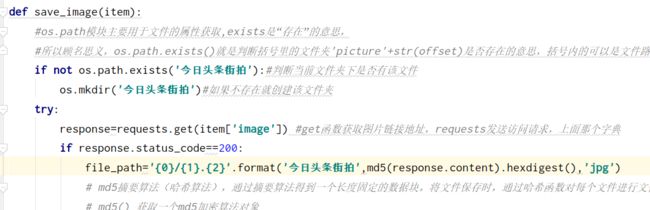
结果
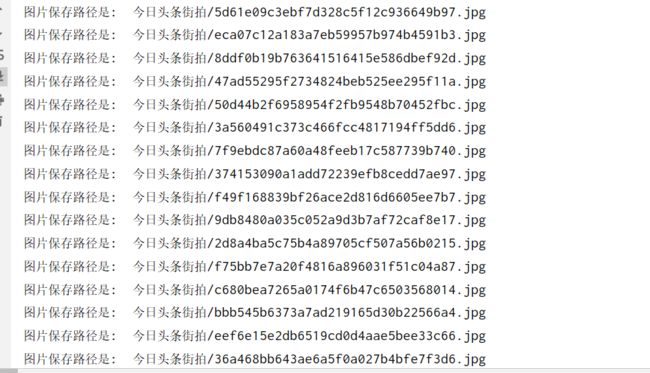
结果文件夹
![]()
作者:电气-余登武。
码字不易,请点个赞再走。