中国大学排名定向爬虫-Python网络爬虫与信息提取-北京理工大学嵩天教授
功能描述
- 输入:大学排名网站url链接;
- 输出:大学排名信息的屏幕输出(排名、大学名称、总分等);
- 技术路线:requests-bs4;
- 定向爬虫:仅对输入url进行爬取,不扩展爬取;
程序的结构设计
- 获取大学排名网页内容: getHTMLText( );
- 提取网页内容中信息到合适的数据结构: fillUnivList( );
- 利用数据结构展示并输出结构: printUnivList( );
代码实现
- 获取大学排名网页内容: getHTMLText( )
def getHTMLText(url):
try:
r=requests.get(url,timeout = 30)
r.raise_for_status() #产生异常信息
r.encoding = r.apparent_encoding
return r.text
except:
return ""
-
提取网页内容中信息到合适的数据结构: fillUnivList( )
-
首先我们可以查看网页的源代码,如下所示:
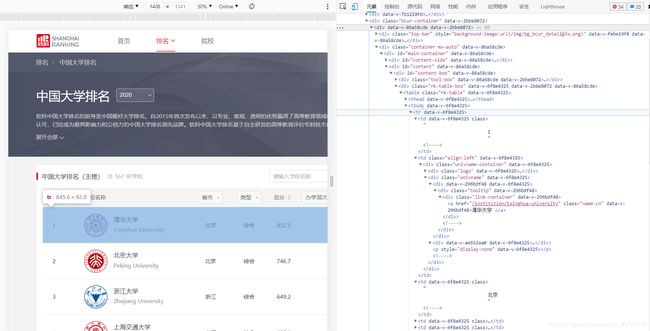
可以看见,每一所大学的信息是存在于"tbody"标签下的每一个"tr"标签里的,除大学中文名称存在于"a"标签中(含中英文,需区别),其余均直接存在于"td"标签中;
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').findAll("tr"): #遍历tbody标签,每个tr就是一所大学的信息
if isinstance(tr,bs4.element.Tag): #检测tr标签是否bs4中定义的类型,过滤掉非标签类型
a = tr('a') #将所有的a标签存为一个列表类型
tds = tr('td') #对tr标签中的td标签做查询并存为一个列表类型
ulist.append([tds[0].text.strip(),a[0].text.strip(),tds[2].text.strip(),tds[4].text.strip()]) #将需要的td标签加到列表中(排名/名称/地理位置/得分)
- 利用数据结构展示并输出结构: printUnivList( )
def printUnivList(ulist1,num):
# 格式化输出
tplt = "{0:^10}\t{1:{4}<12}\t{2:{4}^10}\t{3:^10}"
# 0、1、2、3为槽,{4}表示若宽度不够,使用format的4号位置处的chr(12288)(中文空格)进行填充
print(tplt.format("排名", "学校名称", "地理位置","综合得分", chr(12288))) #打印表头
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3],chr(12288))) #打印内容
print()
print("共有记录" + str(num) + "条")
此处同样可以参考Python 的 format 格式化输出一文对你所想要输出的信息进行格式编辑;
- 主函数
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url) #将url转换为html
fillUnivList(uinfo,html) #将html信息提取后放在uinfo的变量中
printUnivList(uinfo,30) #打印大学信息(20所)
- 总代码
import requests
import bs4
from bs4 import BeautifulSoup
#输入是需要获取的url信息,输出的是url的内容
def getHTMLText(url):
try:
r=requests.get(url,timeout = 30)
r.raise_for_status() #产生异常信息
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#提取html页面中的关键数据并放到一个list列表中
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').findAll("tr"): #遍历tbody标签,每个tr就是一所大学的信息
if isinstance(tr,bs4.element.Tag): #检测tr标签是否bs4中定义的类型,过滤掉非标签类型
a = tr('a') #将所有的a标签存为一个列表类型
tds = tr('td') #对tr标签中的td标签做查询并存为一个列表类型
ulist.append([tds[0].text.strip(),a[0].text.strip(),tds[2].text.strip(),tds[4].text.strip()]) #将需要的td标签加到列表中(排名/名称/地理位置/得分)
#将list的信息打印出来
def printUnivList(ulist1,num):
# 格式化输出
tplt = "{0:^10}\t{1:{4}<12}\t{2:{4}^10}\t{3:^10}"
# 0、1、2、3为槽,{4}表示若宽度不够,使用format的4号位置处的chr(12288)(中文空格)进行填充
print(tplt.format("排名", "学校名称", "地理位置","综合得分", chr(12288))) #打印表头
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3],chr(12288))) #打印内容
print()
print("共有记录" + str(num) + "条")
#主函数
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url) #将url转换为html
fillUnivList(uinfo,html) #将html信息提取后放在uinfo的变量中
printUnivList(uinfo,30) #打印大学信息(20所)
main()
- 爬取结果
排名 学校名称 地理位置 综合得分
1 清华大学 北京 852.5
2 北京大学 北京 746.7
3 浙江大学 浙江 649.2
4 上海交通大学 上海 625.9
5 南京大学 江苏 566.1
6 复旦大学 上海 556.7
7 中国科学技术大学 安徽 526.4
8 华中科技大学 湖北 497.7
9 武汉大学 湖北 488
10 中山大学 广东 457.2
11 西安交通大学 陕西 452.5
12 哈尔滨工业大学 黑龙江 450.2
13 北京航空航天大学 北京 445.1
14 北京师范大学 北京 440.9
15 同济大学 上海 439
16 四川大学 四川 435.7
17 东南大学 江苏 432.7
18 中国人民大学 北京 409.7
19 南开大学 天津 402.1
20 北京理工大学 北京 395.6
21 天津大学 天津 390.3
22 山东大学 山东 387.9
23 厦门大学 福建 383.3
24 吉林大学 吉林 379.5
25 华南理工大学 广东 379.4
26 中南大学 湖南 378.6
27 大连理工大学 辽宁 365.1
28 西北工业大学 陕西 359.6
29 华东师范大学 上海 358
30 中国农业大学 北京 351.5
共有记录30条
Process finished with exit code 0
到处,整个爬取就结束了,如有错误欢迎指出,若有帮到您欢迎点赞!