正则表达式学习-中国大学MOOC-Python网络爬虫与信息提取-北京理工大学嵩天教授
正则表达式相关知识及项目实战
- 前言
- 一、正则表达式相关知识
-
- 1:正则表达式的作用:
- 2:正则表达式的语法
- 3:Re库介绍
- 4:Re库相关函数简洁
- 二、淘宝商品比价定向爬虫项目实战
-
- 1.网页介绍与预期想要的结果
- 2.爬虫思路分析以及标签可行性分析
- 3.程序分析
- 4.代码展示
- 5.代码几个点需要注意的地方:
- 三、股票数据定向爬虫项目实战
-
- 1.网页介绍与预期想要的结果
- 2.爬虫思路分析以及标签可行性分析
- 3.程序步骤
- 4.代码展示
- 5.代码几个点需要注意的地方:
前言
本博客会先介绍正则表达式的基础知识,再讲解2个相关实战项目。非常基础,具体视频以及课件,在中国大学MOOC里可以找到,由北京理工大学,嵩天教授主讲:Python网络爬虫与信息提取
一、正则表达式相关知识
主要介绍正则表达式的相关含义,语法以及使用

1:正则表达式的作用:
正则表达式就是用来对字符串的简洁表达,主要用于字符串匹配中。

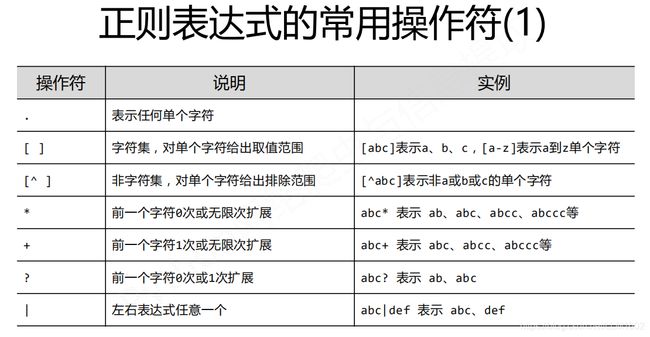
2:正则表达式的语法
1)常用操作符

2)正则表达式常用操作举例

可以看到通过Beautiful Soup库解析出来得到的,不再是像requests库那样的一个html页面,而是一个个的标签。即如下图所示:建立html页面和标签之间的对应关系
3:Re库介绍
1)Re库是python的标准库,主要用于字符串的匹配,调用方式是:import re
2)正则表达式的表示类型:
1> raw string:

2> string类型:
相比之下,需要多加个转义字符 \

4:Re库相关函数简洁
1)Re主要函数
2)常用函数介绍
1> re.search()

2> re.findall()函数

3> re.split()函数

4)re.search(), re.findall(), re.split()函数例子说明:
re.search():仅找到第一个符合正则表达式的字符串
re.findall():找到所有匹配正则表达式的字符串
re.split():割去匹配正则表达式的字符串,再以列表形式返回

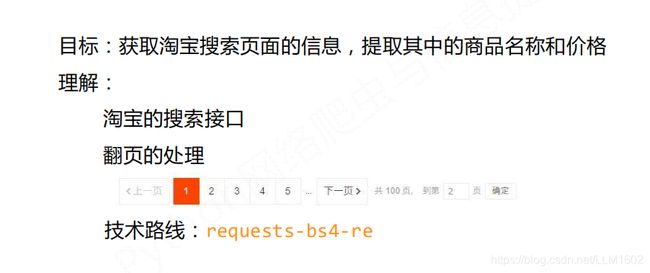
二、淘宝商品比价定向爬虫项目实战
1.网页介绍与预期想要的结果
淘宝书包链接

输入url链接后,输出如下图:

2.爬虫思路分析以及标签可行性分析
1)总体思路:
2)翻页处理:
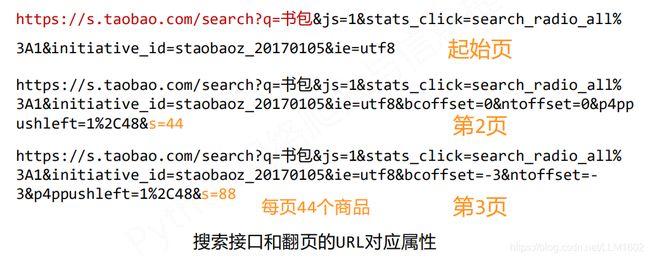
3)搜索匹配分析:
1> 先找到 “raw_title”:“电视剧款JanSport杰斯伯2020年新款双肩包时尚潮女书包男电脑背包”,即刻获得书包名字
2> 再找到 “view_price”:“199.00” , 即可获得相应价格

3.程序分析

4.代码展示
import requests
import re
def getHTMLText(url):
try:
header = {
"user-agent":"填你自己的user-agent,第五点有教去如何找到",
"cookie":"填你自己的cookie"
}
#淘宝页面会有登录验证,因此需要先登录,进去再按F12,复制uesr-agent和,cookie
r = requests.get(url,timeout = 30,headers = header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
#在匹配一些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。
#匹配到"view_price -> \"view_price
#匹配到" -> \"
#匹配到: -> \:
#匹配到" -> \"
#匹配数字190.00类似这种 -> [\d\.]*
# 匹配到" -> \"
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
#eval() 函数用来执行一个字符串表达式,并返回表达式的值。
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
print("")
def main():
goods = "书包"
depth = 2#页面数量
start_url = "https://s.taobao.com/search?q=" + goods
infolist = []
for i in range(depth):
try:
url = start_url+ "&s=" + str(44*i)#翻页设计
html = getHTMLText(url)
parsePage(infolist, html)
except:
continue
printGoodList(infolist)
main()
5.代码几个点需要注意的地方:
1)首先需要自己先在网页登录上淘宝账号,按F12,点network,刷新后,找到search 开头那个,点开,去找到cookie,和 user-agent,方法见下图:

2)在匹配一些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。例如匹配单引号 " 就应 "
三、股票数据定向爬虫项目实战
1.网页介绍与预期想要的结果
1)股票网址链接,从这里获得6位数字代码

2)再从这里获得股票的具体相关信息
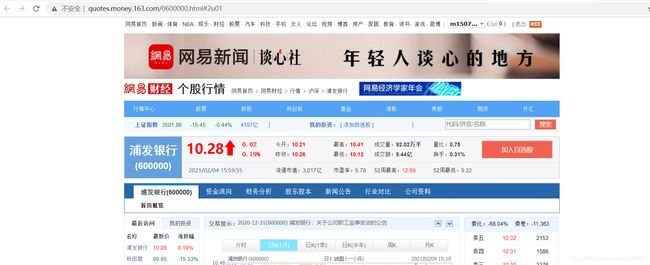
3)输入url链接后,输出如下图:

2.爬虫思路分析以及标签可行性分析
1)总体思路:

2):标签分析
1> 先找到/gs/sh_600000.shtml,然后得到6位数字,

2> 找到相应的单股的信息标签:
再用BeautifulSoup找到最近的div class = relate_stock的标签,再找到第一个script标签,然后获取里面的字符串,再用正则表达式对字符串进行提取。

3.程序步骤

4.代码展示
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):
try:
r = requests.get(url , timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
try:
plt = re.findall(r'/gs/sh_\d{6}',html)
for i in plt:
lst.append(i.split('_')[1])
print(lst)
except:
print("")
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + "0" +stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {
} #暂时存储当前股票的所有信息
soup = BeautifulSoup(html,"html.parser")
stockinfo = soup.find('div',attrs={
'class':'relate_stock clearfix'})
dict = stockinfo.find_all('script')[0]
info = dict.string#转化成字符串了
infoDict['股票名称'] = eval(re.search(r'name\: \'.*\'', info).group(0).split(':')[1])
infoDict['股票代码'] = eval(re.search(r'code\: \'\d{6}\'', info).group(0).split(":")[1])
infoDict['现价'] = eval(re.search(r'price\: \'.*\'', info).group(0).split(":")[1])
infoDict['涨跌幅'] = re.search(r'change\: \'.*%', info).group(0).split("'")[1]
infoDict['昨收'] = eval(re.search(r'yesteday\: \'.*\'', info).group(0).split(":")[1])
infoDict['今开'] = eval(re.search(r'today\: \'.*\'', info).group(0).split(":")[1])
infoDict['最高'] = eval(re.search(r'high\: \'.*\'', info).group(0).split(":")[1])
infoDict['最低'] = eval(re.search(r'low\: \'.*\'', info).group(0).split(":")[1])
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count + 1
print('\r当前速度:{:.2f}%'.format(count * 100 / len(lst)), end='')
except:
count = count + 1
print('\r当前速度:{:.2f}%'.format(count * 100 / len(lst)), end='')
traceback.print_exc()
continue
def main():
stock_list_url = 'http://quote.stockstar.com/stock/stock_index.htm'
stock_info_url = 'http://quotes.money.163.com/'
output_file = "D://BaiduStockInfos111.txt"
slist = []
print(111)
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
print(5555)
main()
5.代码几个点需要注意的地方:
1)在具体股票页面用BeautifulSoup,爬取到script后,用.string 获取里面的列表,但此时全部转化为一个字符串,因此后面用正则表达式提取想要的信息。