Python爬虫入门学习(一):requests库安装和使用
首先讲一下爬虫原理:其实就是爬取我们想要抓取信息的网页,从所爬到的网页代码中提取出我们想要获取的信息,这就需要我们掌握基本的html,能大概看得懂html即可。这时,我们需要用到requests库,就是发起请求访问一个网页(填写对应的url),它能够很快的获取到html源文件,然后从中筛选出我们想要的内容,即为爬虫的基本原理。
一、requests库安装(Window系统):
1.1 首先得知道目前python装在哪里
在cmd输入where python
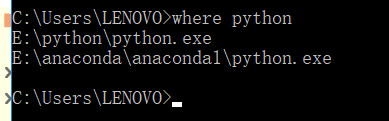
1.2 通过cmd进入该python目录的scripts文件夹

1.3输入pip install requests命令
在输入命令前,先进目录看一下有没有安装pie.exe
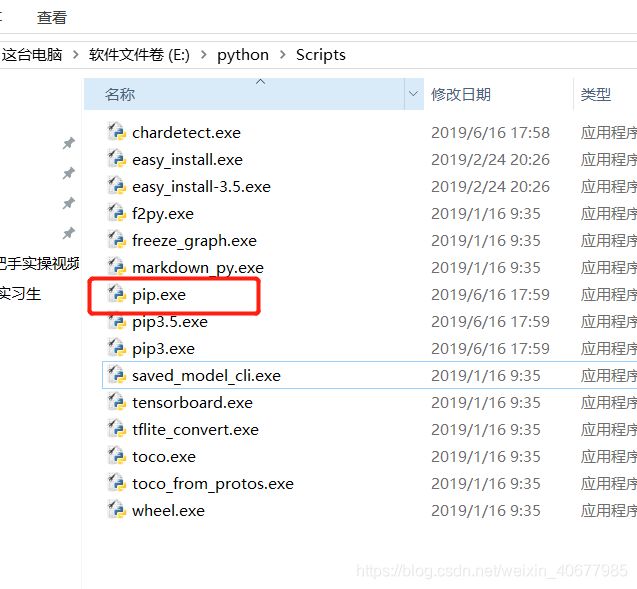
有安装的话,即可输入pip install requests命令,然后耐心等候安装

安装成功后会有提示requests库的版本号(requests-2.22.0),同时也可以选择更新一下pip,命令:python -m pip install --upgrade pip
二、requests库的使用(推荐使用的ide为PyCharm)
2.1 创建新的py文件
#首先我们导入requests这个包
import requests
#把百度首页的html源码抓取到本地,用r变量保存
r=requests.get("http://www.baidu.com")
#打印获取到的html源码
print(r.text)
结果:
爬到了百度首页的html源码,这里的抓取,其实是用到request库的get方法,是比较常用的一种方法,输入参数为url地址,返回一个response对象

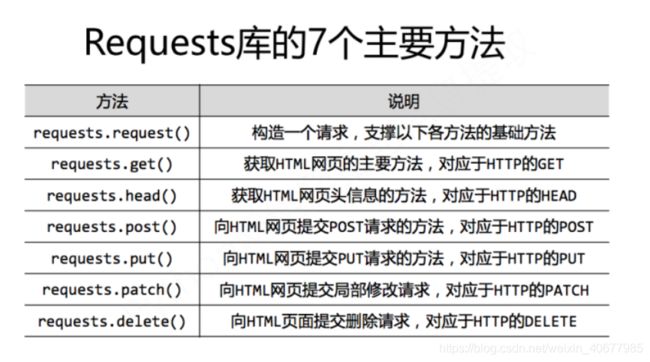
2.2 requests主要方法的了解
2.3 requests.get()的进一步用法
requests.get(url,params,**kwargs)可以接收三个参数
url: 即为所要爬取的网页地址
params: 默认为none,可以不填,表示字典或字节流格式
**kwargs:控制访问的参数,均为可选项
十三个控制访问参数如下:
params : 字典或字节序列,作为参数增加到url中
data : 字典、字节序列或文件对象,作为Request的内容 json : JSON格式的数据,作为Request的内容
headers : 字典,HTTP定制头
cookies : 字典或CookieJar,Request中的cookie
auth : 元组,支持HTTP认证功能
files : 字典类型,传输文件
timeout : 设定超时时间,秒为单位
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认为True,获取内容立即下载开关
verify : True/False,默认为True,认证SSL证书开关
cert : 本地SSL证书路径
json: JSON格式的数据,Request的内容
实例:
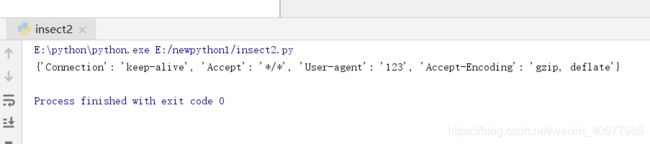
在get请求中自定义一个header头文件:
import requests
hd={'User-agent':'123'}
r=requests.get('http://www.baidu.com',headers=hd)
print(r.request.headers)结果:
2.4 requests抓取网页的通用框架
import requests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30)
# 如果状态码不是200,则应发HTTOError异常
r.raise_for_status()
# 设置正确的编码方式
r.encoding = r.apparent_encoding
return r.text
except:
return "Something Wrong!"