基于深度特征分解的红外和可见光图像融合
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
红外和可见图像融合是图像处理领域中的热门话题,旨在获得融合了源图像优势的融合图像。本文提出了一种新颖的基于自编码器的融合网络模型。核心思想是,编码器将图像分别分解为具有低频和高频信息的背景和细节特征图,并且解码器恢复原始图像。为此,损失函数通过使源图像的背景/细节特征图相似/不相似完成特征信息的分离。在测试阶段,通过融合模块分别合并背景特征图和细节特征图,并通过解码器恢复融合后的图像。定性和定量结果表明,我们的方法可以生成包含显著目标信息和丰富细节纹理信息的融合图像,在超越现有方法的同时具有很强的可复现性。

赵子祥:西安交通大学数学与统计学院一年级博士,研究方向为底层视觉,图像增强,信息融合,于2018年本科毕业后硕博连读,师从张讲社教授。主要工作发表在 IJCAI, Signal Processing上。

一、图像融合背景

图像融合主要指现实生活中使用不同成像设备对同一场景下的同一物体的不同成像图像进行信息融合的过程。比较有代表性的图像融合有以下4个任务:
(1)多焦点或者多曝光的图像融合;
(2)红外与可见光的图像融合(本文的主要工作);
(3)医学上 MRI和CT的图像融合;
(4)常用于遥感的全色锐化和多光谱的图像融合。

本文的主要工作集中于红外与可见光的图像融合。对于红外光,其具有较强的穿透力,不受光照的限制,不受天气环境的限制等优点。对于可见光,其具有极强的纹理和细节信息,较高的空间分辨率。但是其对于较差的光照环境,例如雨天、雾天或弱光情况下无法完成清晰成像和表征。因此理想的情况是同时具有红外光的可穿透性、目标的辐射信息和可见光的纹理信息和细节信息梯度等的优点,生成一张融合图像实现对目标的准确清晰的认知。
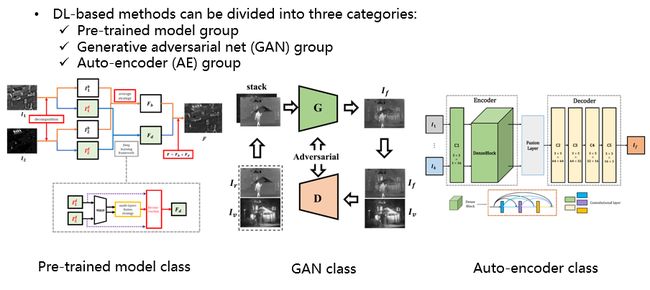
目前存在的图像融合方法主要可以分为两大类:
第一部分是传统方法,可以分出以下几类:多尺度分解方法,稀疏表征方法,基于显着度的图像融合和贝叶斯方法的融合等。第二类方法是深度学习的方法,主要分成以下三类:预训练模型类,生成对抗模型类和自编码类。
本文的工作借鉴了深度学习中第一类和第三类的优点,通过auto-encoder结构提取图像不同尺度的信息,即base feature和 detail feature。提取base feature和 detail feature的过程完全由深度学习的方法进行分解,而不是通过一些传统方法。
二、模型设计

以下是本文的具体工作。在Training中,encoder部分主要用于分离背景信息和细节信息,具体训练过程如上图所示,I代表的是输入的红外训练样本,V代表的是可见光训练样本。经过上述的网络框架之后,输入的图像I进入 decoder,完成特征分解之后,输出红外base信息BI和 detail信息DI。而图像V分别得到相应的 BV和DV。之后将BI和DI通过融合,再通过decoder获得重构图像,并且希望获得的重构于源图足够接近。

本文的total loss由两部分组成,第一部分是Image decomposition,第二部分是Image Reconstruction。在Image decomposition中通过梯度下降使得BV和BI更为接近,使得DV和DI差距变大,实现了特异性的特征分离。在Image Reconstruction中,通过I和I’,V和V’,以及▽V和▽V’的全变差惩罚,使其可以重构原图像。
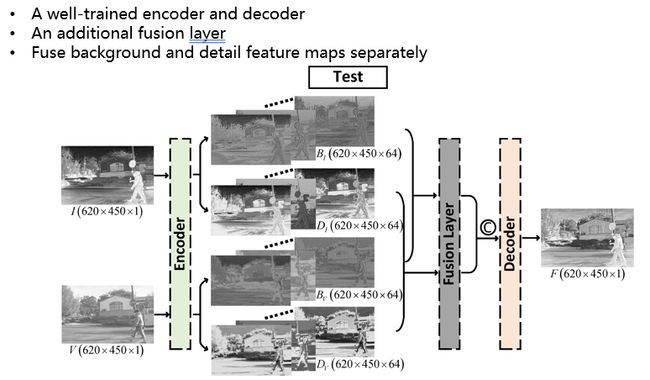
经过训练,模型获得了训练好的encoder和decoder,然后进入测试阶段。在测试过程中,添加一个fusion layer,即融合层,实现BI和BV的融合,DI和DV的融合,然后把其进行拼接,输入decoder实现图像重构。
以一张红外图像作为例子输入,其是大小为620×450×1。图像在base层和detail层均被分解成为64维的高维特征。可见光图像同样被分解为64维的高维特征。因此BI和BV变成了620×450×64大小,DI和DV也变成了620×450×64大小。之后通过训练好的decoder实现对feature map的重构过程,即最终输出的融合图像过程。

在测试过程中添加的fusion layer的公式具体如上。对于融合策略的选择有以下三种策略:直接相加、给定权重相加和L1-norm(把feature map的L1范数看作其activity measurement,然后通过计算不同feature map的L1-norm来给定不同融合权重)。
三、实验验证及对比

上图是feature map分解可视化。可以看到的是对于输入的图像I和图像V,其BI和BV比较相似,都代表了各自的背景图像,而DI和DV的差异较大,分别代表了各自的特有信息,纹理信息或者高频变化的信息。因此可以认为本文的方法具有一定的可解释性。

之后使用了红外和可见光图像融合数据集上进行了测试,使用了TNO数据集,FLIR数据集和NIR数据集。结果对比可以看到,不管是在对于前景目标的突出度和高量信息的维持上,还是对于背景纹理信息的保存上,本文的方法在众多的测试方法中有着优异的表现。
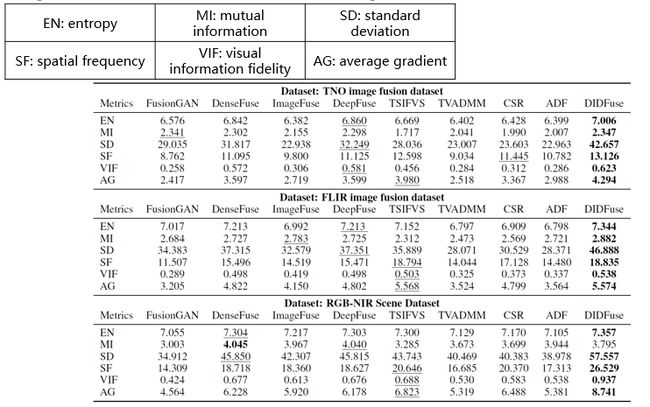
然后通过对数据的定量对比,因为本文的任务属于无监督任务,所以可以使用以下6个指标完成对于融合图像的比较:EN、MI、SD、SF、VIF和AG。
可以看出有与其他的方法相比,本文的方法在这6个指标上均有着较好的表现。证明该方法不论是对于原图像信息的保留,还是对高亮信息的表征和低频信息的保存都有着较好的发挥。
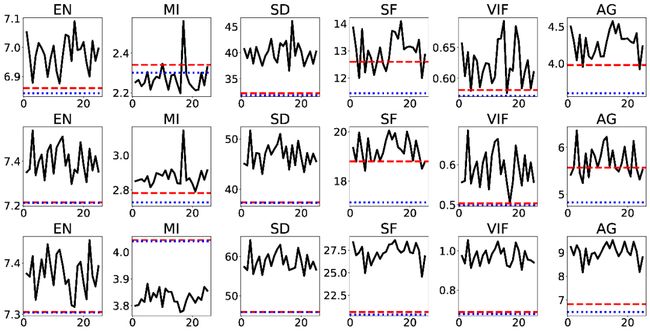
最后的实验是为了验证模型的可复现性,平行训练了模型25次,将6个指标和其他的方法进行对比。红色的虚线代表的是对比方法中最好的结果,蓝色的曲线代表是第二好的结果。本文的方法基本可以认为优于其他的对比方法,证明具有较强的复现性。
四、总结
总之,本文的工作将特征融合任务拆分成为特征分解任务,然后对于不同的特征分解做分步融合。本模型有效的利用了先验信息,即base信息代表着大尺度的背景信息, detail信息是互异性较明显的信息。先验信息的应用对于融合任务有着一个较好的改变提升。
论文链接:
https://www.ijcai.org/Proceeding/2020/135
整理:闫 昊
审稿:赵子祥
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(直播回放:https://b23.tv/uBNeLm)
(点击“阅读原文”下载本次报告ppt)