SSD算法pytorch实现复现结果记录(附个人修改后的完整源代码)
如题。
首先声明,本次实验所用源代码修改自源代码,本人修改的源代码附在博文最后。
SSD300,迭代次数:55000。
下面是最终验证测试集的结果。
Evaluating detections
Writing aeroplane VOC results file
/home/river/code/Python/ssd.pytorch-master/eval.py:153: DeprecationWarning: elementwise comparison failed; this will raise an error in the future.
if dets == []:
Writing bicycle VOC results file
Writing bird VOC results file
Writing boat VOC results file
Writing bottle VOC results file
Writing bus VOC results file
Writing car VOC results file
Writing cat VOC results file
Writing chair VOC results file
Writing cow VOC results file
Writing diningtable VOC results file
Writing dog VOC results file
Writing horse VOC results file
Writing motorbike VOC results file
Writing person VOC results file
Writing pottedplant VOC results file
Writing sheep VOC results file
Writing sofa VOC results file
Writing train VOC results file
Writing tvmonitor VOC results file
VOC07 metric? Yes
AP for aeroplane = 0.7482
AP for bicycle = 0.8164
AP for bird = 0.6917
AP for boat = 0.6405
AP for bottle = 0.3980
AP for bus = 0.8041
AP for car = 0.8040
AP for cat = 0.8572
AP for chair = 0.5270
AP for cow = 0.7927
AP for diningtable = 0.7147
AP for dog = 0.8265
AP for horse = 0.8250
AP for motorbike = 0.7983
AP for person = 0.7366
AP for pottedplant = 0.4017
AP for sheep = 0.6665
AP for sofa = 0.7664
AP for train = 0.8302
AP for tvmonitor = 0.7103
Mean AP = 0.7178
~~~~~~~~
Results:
0.748
0.816
0.692
0.641
0.398
0.804
0.804
0.857
0.527
0.793
0.715
0.826
0.825
0.798
0.737
0.402
0.667
0.766
0.830
0.710
0.718
~~~~~~~~
--------------------------------------------------------------
Results computed with the **unofficial** Python eval code.
Results should be very close to the official MATLAB eval code.
--------------------------------------------------------------

图 1

图 2

图 3

图 4

图 5

图 6

图 7

图 8
将迭代次数增加到60000。
SSD300,迭代次数:60000。
下面是最终验证测试集的结果。
Evaluating detections
Writing aeroplane VOC results file
/home/river/code/Python/ssd.pytorch-master/eval.py:153: DeprecationWarning: elementwise comparison failed; this will raise an error in the future.
if dets == []:
Writing bicycle VOC results file
Writing bird VOC results file
Writing boat VOC results file
Writing bottle VOC results file
Writing bus VOC results file
Writing car VOC results file
Writing cat VOC results file
Writing chair VOC results file
Writing cow VOC results file
Writing diningtable VOC results file
Writing dog VOC results file
Writing horse VOC results file
Writing motorbike VOC results file
Writing person VOC results file
Writing pottedplant VOC results file
Writing sheep VOC results file
Writing sofa VOC results file
Writing train VOC results file
Writing tvmonitor VOC results file
VOC07 metric? Yes
AP for aeroplane = 0.7648
AP for bicycle = 0.7917
AP for bird = 0.7051
AP for boat = 0.6443
AP for bottle = 0.4094
AP for bus = 0.7996
AP for car = 0.8169
AP for cat = 0.8645
AP for chair = 0.5346
AP for cow = 0.7238
AP for diningtable = 0.7107
AP for dog = 0.8319
AP for horse = 0.8321
AP for motorbike = 0.7983
AP for person = 0.7390
AP for pottedplant = 0.4255
AP for sheep = 0.6984
AP for sofa = 0.7715
AP for train = 0.8371
AP for tvmonitor = 0.7333
Mean AP = 0.7216
~~~~~~~~
Results:
0.765
0.792
0.705
0.644
0.409
0.800
0.817
0.864
0.535
0.724
0.711
0.832
0.832
0.798
0.739
0.426
0.698
0.772
0.837
0.733
0.722
~~~~~~~~
--------------------------------------------------------------
Results computed with the **unofficial** Python eval code.
Results should be very close to the official MATLAB eval code.
--------------------------------------------------------------

图 9

图 10

图 11

图 12

图 13

图 14

图 15
本次实验的损失值随迭代次数的变化趋势如图16所示。

图 16 损失值与迭代次数的关系
我修改了一下multibox_loss.py里面的forward函数,和网上主流介绍的稍微不同(我按照他们那么说的改,训练出的模型在运行test.py测试时,只能得到预测框的位置但没有预测的标记结果;运行eval.py时只是扫了一遍图片,没有給出任何信息;运行live.py时只是输出了原图)。如下所示。
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
pos = conf_t > 0
num_pos = pos.sum(dim=1, keepdim=True)
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c = loss_c.view(num, -1)
loss_c[pos] = 0 # filter out pos boxes for now
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
# N = num_pos.data.sum()
# N = num_pos.data.sum().double()
loss_l = loss_l.double() # delete or remain?
loss_c = loss_c.double() # delete or remain?
# loss_l /= N # delete or remain?
# loss_c /= N # delete or remain?
return loss_l, loss_c
网上主流的改法似乎(因为个人感觉都语焉不详)是下面这样的。
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
pos = conf_t > 0
num_pos = pos.sum(dim=1, keepdim=True)
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c = loss_c.view(num, -1)
loss_c[pos] = 0 # filter out pos boxes for now
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
# N = num_pos.data.sum()
N = num_pos.data.sum().double()
loss_l = loss_l.double() # delete or remain?
loss_c = loss_c.double() # delete or remain?
loss_l /= N # delete or remain?
loss_c /= N # delete or remain?
return loss_l, loss_c
区别就是有没有
N = num_pos.data.sum().double()
以及
loss_l /= N # delete or remain?
loss_c /= N # delete or remain?
看到不少大佬都这么写“修改第114行为……”,但我不明白的是直接替换掉第144行的代码,还是顺便把
loss_l /= N # delete or remain?
loss_c /= N # delete or remain?
也删了。
也就是,到底是改成:
N = num_pos.data.sum().double()
loss_l = loss_l.double()
loss_c = loss_c.double()
loss_l /= N
loss_c /= N
return loss_l, loss_c
还是改为:
N = num_pos.data.sum().double()
loss_l = loss_l.double()
loss_c = loss_c.double()
return loss_l, loss_c
我承认:无法理解大佬们的表达是因为我笨。
但是,我还是觉得这描述模棱两可。

图 17

图 18
图17和图18都是截至两个大佬描述的步骤,点击图号即可跳转至对应页面。
前面说过,按照他们的修改我得不到预期的实验结果。(可能是我操作有误或者理解错了大佬们的描述~)
按照他们的改法,得到的损失函数值随迭代次数的变化趋势似乎更“好看”一点,如图19所示。
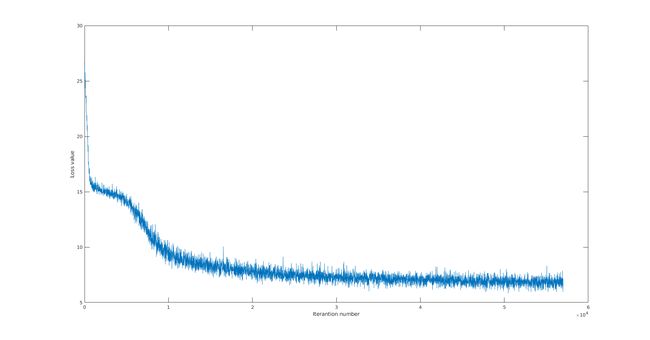
图 19
最后附上我所用的修改后的源代码。
链接