【NLP】1安装gensim库与斯坦福大学CS224n第一次课代码复现
Gensim word vector visualization
- 1. 安装gensim库
- 2. word2vec实例
- 小结
1. 安装gensim库
打开命令行,输入:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
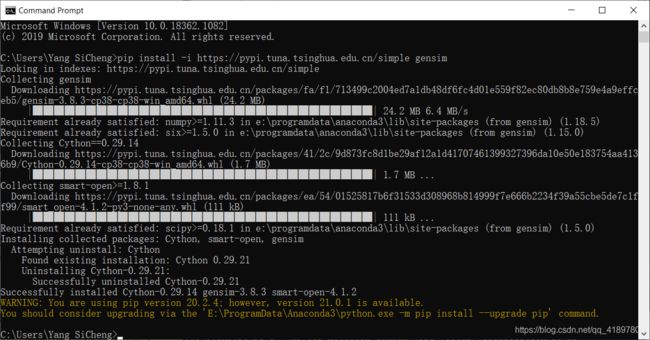
安装好了可以在默认安装路径下(本人为Anaconda3)找到这两个包:
2. word2vec实例
根据之前斯坦福大学深度学习自然语言处理课程,从以下链接可以下载Gensim word vector visualization,从以下链接下载Assignment 1
解压Gensim,在文件夹下得到“Gensim word vector visualization.ipynb”,win10按“shift+ctrl+右键”,点“Open PowerShell Window Here”在当前文件夹下打开命令行,输入:
jupyter notebook
打开“Gensim word vector visualization.ipynb”
用Gensim看词向量,我们在作业1中也用它来处理词向量。Gensim并不是一个真正的深度学习包,它是一个用于单词和文本相似性建模的包,它从(LDA式的)主题模型开始,发展到SVD和神经单词表示。但其效率高,可扩展性强,应用相当广泛。
我们斯坦福提供的是GloVe词向量。Gensim并没有给它们一流的支持,但允许你把GloVe向量的文件转换成word2vec格式。你可以从Glove页面下载GloVe向量。它们在这个压缩文件中
(我用下面的100d向量是为了兼顾速度和小与质量。如果你试一下50d向量,它们基本可以满足相似性的要求,但对于类比问题显然没有那么好。如果你加载300d向量,它们甚至比100d向量更好)
先下载一下GloVe vectors,解压后,打开长这样:

完整代码:
from gensim.test.utils import datapath, get_tmpfile
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot') # 设置背景样式(bmh, classic, dark_background, seaborn, grayscale, Solarize_Light2)
def analogy(model, x1, x2, y1):
result = model.most_similar(positive=[y1, x2], negative=[x1])
print(result[0][0])
return result[0][0]
def display_pca_scatterplot(model, words=None, sample=0):
if words == None:
if sample > 0:
words = np.random.choice(list(model.vocab.keys()), sample)
else:
words = [word for word in model.vocab]
word_vectors = np.array([model[w] for w in words])
twodim = PCA().fit_transform(word_vectors)[:,:2]
plt.figure(figsize=(6,6))
plt.scatter(twodim[:,0], twodim[:,1], edgecolors='k', c='r')
for word, (x,y) in zip(words, twodim):
plt.text(x+0.05, y+0.05, word)
plt.show()
def main():
glove_file = datapath('...your path/glove.6B/glove.6B.100d.txt')
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt")
glove2word2vec(glove_file, word2vec_glove_file)
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
print(model.most_similar('obama'))
print(model.most_similar('banana'))
print(model.most_similar(negative='banana'))
result = model.most_similar(positive=['woman', 'king'], negative=['man'])
print("{}: {:.4f}".format(*result[0]))
analogy(model, 'japan', 'japanese', 'australia')
analogy(model, 'australia', 'beer', 'france')
analogy(model, 'obama', 'clinton', 'reagan')
analogy(model, 'tall', 'tallest', 'long')
analogy(model, 'good', 'fantastic', 'bad')
print(model.doesnt_match("breakfast cereal dinner lunch".split()))
display_pca_scatterplot(model,
['coffee', 'tea', 'beer', 'wine', 'brandy', 'rum', 'champagne', 'water',
'spaghetti', 'borscht', 'hamburger', 'pizza', 'falafel', 'sushi', 'meatballs',
'dog', 'horse', 'cat', 'monkey', 'parrot', 'koala', 'lizard',
'frog', 'toad', 'monkey', 'ape', 'kangaroo', 'wombat', 'wolf',
'france', 'germany', 'hungary', 'luxembourg', 'australia', 'fiji', 'china',
'homework', 'assignment', 'problem', 'exam', 'test', 'class',
'school', 'college', 'university', 'institute'])
display_pca_scatterplot(model, sample=300)
if __name__ == '__main__':
main()
运行程序,结果:
[('barack', 0.937216579914093), ('bush', 0.9272854328155518), ('clinton', 0.8960003852844238), ('mccain', 0.8875634074211121), ('gore', 0.8000321388244629), ('hillary', 0.7933663129806519), ('dole', 0.7851964235305786), ('rodham', 0.7518897652626038), ('romney', 0.7488930225372314), ('kerry', 0.7472623586654663)]
[('coconut', 0.7097253799438477), ('mango', 0.7054824233055115), ('bananas', 0.6887733340263367), ('potato', 0.6629636287689209), ('pineapple', 0.6534532308578491), ('fruit', 0.6519854664802551), ('peanut', 0.6420576572418213), ('pecan', 0.6349173188209534), ('cashew', 0.629442036151886), ('papaya', 0.6246591210365295)]
[('keyrates', 0.7173939347267151), ('sungrebe', 0.7119239568710327), ('þórður', 0.7067720293998718), ('zety', 0.7056615352630615), ('23aou94', 0.6959497928619385), ('___________________________________________________________', 0.694915235042572), ('elymians', 0.6945434808731079), ('camarina', 0.6927202939987183), ('ryryryryryry', 0.6905654072761536), ('maurilio', 0.6865653395652771)]
queen: 0.7699
australian
champagne
nixon
longest
terrible
cereal
E:\ProgramData\Anaconda3\lib\site-packages\gensim\models\keyedvectors.py:877: FutureWarning: arrays to stack must be passed as a "sequence" type such as list or tuple. Support for non-sequence iterables such as generators is deprecated as of NumPy 1.16 and will raise an error in the future.
vectors = vstack(self.word_vec(word, use_norm=True) for word in used_words).astype(REAL)
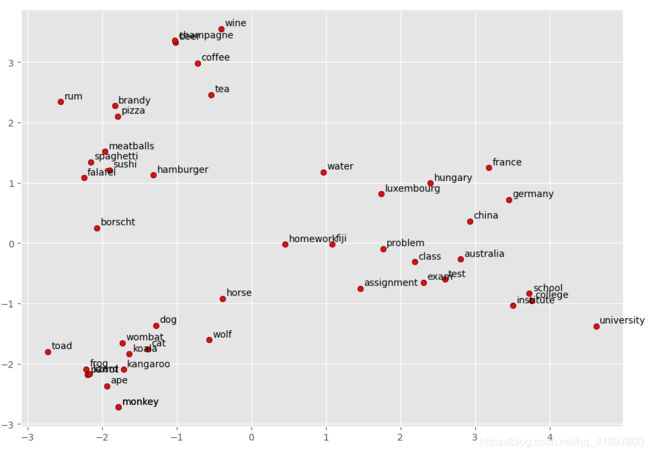
分析:
- 和’obama’最相似的是’barack’(贝拉克,Obama是名,barack是姓)、‘bush’、‘clinton’、‘mccain’……
- 和’banana’最相似的是’coconut’、‘mango’、‘bananas’、‘potato’……
- 和’obama’最不相似的是’keyrates’、‘sungrebe’、‘þórður’……
- famous King - Man + Woman example结果:queen: 0.7699
- ‘japan’, ‘japanese’, 'australia’结果:australian
- ‘australia’, ‘beer’, 'france’结果:champagne(香槟)
- ‘obama’, ‘clinton’, 'reagan(里根, 40th President of the United States (1911-2004))'结果:nixon(尼克松, 37th President of the United States)
- ‘tall’, ‘tallest’, 'long’结果:longest
- ‘good’, ‘fantastic’, 'bad’结果:terrible
- "breakfast cereal dinner lunch"最不相似的是:cereal
值得注意到的是:
model.most_similar(positive=['king', 'woman'], negative=['man'])
q = model['king'] - model['man'] + model['woman']
model.similar_by_vector(q)
两种方法得到的结果如下:
[('queen', 0.7515910863876343), ('monarch', 0.6741327047348022), ('princess', 0.6713887453079224), ('kings', 0.6698989868164062), ('kingdom', 0.5971318483352661), ('royal', 0.5921063423156738), ('uncrowned', 0.5911505818367004), ('prince', 0.5909028053283691), ('lady', 0.5904011130332947), ('monarchs', 0.5884358286857605)]
[('king', 0.8655095100402832), ('queen', 0.7673765420913696), ('monarch', 0.695580005645752), ('kings', 0.6929547786712646), ('princess', 0.6909604668617249), ('woman', 0.6528975963592529), ('lady', 0.6286187767982483), ('prince', 0.6222133636474609), ('kingdom', 0.6208546161651611), ('royal', 0.6090123653411865)]
king、queen…等词的余弦距离有明显的区别,原因:
most_similar:函数检索出 “king”、"woman "和 "man "对应的向量,并将其归一化后再计算king-man+woman
model.similar_by_vector:函数只调用model.most_similar(positive=[v])。因此,这种差异是由于most_similar的输入类型(字符串或向量)的行为不同
最后,当most_similar有字符串输入时,它会从输出中删除单词(这就是为什么“king”不会出现在结果中)
>>> un = False
>>> v = model.word_vec("king", use_norm=un) + model.word_vec("woman", use_norm=un) - model.word_vec("man", use_norm=un)
>>> un = True
>>> v2 = model.word_vec("king", use_norm=un) + model.word_vec("woman", use_norm=un) - model.word_vec("man", use_norm=un)
>>> model.most_similar(positive=[v], topn=6)
[('king', 0.8449392318725586), ('queen', 0.7300517559051514), ('monarch', 0.6454660892486572), ('princess', 0.6156251430511475), ('crown_prince', 0.5818676948547363), ('prince', 0.5777117609977722)]
>>> model.most_similar(positive=[v2], topn=6)
[('king', 0.7992597222328186), ('queen', 0.7118192911148071), ('monarch', 0.6189674139022827), ('princess', 0.5902431011199951), ('crown_prince', 0.5499460697174072), ('prince', 0.5377321243286133)]
>>> model.most_similar(positive=["king", "woman"], negative=["man"], topn=6)
[('queen', 0.7118192911148071), ('monarch', 0.6189674139022827), ('princess', 0.5902431011199951), ('crown_prince', 0.5499460697174072), ('prince', 0.5377321243286133), ('kings', 0.5236844420433044)]
小结
以上注意是利用glove转化为word2vec的形式进行的一系列操作,关于save、load等相关用法还未实践