使用 VisualDL 助力遥感影像地块分割 (PaddleX 篇)
-
本项目利用 PaddleX 以及 PaddleSeg 两个套件分别实现遥感影像地块分割;
-
更重要的是想给大家展示一下如何利用
VisualDL这个强大的可视化工具来辅助训练及调参;
这个工具非常好用,在模型训练中给了我很大的帮助,也希望看完本文之后这个工具能给你带来帮助,也希望大家能去GitHub给点一点star,让官方把这个工具做的越来越好

-
最近百度与CCF合作举办了遥感影像地块分割的比赛,希望该项目可以帮助大家提高成绩;
-
PaddleX 篇也即本篇的目的在于重点介绍VisualDL的Scalar、Image功能,以及如何利用它们来辅助我们的训练,其次会简单介绍一下VisualDL的其他功能; -
PaddleSeg 篇的目的在于重点介绍VisualDL的Graph、Histogram功能,以及如何利用它们来帮助我们进行网络模型结构的设计; -
两篇都是通过遥感影像地块分割为应用背景,在实战中体验如何应用
VisualDL
背景及工具介绍
- 遥感影像地块分割 旨在对遥感影像进行像素级内容解析,对遥感影像中感兴趣的类别进行提取和分类。也就是利用图像分割提取出图像中的房屋,水域,农田等用地类型,在城乡规划、防汛救灾等领域具有很高的实用价值
- PaddleX 是飞桨的全流程开发工具,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。总之就是用起来十分方便快捷,具体细节大家可以自行去 PaddleX Github 主页查看;
在遥感方面,PaddleX 也提供了相应的demo,我们今天的项目基于PaddleX的 RGB遥感影像分割 来做; - VisualDL 是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。支持标量、图结构、数据样本可视化、直方图、PR曲线及高维数据降维呈现等诸多功能,同时VisualDL提供可视化结果保存服务。具体细节大家可以自行去 VisualDL Github 主页查看;
环境安装
(1) 安装PaddleX
!pip install paddlex -i https://mirror.baidu.com/pypi/simple
(2) 安装VisualDL
!python -m pip install visualdl --upgrade -i https://mirror.baidu.com/pypi/simple
数据准备
-
该 demo 使用2015 CCF大数据比赛提供的高清遥感影像,包含5张带标注的RGB图像,图像尺寸最大有7969 × 7939、最小有4011 × 2470。
-
该数据集共标注了5类物体,分别是背景(标记为0)、植被(标记为1)、建筑(标记为2)、水体(标记为3)、道路 (标记为4)。
-
本案例将前4张图片划分入训练集,第5张图片作为验证集。
-
为增加训练时的批量大小,以滑动窗口为(1024,1024)、步长为(512, 512)对前4张图片进行切分,加上原本的4张大尺寸图片,训练集一共有688张图片。
-
在训练过程中直接对大图片进行验证会导致显存不足,为避免此类问题的出现,针对验证集以滑动窗口为(769, 769)、步长为(769,769)对第5张图片进行切分,得到40张子图片。
(1)我们在 work 目录下新建一个PaddleX文件夹,用来存放该项目与PaddleX相关的文件;创建好之后切换到PaddleX目录下作为当前工作目录;
%cd work/PaddleX/
(2)通过执行以下脚本即可下载数据集并一键完成上述数据处理(需要等待一段时间,会自动下载数据集并进行处理, 很快啊,大概2分钟)
我们下载的原始数据集压缩包为 ccf_remote_dataset.tar.gz,解压后的文件夹为 ccf_remote_dataset,处理后的数据集为 dataset
!python ./prepare_data.py
训练配置
-
在训练开始之前,我们需要设置使用的
增强策略,数据集,以及网络结构 -
我们在
PaddleX/visualize_transforms.py中实现了这些设置, -
下面没有直接执行脚本生成日志文件,而是将脚本中的各个部分抽取出来讲解了一下,训练之后的部分会直接运行写好的脚本。
(1)环境变量配置
# 用于控制是否使用GPU
# 说明文档:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html#gpu
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import matplotlib
matplotlib.use('Agg')
(2)设置增强策略
我们定义的数据增强操作包含RandomPaddingCrop、RandomHorizontalFlip、RandomVerticalFlip、Normalize等。
更多的数据增强策略,大家可以去查看PaddleX的在线文档
import paddlex as pdx
from paddlex.seg import transforms
# 定义训练和验证时的transforms
# API说明 https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/seg_transforms.html
train_transforms = transforms.Compose([
transforms.RandomPaddingCrop(crop_size=769),
transforms.RandomHorizontalFlip(prob=1),
transforms.RandomVerticalFlip(prob=1),
transforms.RandomBlur(prob=1), #这里概率参数设置为 1 是为了查看效果, 如果决定使用时请设置合适的概率
transforms.RandomRotate(rotate_range=35),
transforms.RandomDistort(brightness_prob=1, contrast_prob=1, saturation_prob=1, hue_prob=1),
transforms.Normalize()
])
eval_transforms = transforms.Compose(
[transforms.Padding(target_size=769), transforms.Normalize()])
(3)设置数据集
# 定义训练和验证所用的数据集
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-segdataset
train_dataset = pdx.datasets.SegDataset(
data_dir='dataset',
file_list='dataset/train_list.txt',
label_list='dataset/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.SegDataset(
data_dir='dataset',
file_list='dataset/val_list.txt',
label_list='dataset/labels.txt',
transforms=eval_transforms)
通过VisualDL-Image查看数据增强过程
-
在设置好增强策略及数据集之后,我们就可以使用
VisualDL-Image功能对数据增强过程进行可视化,从而查看我们选择的增强策略是否达到了我们预期的效果。 -
运行以下命令将这些可视化结果保存为VisualDL能够识别的日志文件:
pdx.transforms.visualize(train_dataset, #数据集读取器
img_count=4, #需要进行数据预处理/增强的图像数目
save_dir='output/deeplabv3p_mobilenetv3_large_ssld/vdl_out') #日志保存的路径
如果是在Aistudio上运行本项目,
则点击左侧面板的可视化->设置logdir->添加->
选择日志目录output/deeplabv3p_mobilenetv3_large_ssld/vdl_out/vdl_out/image_transforms/->
启动VisualDL服务 -> 打开VisualDL,
打开VisualDL面板后,点击上方标签样本数据 -> 样本数据-图像即可。
下面第一行是原图,第二行是做了 RandomPaddingCrop 的可视化结果:
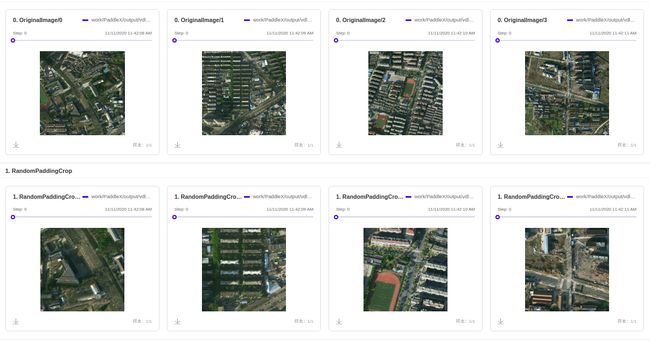
从可视化结果中看出,经过RandomPaddingCrop后,图像的局部信息被放大,
我们crop出了一块 769*769 的区域,这样的好处是可以减小显存压力,不同于resize, resize 的时候会使图像形变,但坏处也很明显,就是丢失了一部分图像信息,被我们crop掉的图像信息都没有了。
下面第一行是 RandomRotate 后的结果,第二行是 RandomDistort 后的结果:
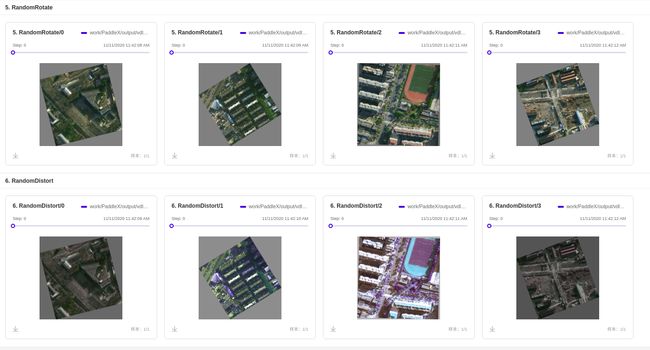
可以看出 RandomRotate 在我们设定的角度内进行旋转,有时候旋转的会很大,有时候几乎没有动;
最后这个 RandomDistort 随机像素替换看起来效果就不怎么好了,尤其是图三,要用这种增强方式的话,最好使用VisualDL的可视化功能来辅助你调整参数,从而避免出现这种情况;
更多的图片我就不展示了,通过VisualDL的这个功能是不是能对数据增强有了更深的理解呢?
具体选用什么增强策略,还是要结合实际情况来进行选择,如果你希望模型能在某个特定数据集上取得很好的效果,那么就可以通过观察该数据集的特征,然后尽量让训练集通过数据增强来尽可能与该数据集特征保持一致;
模型训练
-
我们选择
DeepLabv3p作为网络结构,在train函数的参数中设置use_vdl=True即可使用VisualDL的功能,日志会保存在结果保存路径save_dir下的vdl_log文件夹下 -
这里的其它参数如
train_batch_size和learning_rate首先要在显存允许的范围内进行调整,并且要同步调整; -
如果报错
out of memory显存溢出,我们就调小batch_size, 并且同比例调小learning_rate, 一般是以2的幂次倍调整的; -
其次,
learning_rate的调整是非常关键的,设置不同的值完全会带来不同的效果,这时候我们就可以利用VisualDL-Scalar来观察loss曲线, 得到一个最优的学习率来提升我们模型的效果;
注意 : 你可以先不要运行此处的代码,先看看下面我是如何进行参数的调整的,之后再回来进行训练
## 初始化模型,并进行训练
## 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.html
num_classes = len(train_dataset.labels)
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/models/semantic_segmentation.html#paddlex-seg-deeplabv3p
model = pdx.seg.DeepLabv3p(
num_classes=num_classes,
backbone='MobileNetV3_large_x1_0_ssld',
pooling_crop_size=(769, 769))
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/models/semantic_segmentation.html#train
# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train(
num_epochs=300,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.005,
save_interval_epochs=30,
pretrain_weights='CITYSCAPES',
save_dir='output/deeplabv3p_mobilenetv3_large_ssld', #可视化结果保存在该目录的 vdl_log 文件夹下
use_vdl=True) #使用内置的VisualDL
通过VisualDL-Scalar查看训练过程
VisualDL-Scalar: 也就是启动服务后的标量数据,以图表形式实时展示训练过程参数,如loss、miou、accuracy。让用户通过观察单组或多组训练参数变化,了解训练过程,加速模型调优
注意: 下面是进行调整的过程,我在实验时并未调整上面的参数:save_dir 你如果想进行多组实验的对比,可以通过修改save_dir 来实现,而不必像我后面介绍的那样手动移动 log 文件
我们第一次选择num_epochs=5, train_batch_size=8, learning_rate=0.5,观察一下 loss 曲线;
训练5个epoch大概5分钟,之后类似上面查看增强效果的操作,设置 logdir 为 work/PaddleX/output/deeplabv3p_mobilenetv3_large_ssld/vdl_log
然后启动VisualDL服务,选择标量数据,我们就可以看到loss曲线了
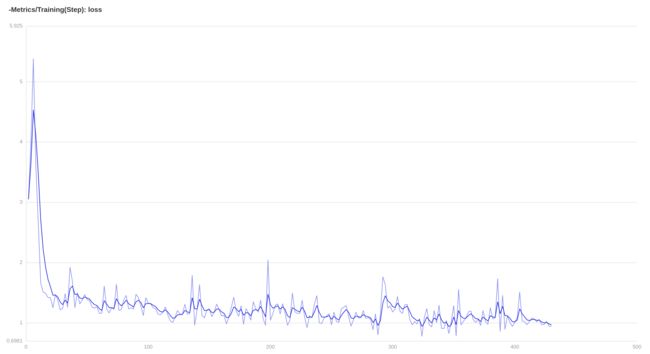
从上面的曲线中我们看到 loss 曲线在刚开始时有上扬的情况,这表明学习率过大,我们需要调小学习率并从头训练,
同时如果loss曲线频繁震荡,也是需要调小学习率的;
第二次我们设置 num_epochs=5, train_batch_size=8, learning_rate=0.0001
开始第二次训练时,你可能需要重启执行器来释放掉显存,重启执行器的操作:右上角 代码执行器 -> 重启执行器;
重启之后别忘记切换到工作目录,并进行训练前的一系列配置;安装PaddleX 及 VisualDL的步骤是不需要重复进行的;
5个epoch之后的loss曲线如下图所示:
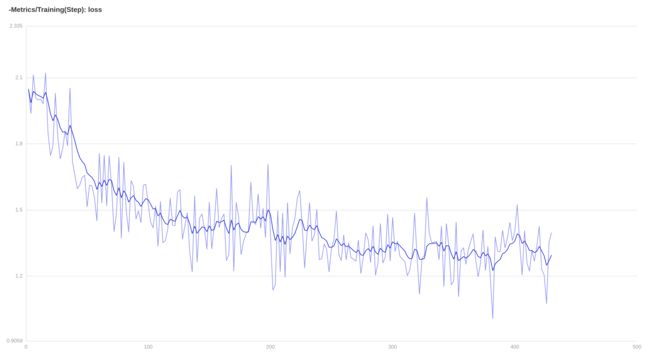
从上面的曲线中可以看到 在调小学习率之后,开始没有出现上扬的情况;
但可以发现,曲线收敛变慢了,与上一次相比 5 个 epoch 后,loss 还大于 1.2,并且下降趋势不明显;
这表明我们的学习率设置过小了,需要调大学习率并从头训练
我们第三次调整 num_epochs=10, train_batch_size=8, learning_rate=0.005
这次我们把三次的曲线放在一起对比一下,VisualDL-scalar 是支持多组实验对比的,
我们把日志放在三个文件夹下,并设置这三个文件夹为 logdir, 启动服务就可以看到了;
可以看到第三次的loss曲线已经比较好了,同时避免了前两次的缺点;勾选右侧仅显示平滑后数据,更清晰的做一下对比;
其中 蓝色为第一次学习率过大,绿色为第二次学习率过小,紫色为第三次学习率适中;
我们查看一下显存占用,发现大概15G左右,我们可以选择扩大 batch_size=16 ,同比例扩大 lr=0.01,大家可以自己体验一下;
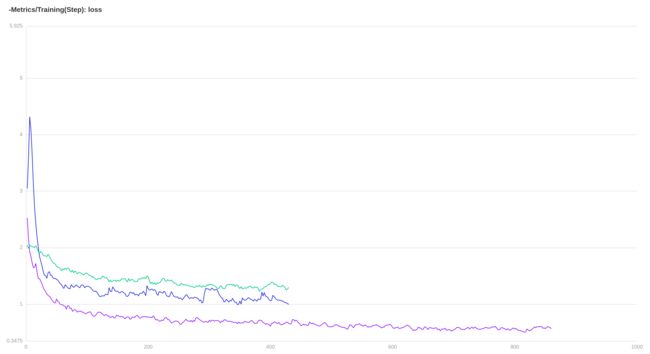
利用 VisualDL 我们在很短的时间内,就可以选择合适的增强策略,以及 lr 与 batch_size,让我们的模型有了一个好的开始,
下面我们正常开始训练,然后利用 VisualDL 的其他功能查看一下训练中的模型情况,以及最后的预测结果;
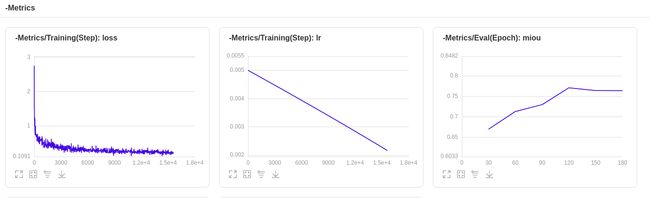
我设置 epoch_nums=300, save_interval_epochs=30,这样每过30个epoch就可以保存一个模型出来,
在训练的过程中,我们就可以将 vdl_log 设置为 logdir 来实时查看训练时的指标变化了;
虽然我设置了 一共训练300个epoch但是通过下图我们可以看到,在120个epoch之后,loss曲线与miou都已经趋于平缓了,所以我在epoch =181 时停止了训练;
利用VisualDL-Scalar,我们可以发现模型在什么时候达到了比较好的效果,从而可以及时终止训练,节省出大量的时间。
利用VisualDL-Image 查看预测结果
-
我们在训练时每30个epoch保存了一个模型,我们可以将这些模型的预测结果放在一起进行对比,也可以将单个模型的多张预测结果放在一起查看效果;
-
利用该功能进行横向纵向的对比,我们可以很快的调出我们最满意的模型,或者能够很快发现模型的问题;
-
下面提供的脚本接收 3 个参数:
第一个参数 model_save_dir 是模型保存的路径在哪里,vdl_log 也在这个文件夹下;最后我们的结果也会保存在该目录下的 vis_predict_log/ 下
第二个参数 epoch_name 是想查看的模型轮次,比如你想查看 epoch_30、 epoch_60 两个模型的效果,就可以设置 epoch_name='30 60'
第三个参数 pic_num 是每个模型想要查看的预测数量,我们会在 dataset/val_list.txt 随机取出这么多图片来进行预测,设置 pic_num=2 就会每个模型取两张图片来进行展示
- 但是注意
实际记录进去的图片,会按照某种均等算法进行采样,每个tag下,前端只会显示采样后的10张图片
如果你查看的模型数量超过了十个,虽然所有图像数据都会存储在日志的,但是显示的时候会进行采样,并不能同时查看你想查看的这十个模型的效果
你可以通过LogReader读出来当初你记录的所有图像数据;或者多次启动服务进行多次采样;或者每次仅保存十个模型的数据;都是很方便的!
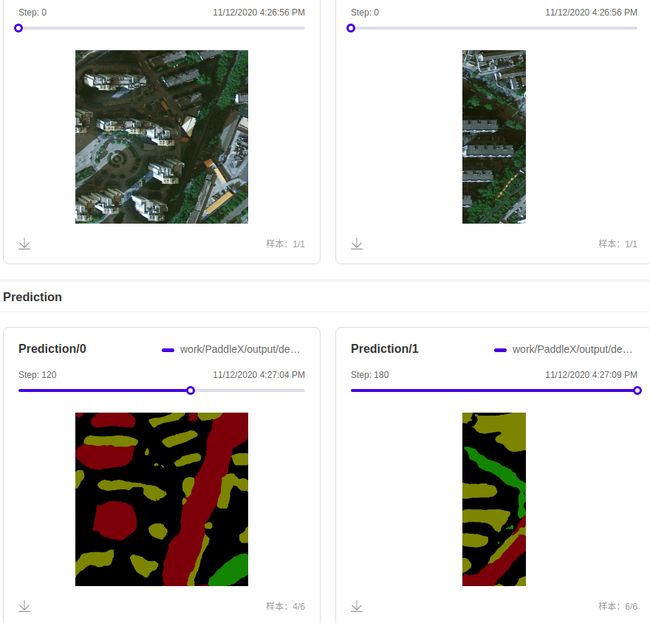
- 我选用了epoch_30 到 epoch_180 六个模型,每个模型选取了两张预测结果,执行下面的脚本后,启动服务进行查看:
这个脚本仅用了两行代码就完成了 VisualDL-Image 的使用,
vdl_writer = LogWriter(out_dir)在我们指定的路径创建一个记录器
vdl_writer.add_image(tag=tag, img=img, step=0)把我们想查看的图片记录下来
!python ./visualize_prediction.py --model_save_dir './output/deeplabv3p_mobilenetv3_large_ssld' --epoch_name '30 60 90 120 150 180' --pic_num 2
开启服务后,同样选择 样本数据 -> 样本数据-图像 进行查看,
第一行展示的为原图,第二行展示的为预测结果,
第二行图像可以选择不同的模型进行对比,其中step: 后面的数字就是你刚才输入的参数epoch_name
通过点击拖动条的不同区域,就可以对比不同模型的效果了
之后的这些功能我们只是在PaddleX 篇中简单体验一下,具体如何应用到我们的项目当中,请查看PaddleSeg 篇
通过 VisualDL-Graph 查看模型网络结构
-
这个功能用起来十分方便,
-
在本地使用时,开启VisualDL 服务后,直接把模型拖拽到
网络结构即可 -
在AIStudio 上,从左测标签栏里依次点击:
可视化->选择模型文件,找到我们的模型文件
work/PaddleX/output/deeplabv3p_mobilenetv3_large_ssld/best_model/model.pdmodel
-> 启动VisualDL服务
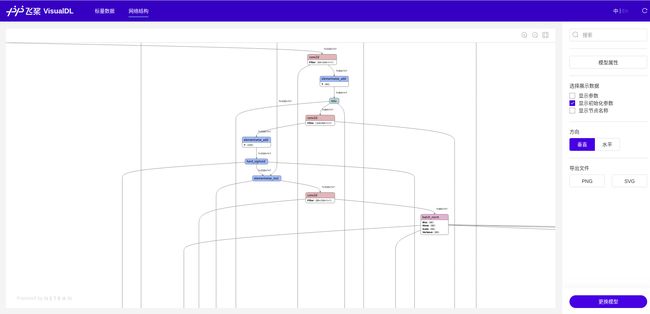
在启动服务后,点击网络结构,就能查看我们的模型结构了;
注意 :在打开比较大的模型时,速度会比较慢,电脑性能较差时,可能会卡死页面,建议在本地体验该功能;
下面是此次训练的模型结构图部分展示:
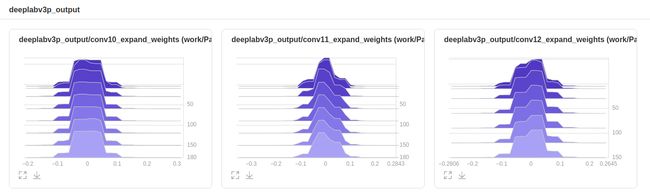
通过VisualDL-Histogram查看参数分布直方图
- 我们可以通过上面网络结构查看一些参数的名称,在下面脚本中替换
vis_var_names进行查看;这里选取了[‘conv10_expand_weights’, ‘conv11_expand_weights’, ‘conv12_expand_weights’] 三个参数来展示:
这个脚本仅用了两行代码就完成了 VisualDL-Histogram 的使用,
vdl_writer = LogWriter(vdl_save_dir)在我们指定的路径创建一个记录器
vdl_writer.add_histogram把我们想查看的参数直方图记录下来
!python visualize_params.py
然后我们点击左侧面板的可视化->设置logdir->添加->选择日志目录output/deeplabv3p_mobilenetv3_large_ssld/vdl_out/params_histogram/->启动VisualDL服务,打开VisualDL面板后,点击直方图。
可视化结果如下所示:
通过 VisualDL-Service 共享可视化结果
-
此功能是
VisualDL 2.0.4新添加的功能,只需要一行代码visualdl service upload即可以将自己的log文件上传到远端, -
非常推荐这个功能,我们上传文件之后,就不再需要在本地保存这些文件,直接访问生成的链接就可以了,十分方便!
-
如果你没有安装
VisualDL 2.0.4,你需要使用命令pip install visualdl==2.0.4安装 -
执行下面的代码之后,访问生成的链接, 我也将本项目过程中的某些 log 文件通过此功能上传到了云端, 有需要的话可以进行查看对比;
注意:当前版本上传时间间隔有 5min 的限制,上传的模型大小有100M的限制
!pip install visualdl==2.0.4
下面每一行代码下面的注释是对应的我在编写该项目时生成的链接,需要的话直接复制到浏览器就可以进行查看了!
执行代码时记得把 # 去掉
#!visualdl service upload --logdir ./output/deeplabv3p_mobilenetv3_large_ssld/vdl_log/
#训练过程日志: https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=5ed43118ce337581f73e7408b2e1bb41
#!visualdl service upload --logdir ./output/vdl_output/image_transforms/
#数据增强结果:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=d55259116534346fda66cf0d43353696
#!visualdl service upload --logdir ./output/deeplabv3p_mobilenetv3_large_ssld/vis_predict_log/
#预测结果对比:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=d087973f90ffb93f3ae2ba68d62d3d6e
#!visualdl service upload --model ./output/deeplabv3p_mobilenetv3_large_ssld/best_model/model.pdmodel
#模型结构:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=4e79096d61184b8833ce260efe705513
#!visualdl service upload --logdir ./output/deeplabv3p_mobilenetv3_large_ssld/vdl_out/params_histogram/
#模型参数直方图:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=6e085d445b640ff45b8c464d46c694ea
结束语
怎么样?VisualDL是不是很不错呢?快去Github上点点Star吧!
什么?你觉得不太行?点完Star, 去issue里吐槽一下吧,会彳亍起来的!
想深入了解一下其他功能? 来我的 PaddleSeg 篇看看吧!
觉得写得不错的话,互相点个关注吧,如果你觉得写的有问题,也欢迎在评论区指正!
参考链接:
VisualDL2.0–让PaddleX的模型训练『看』的见: https://aistudio.baidu.com/aistudio/projectdetail/954530