AI玩Flappy Bird│基于DQN的机器学习实例【持续更新中】
前言
Flappy Bird简介
《Flappy Bird》是一款由来自越南的独立游戏开发者Dong Nguyen所开发的作品,游戏于2013年5月24日上线,并在2014年2月突然暴红。2014年2月,《Flappy Bird》被开发者本人从苹果及谷歌应用商店撤下。2014年8月份正式回归APP STORE,正式加入Flappy迷们期待已久的多人对战模式。游戏中玩家必须控制一只小鸟,跨越由各种不同长度水管所组成的障碍。

简而言之,这是一款既简单又困难的游戏,游戏的操作方式很简单,但是想要获得非常高的分数还是一件很有挑战性的任务。如果让人类来获得一个比较高的分数,这几乎是不可能的事情。但是使用DQN来玩FlappyBird并通过上百万次的训练,拿到一个较高的分数甚至不死还是可以实现的。
为此,本人借助FlappyBird的源码进行一定程度的改写,简化了游戏机制,小鸟死亡后会立即开始下一轮游戏,并用Tensorflow基于DQN来实现AI玩FlappyBird。
DQN简介
Deep Q-Learning(DQN),通过在探索的过程中训练网络,最后所达到的目标就是将当前状态输入,得到的输出就是对应它的动作值函数,也即 f(s)=q(s,a),这个f就是训练的网络。
DQN有两个特性,Frozen Target Network和Experience Replay,大体框架可以理解为下图所示:
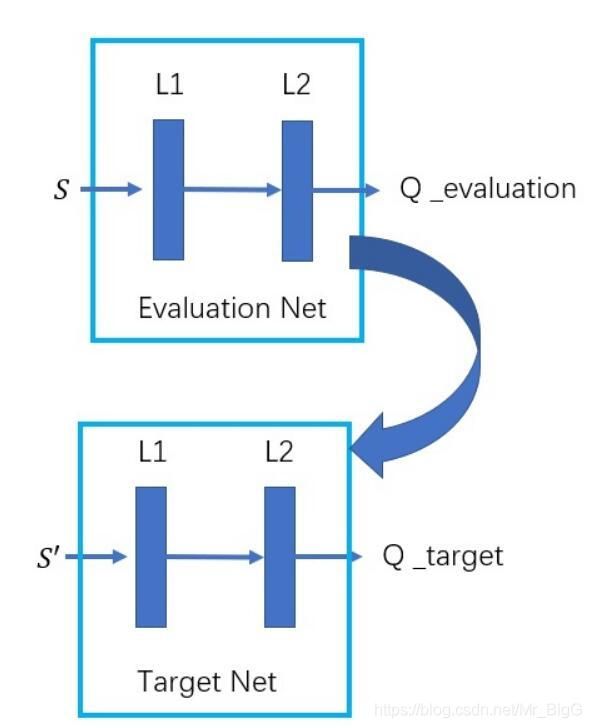
在EvaluationNet中进行训练,每进行多次训练以后,将训练后的权值等参数赋给TargetNet,所以在搭建targetNet网络时,不需要计算Loss和考虑Train过程,在EvaluationNet中的Loss计算方法为
![]()
我们在学习的过程中,会设定一个Memory空间,这个空间会记录好每一次的MDP过程,也即
- DQN伪代码

- DQN代码翻译与分析
初始化记忆体D中的记忆N
初始化随机权重θaction值的函数Q(Q估计)
初始化权重θ-=θ target-action值的函数^Q(Q现实)
循环:
初始化第一个场景s1=x1并且预处理场景s1对应的场景处理函数Φ
循环:
根据可能性ε选择一个随机动作at,or
或者选择一个最大值at从函数Q中在场景st下
执行动作a在模拟器中并且获取一个奖励rt和下一个场景xt+1
令st+1=st,at,xt+1并且处理Φt+1=Φ(st+1)
将(Φt,at,rt,Φt+1)存储在D中
采样一个随机的小批训练在D中
设置yj值:
如果 下一个场景yj+1是中止:则只返回rj
否则 返回rj+ (gamma ^Q(Φj+1,a,θ)函数最大a值的值)
#思路还是和Q-learning一样,如果有奖励则激励权重θ,如果每奖励则由gamma值来衰减权重θ
执行一个(Q现实-Q估计)平方梯度回归来更新权重θ
每执行多少步就执行一个^Q=Q(Q现实=Q估计,主要是权重拷贝)
项目源代码
游戏本体
FlappyBird的游戏本体的代码已经编写好了,是现成的,这里作者只提供游戏本体的源代码,下载即可,无需做过多的解释。
1.首先下载(提取码:BigG)所需的游戏本体等文件夹,然后将下载好的五个文件夹(assets、game、images、logs_bird、saved_networks)放到你的项目目录下,并确保这些文件夹和你的py源码文件是在同一目录下。
2.下载的文件夹中有一个名为saved_networks,这里保存着已经训练好的数据(训练次数为292万次),如果你想体验从零开始,也可以清空这个文件夹里面的数据只保留文件夹本身。
(PS:博主采用的VS2019开发环境,Python为3.8版本)
FlappyBird.py
上述工作完成后,就可以编写源代码来实现DQN玩FlappyBird了。程序所依靠的各类第三方库需要提前准备好,不会安装的可以自行百度pip命令来安装。
#!/usr/bin/env python
from __future__ import print_function
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import cv2
import sys
sys.path.append("game/")
import wrapped_flappy_bird as game
import random
import numpy as np
from collections import deque
GAME = 'bird' #日志文件的名字
ACTIONS = 2 #有效操作数
GAMMA = 0.99 #衰减率
OBSERVE = 100000. #前OBSERVE轮次,不对网络进行训练,只收集数据存到记忆库中
#第OBSERVE到OBSERVE+EXPLORE轮次中,对网络进行训练,且对epsilon进行退火,逐渐减小epsilon至FINAL_EPSILON
#当到达EXPLORE轮次时,epsilon达到最终值FINAL_EPSILON,不再对其进行更新
EXPLORE = 2000000. #上限
FINAL_EPSILON = 0.0001 #EPSILON的最终值
INITIAL_EPSILON = 0.0001 #EPSILON的初始值
REPLAY_MEMORY = 50000 #记忆库
BATCH = 32 #训练批次
FRAME_PER_ACTION = 1 #每隔FRAME_PER_ACTION轮次,就会有epsilon的概率进行探索
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.01)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.01, shape = shape)
return tf.Variable(initial)
def conv2d(x, W, stride):
return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME")
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME")
def createNetwork():
#定义深度神经网络的参数和配置
W_conv1 = weight_variable([8, 8, 4, 32])
b_conv1 = bias_variable([32])
W_conv2 = weight_variable([4, 4, 32, 64])
b_conv2 = bias_variable([64])
W_conv3 = weight_variable([3, 3, 64, 64])
b_conv3 = bias_variable([64])
W_fc1 = weight_variable([1600, 512])
b_fc1 = bias_variable([512])
W_fc2 = weight_variable([512, ACTIONS])
b_fc2 = bias_variable([ACTIONS])
#输入层
s = tf.placeholder("float", [None, 80, 80, 4])
#隐藏层
h_conv1 = tf.nn.relu(conv2d(s, W_conv1, 4) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2, 2) + b_conv2)
#h_pool2 = max_pool_2x2(h_conv2)
h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3, 1) + b_conv3)
#h_pool3 = max_pool_2x2(h_conv3)
#h_pool3_flat = tf.reshape(h_pool3, [-1, 256])
h_conv3_flat = tf.reshape(h_conv3, [-1, 1600])
h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, W_fc1) + b_fc1)
#输出层
readout = tf.matmul(h_fc1, W_fc2) + b_fc2
return s, readout, h_fc1
def trainNetwork(s, readout, h_fc1, sess):
#定义损失函数
a = tf.placeholder("float", [None, ACTIONS])
y = tf.placeholder("float", [None])
readout_action = tf.reduce_sum(tf.multiply(readout, a), reduction_indices=1)
cost = tf.reduce_mean(tf.square(y - readout_action))
train_step = tf.train.AdamOptimizer(1e-6).minimize(cost)
#开启游戏模拟器,打开一个模拟器的窗口,实时显示游戏的信息
game_state = game.GameState()
#创建一个双端队列存放replay memory
D = deque()
#写入文件
a_file = open("logs_" + GAME + "/readout.txt", 'w')
h_file = open("logs_" + GAME + "/hidden.txt", 'w')
#设置游戏的初始状态,设置动作为不执行跳跃,修改初始状态为80*80*4大小
do_nothing = np.zeros(ACTIONS)
do_nothing[0] = 1
x_t, r_0, terminal = game_state.frame_step(do_nothing)
x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)), cv2.COLOR_BGR2GRAY)
ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY)
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2)
#加载或保存网络参数
saver = tf.train.Saver()
sess.run(tf.initialize_all_variables())
checkpoint = tf.train.get_checkpoint_state("saved_networks")
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights")
#开始训练
epsilon = INITIAL_EPSILON
t = 0
while "flappy bird" != "angry bird":
#使用epsilon贪心策略选择一个动作
readout_t = readout.eval(feed_dict={
s : [s_t]})[0]
a_t = np.zeros([ACTIONS])
action_index = 0
if t % FRAME_PER_ACTION == 0:
#执行一个随即动作
if random.random() <= epsilon:
print("----------Random Action----------")
action_index = random.randrange(ACTIONS)
a_t[random.randrange(ACTIONS)] = 1
#由神经网络计算的Q(s,a)值选择对应的动作
else:
action_index = np.argmax(readout_t)
a_t[action_index] = 1
else:
a_t[0] = 1 #不执行跳跃动作
#随着游戏的进行,不断降低epsilon,减少随即动作
if epsilon > FINAL_EPSILON and t > OBSERVE:
epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE
#执行选择的动作,并获得下一状态及回报
x_t1_colored, r_t, terminal = game_state.frame_step(a_t)
x_t1 = cv2.cvtColor(cv2.resize(x_t1_colored, (80, 80)), cv2.COLOR_BGR2GRAY)
ret, x_t1 = cv2.threshold(x_t1, 1, 255, cv2.THRESH_BINARY)
x_t1 = np.reshape(x_t1, (80, 80, 1))
#s_t1 = np.append(x_t1, s_t[:,:,1:], axis = 2)
s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2)
#将状态转移过程存储到D中,用于更新参数时采样
D.append((s_t, a_t, r_t, s_t1, terminal))
if len(D) > REPLAY_MEMORY:
D.popleft()
#过了观察期,才会进行网络参数的更新
if t > OBSERVE:
#从D中随机采样,用于参数更新
minibatch = random.sample(D, BATCH)
#分别将当前状态、采取的动作、获得的回报、下一状态分组存放
s_j_batch = [d[0] for d in minibatch]
a_batch = [d[1] for d in minibatch]
r_batch = [d[2] for d in minibatch]
s_j1_batch = [d[3] for d in minibatch]
#计算Q(s,a)的新值
y_batch = []
readout_j1_batch = readout.eval(feed_dict = {
s : s_j1_batch})
for i in range(0, len(minibatch)):
terminal = minibatch[i][4]
#如果游戏结束,则只有反馈值
if terminal:
y_batch.append(r_batch[i])
else:
y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i]))
#使用梯度下降更新网络参数
train_step.run(feed_dict = {
y : y_batch,
a : a_batch,
s : s_j_batch}
)
#状态发生改变,用于下次循环
s_t = s_t1
t += 1
#每进行10000次迭代,保留一下网络参数
if t % 10000 == 0:
saver.save(sess, 'saved_networks/' + GAME + '-dqn', global_step = t)
#打印游戏信息
state = ""
if t <= OBSERVE:
state = "observe"
elif t > OBSERVE and t <= OBSERVE + EXPLORE:
state = "explore"
else:
state = "train"
print("TIMESTEP", t, "/ STATE", state, \
"/ EPSILON", epsilon, "/ ACTION", action_index, "/ REWARD", r_t, \
"/ Q_MAX %e" % np.max(readout_t))
#写入文件
'''
if t % 10000 <= 100:
a_file.write(",".join([str(x) for x in readout_t]) + '\n')
h_file.write(",".join([str(x) for x in h_fc1.eval(feed_dict={s:[s_t]})[0]]) + '\n')
cv2.imwrite("logs_tetris/frame" + str(t) + ".png", x_t1)
'''
def playGame():
sess = tf.InteractiveSession()
s, readout, h_fc1 = createNetwork()
trainNetwork(s, readout, h_fc1, sess)
def main():
playGame()
main()
训练结果
因为CSDN好像不能直接上传视频,只能把视频转换为gif了,凑乎看吧~
5万次
PS:这只笨鸟只会一直往上飞

10万次
PS:10万次后,似乎略有进步,不会一直总是往上飞
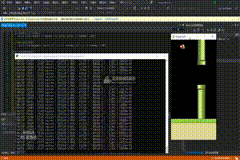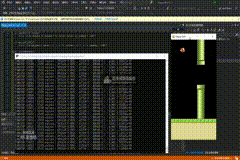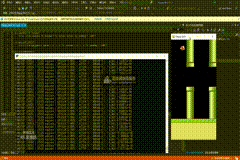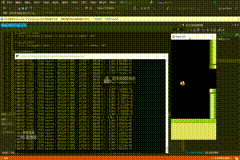
20万次
PS:有了大致的方向,尝试越过第一个柱子
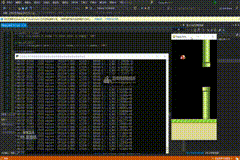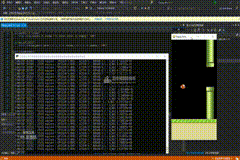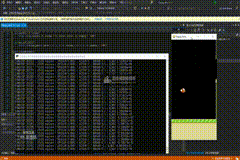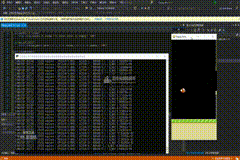
30万次
PS:基本可以正确地找到第一个柱子间隙的方位并尝试越过

40万次
PS:已经有很高的几率过第一个柱子,并且有一定几率过第二个柱子

50万次
PS:过多个柱子的几率更高了
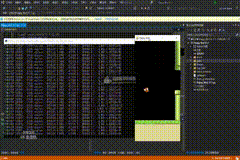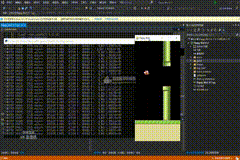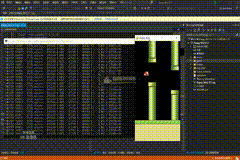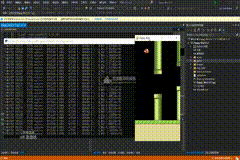
100万次
PS:已经达到了普通玩家的正常水平,能顺利通过5~8个柱子
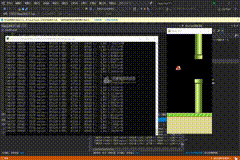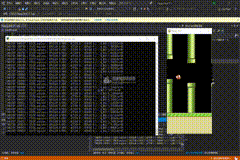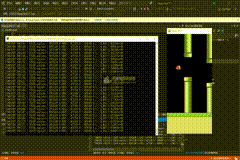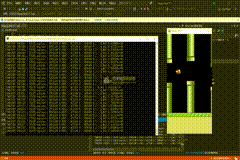
200万次
PS:几乎无敌了,失败是极低概率才会发生
(更高次数的训练请等待作者更新…)
注:本文是博主机器学习实例的总结,不支持任何商用,转载请注明出处!如果你也对机器学习有一定的兴趣和理解,欢迎随时找博主交流~