Python爬虫系列——(二)爬取有道翻译
Python爬虫系列——(二)爬取有道翻译
2.1功能说明

打开有道翻译页面,输入要翻译的内容,页面并没有通过刷新来获取数据,所有是使用的前端的Ajax技术进行的交互,也就是说这里使用的是Ajax技术与有道的后台服务器进行的请求,从而得到返回结果。下面我们打开“Chrome"浏览器的”检查“中的"Network"选项卡中,捕获Ajax请求(在XHR中):
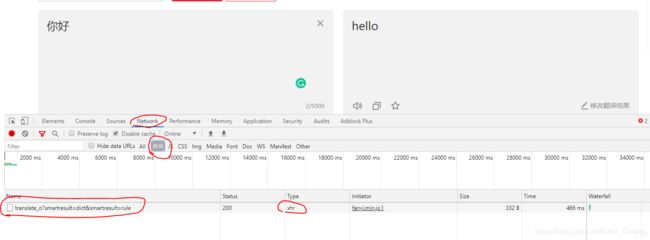
可以看到,当我更改输入内容的时候,会自动发出ajax请求,这里是捕获到的请求。
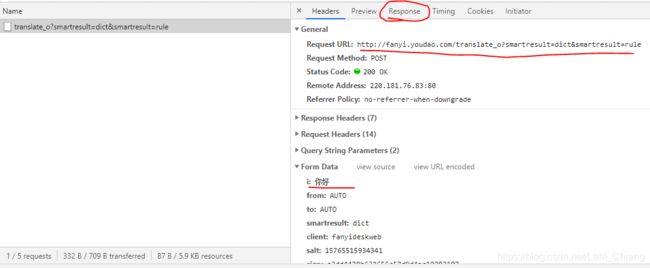
点击请求后,在右侧可以看到请求头的以下信息,其中有Request URL,Form Data等。其中FormData中的i字段就是我们要翻译的内容。这是打开Response选项卡,可以看到后台返回过来的内容。是一个JSON格式的数据。
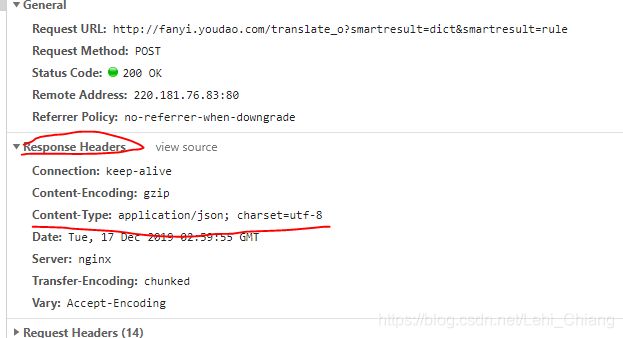

下面我们通过这个请求URL来爬取有道翻译,然后通过JSON解析获取最后的翻译数据。
2.2代码实现
这里使用Python的第三方工具Requests包发起请求。
关于Requests包的使用教程见我上一篇文章:
https://blog.csdn.net/Lehi_Chiang/article/details/103575271
2.2.1 简易版
import requests
#构造请求头,模拟浏览器发出的请求
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36",
"Connection":"keep-alive",
"Accept":"application/json, text/javascript, */*; q=0.01"}
#这里要注意!!!!!将translate后面的_o删掉,否则回去不到数据!!!
url="http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
data={
"i":"我爱你中国",
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"doctype":"json",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTlME"}
response = requests.post(url,data=data,headers=headers)
if response.status_code==200:
fanyidata = response.json()
if fanyidata['errorCode']==0:
print(fanyidata['translateResult'][0][0]['tgt'])
else:
print("请求URL有问题!")
else:
print("请求失败!")
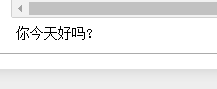
翻译”我爱你中国“

翻译”How are you today?"
2.2.2 完整版
使用while循环得到用户的输入,进行翻译
import requests
#构造请求头,模拟浏览器发出的请求
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36",
"Connection":"keep-alive",
"Accept":"application/json, text/javascript, */*; q=0.01"}
#这里要注意!!!!!将translate后面的_o删掉,否则回去不到数据!!!
url="http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
def parseURL(key):
#post方法的请求参数
data={
"i":key,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"doctype":"json",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTlME"}
response = requests.post(url,data=data,headers=headers)
if response.status_code==200:
fanyidata = response.json()
if fanyidata['errorCode']==0:
print('\n'+fanyidata['translateResult'][0][0]['tgt'])
else:
print("请求URL有问题!")
else:
print("请求失败!")
if __name__=="__main__":
print("有道翻译模拟,输入‘q'退出!")
while True:
keyword = input("请输入要翻译的内容:")
if keyword =='q':
break
else:
parseURL(keyword)
输出结果如下:
有道翻译模拟,输入‘q'退出!
请输入要翻译的内容:I love you!
我爱你!
请输入要翻译的内容:You are my sunshine in my life!
你是我的阳光在我的生命中!
请输入要翻译的内容:今天是星期几?
What day is it today?
请输入要翻译的内容:q
2.3总结
- 在请求URL的字符串中,要删除translate后面的_o,否则得不到翻译后的数据
- 模仿Post的请求参数,可以翻译其他的语言。
- Post的请求参数,data字典中,可以不要写出那么多的参数,写出几个关键的即可。
- 也可以不加请求头headers,也能进行正常的请求。
- 以后有机会可以做出一个Python的GUI的程序,方便使用!