人工智能-深度学习-神经网络:CNN(Convolutional Neural Networks,卷积神经网络)
一、概述
-
卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,全连接神经网络(DNN)里的一些计算技巧到这里依旧适用。
-
CNN(convolutional neural network),主要就是通过一个个的filter,不断地提取特征,从局部的特征到总体的特征,从而进行图像识别等等功能。
-
一个卷积神经网络由很多层组成,它们的输入是三维的,输出也是三维的,有的层有参数,有的层不需要参数。
-
卷积神经网络与其他神经网络的区别:卷积神经网络默认输入是图像,可以让我们把特定的性质编码入网络结构,使是我们的前馈函数更加有效率,并减少了大量参数。
-
卷积神经网络(CNN)结构由以下层组成:
- 输入层
- 卷积层(Convolutional layer):卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
- 激活函数:
- Sigmoid:解析值介于0和1之间
- TanH: 将值解析为介于-1和1之间
- ReLU(Rectified Linear Units):如果值为负,则变为0,否则保持不变
- 池化层(Pooling layer):通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
- 全连接层(Fully-Connected layer):把所有局部特征结合变成全局特征,用来计算最后每一类的得分。

- 卷积神经网络各层应用实例:
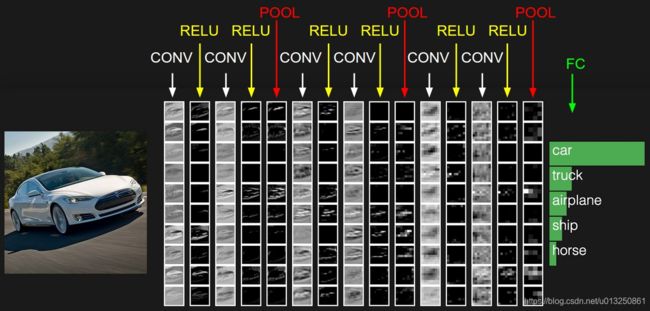
- 卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
- CNN一个非常重要的特点就是头重脚轻(越往输入权值越小,越往输出权值越多),呈现出一个倒三角的形态,这就很好地避免了BP神经网络中反向传播的时候梯度损失得太快。
- 卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
二、CNN的组成
1、输入层
具有三维体积的神经元(3D volumes of neurons):卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width, height, depth(注意这个depth不是神经网络的深度,而是用来描述神经元的) 。比如输入的图片大小是 7 × 7 × 3 (rgb),那么输入神经元就也具有 7×7×3 的维度。
2、卷积层(Convolution)
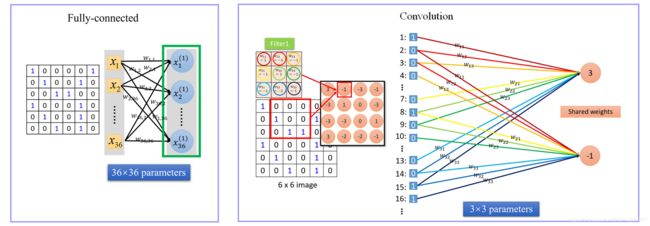
- 全连接神经网络把输入层和隐含层进行“全连接(Full Connected)“的设计。从计算的角度来讲,相对较小的图像从整幅图像中计算特征是可行的。但是,如果是更大的图像,要通过这种全联通网络的这种方法来学习整幅图像上的特征,从计算角度而言,将变得非常耗时。
- 卷积层的卷积操作解决全连接神经网络计算量庞大的问题:对卷积核和输入单元间的连接加以限制:每个卷积核仅仅只能连接输入单元的一部分。
- 卷积层的神经元也可以是三维的,所以也具有深度。一个神经元可以包含一系列过滤器(filter),每个过滤器(filter)训练一个深度,某个神经元包含几个过滤器(filter),该神经元的输出单元就具有多少深度。
2.1 感受野(Receptive Field)
- 在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(Feature Map)上的像素点在输入图片上映射的区域大小。通俗点的解释是,特征图上的一个点对应输入图上的区域。
- The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by).
- 卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,kernel size 均为3×3,stride均为1,绿色标记的是Layer2 每个神经元看到的区域,黄色标记的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1 上 3×3 大小的区域,Layer3 每个神经元看到Layer2 上 3×3 大小的区域,该区域可以又看到Layer1 上 5×5 大小的区域。
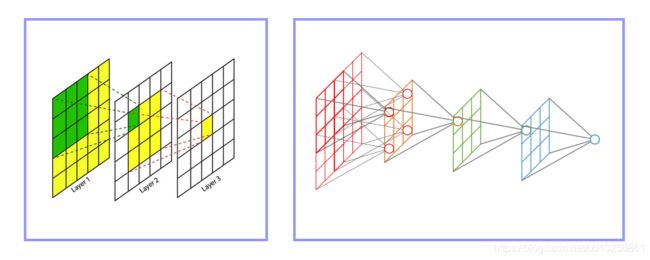
- 所以,感受野是个相对概念,某层卷积层的特征图(Feature Map)上的元素看到前面各个不同卷积层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
- 感受野大小的计算是个递推公式。参考:彻底搞懂感受野的含义与计算
2.2 过滤器(Filter)/卷积核(Kernel)
- 过滤器(Filter)可以由一层卷积核(Kernel)组成,也可以由多层卷积核(Kernel)组成。
- 每层卷积层有n个过滤器(Filter),那么该层卷积层就会输出几个特征图(Feature Map)。即: 一个过滤器就对应一层特征图
- 每个过滤器(Filter)的深度的设定要与输入数据的深度一致。
- 几个小的卷积核(例如3×3)生成的几个特征图(Feature Map)叠加(stack)在一起,相比较一个大的卷积核(例如7×7)生成的1个特征图(Feature Map)来说,与原图的连通性不变,但是却大大降低了参数的个数,从而降低了计算的复杂度!这就是深度学习,喜欢小而深,厌恶大而浅。这里指的是每层卷积层中卷积核的大小和个数。
2.3 过滤器(Filter)对单通道(channels)图片的卷积操作
- 每一个过滤器(Filter)中的每个元素就是该神经网络的待求参数。

2.4 过滤器(Filter)对多通道(channels)图片的卷积操作
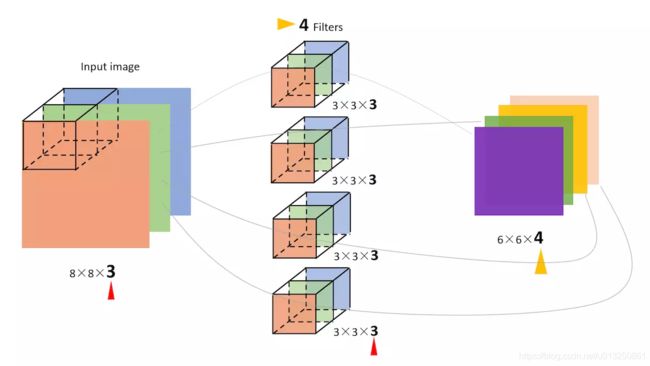
- 彩色图像,一般都是RGB三个通道(channels)的,因此输入数据的维度一般有三个:(长,宽,通道)。
比如一个像素为 7 × 7 7×7 7×7 的RGB图片,维度就是 ( 7 , 7 , 3 ) (7,7,3) (7,7,3)。 - 我们的过滤器(Filter)的维度可以设为 ( 3 , 3 , 3 ) (3,3,3) (3,3,3)、 ( 4 , 4 , 3 ) (4,4,3) (4,4,3) 或者 ( 5 , 5 , 3 ) (5,5,3) (5,5,3),它的最后一维要跟输入的channel维度一致。
- 也就是说每个过滤器(Filter)由3层卷积核(Kernel)组成。
- 上图中的输入图像是 ( 7 , 7 , 3 ) (7,7,3) (7,7,3),filter有2个(Filter W0、Filter W1),这两个Filter的大小均为 ( 3 , 3 , 3 ) (3,3,3) (3,3,3),步幅为2,则得到的输出为(3,3,2)。
2.5 神经元
- 当我们的输入是一个(7×7)的图像,
- 那么我们如果想获得两个特征,我们使用(3×3)的两个过滤器(Filter)即可,这样经过一次卷积以后,得到两个(5×5)的特征图,
- 那么该层卷积层的神经元的个数就是50个(5×5×2)。原因在于像素的个数就是神经元的个数。
2.6 空间排列(Spatial arrangement)
一层卷积层的输出单元(由多个Feature Map组成)的大小有以下三个量控制:深度(depth)、步幅(stride)、补零(zero-padding)。
- 深度(depth) : 顾名思义,它控制输出单元的深度,也就是Kernel/Filter的个数,连接同一块区域的神经元个数。又名:depth column
- 步幅(stride):它控制在同一深度的相邻两个隐含单元与他们相连接的输入区域的距离。如果步幅很小(比如 stride = 1)的话,相邻隐含单元的输入区域的重叠部分会很多; 步幅很大则重叠区域变少。
- 补零(zero-padding) : 我们可以通过在输入单元周围补零来改变输入单元整体大小,从而控制输出单元的空间大小。
2.7 每层卷积层参数数量
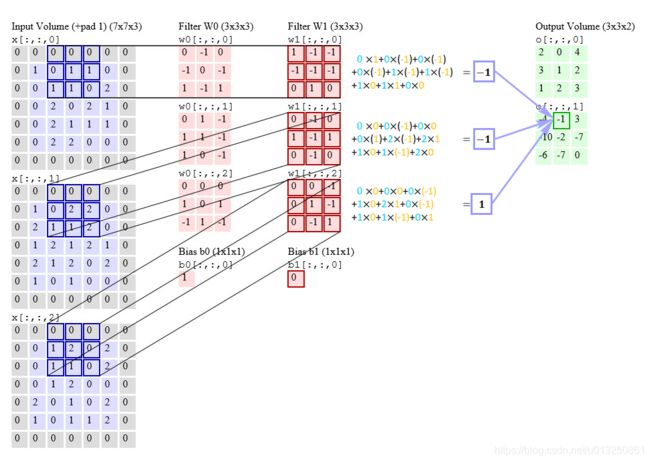
- 如上图中的过滤器 Filter W 0 W_0 W0、Filter W 1 W_1 W1
- k × k k×k k×k: kernel size: k × k = 3 × 3 k×k=3×3 k×k=3×3
- I I I: number of input channels: I = 3 I=3 I=3
- O O O: number of output channels: O = 2 O=2 O=2
- 该层卷积层的参数的总数量 = ( k × k × I ) × O = 3 × 3 × 3 × 2 = 54 (k×k×I)×O=3×3×3×2=54 (k×k×I)×O=3×3×3×2=54
2.8 每层卷积层的输入、输出、参数
- 输入:三维数据,(宽 w i n w_{in} win×高 h i n h_{in} hin×深 d i n d_{in} din)
- 每层卷积层的参数:
- 感受野(receptive field)的大小 f f f
- 过滤器(Filter)的数量(决定输出单元的深度) k k k
- 步幅(Stride) s s s
- 补零(zero-padding)的数量 p p p
- 输出:三维单元,(宽 w o u t w_{out} wout×高 h o u t h_{out} hout×深 d o u t d_{out} dout),其中:
- w o u t = w i n − f + 2 p s + 1 w_{out}=\cfrac{w_{in}-f+2p}{s}+1 wout=swin−f+2p+1
- h o u t = h i n − f + 2 p s + 1 h_{out}=\cfrac{h_{in}-f+2p}{s}+1 hout=shin−f+2p+1
- d o u t = k d_{out}=k dout=k
2.9 卷积层与全连接神经网络的区别
3、激活函数
- 激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。神经网络之所以能解决非线性问题,本质上就是激活函数加入了非线性因素,弥补了线性模型的表达力,把“激活的神经元的特征”通过函数保留并映射到下一层。
- 激活函数不会更改输入数据的维度,也就是输入和输出的维度是相同的。
- 典型激活函数:Sigmoid函数、TanH函数、ReLU函数
4、下采样层(Subsampling)/池化层(Pooling Layer)
池化(pool)即下采样(downsamples),目的是为了减小特征图(Feature Map)。池化操作对每个深度切片独立,规模一般为 2 × 2 2×2 2×2,相对于卷积层进行卷积运算,池化层进行的运算一般有以下几种:
- 最大池化(Max Pooling)。取4个点的最大值。这是最常用的池化方法。
- 均值池化(Mean Pooling)。取4个点的均值。
- 高斯池化。借鉴高斯模糊的方法。不常用。
- 可训练池化。训练函数 f f f ,接受4个点为输入,出入1个点。不常用。
4.1 2×2 池化层
- 最常见的池化层是规模为 2 × 2 2×2 2×2, 步幅为 2 2 2,对输入的每个深度切片进行下采样。每个MAX操作对四个数进行,如下图所示:
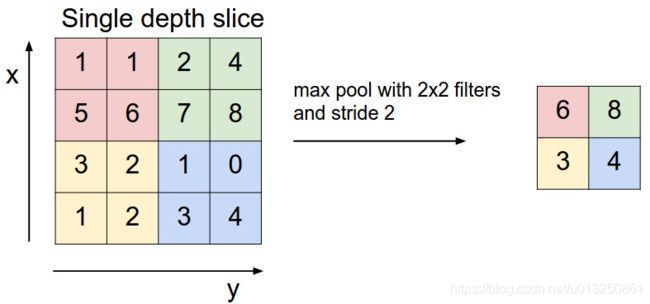
- 池化操作将保存深度大小不变。
- 如果池化层的输入单元大小不是二的整数倍,一般采取边缘补零(zero-padding)的方式补成2的倍数,然后再池化。
4.2 每层池化层的输入、输出、参数
- 输入:三维数据,(宽 w i n w_{in} win×高 h i n h_{in} hin×深 d i n d_{in} din)
- 每层池化层的参数(hyperparameters):
- 感受野(receptive field)的大小 f f f
- 步幅(Stride) s s s
- 输出:三维单元,(宽 w o u t w_{out} wout×高 h o u t h_{out} hout×深 d o u t d_{out} dout),其中:
- w o u t = w i n − f s w_{out}=\cfrac{w_{in}-f}{s} wout=swin−f
- h o u t = h i n − f s + 1 h_{out}=\cfrac{h_{in}-f}{s}+1 hout=shin−f+1
- d o u t = d i n d_{out}=d_{in} dout=din
5、上采样层(Upsampling)

6、全连接层(Fully-connected layer)
全连接层和卷积层可以相互转换:
- 对于任意一个卷积层,要把它变成全连接层只需要把权重变成一个巨大的矩阵,其中大部分都是0 除了一些特定区块(因为局部感知),而且好多区块的权值还相同(由于权重共享)。
- 相反地,对于任何一个全连接层也可以变为卷积层。比如一个 k = 4096 k=4096 k=4096 的全连接层,输入层大小为 7 × 7 × 512 7×7×512 7×7×512,它可以等效为一个 f = 7 , p = 0 , s = 1 , k = 4096 f=7,p=0,s=1,k=4096 f=7,p=0,s=1,k=4096 的卷积层。换言之,我们把 filter size 正好设置为整个输入层大小。
7、ReLU层

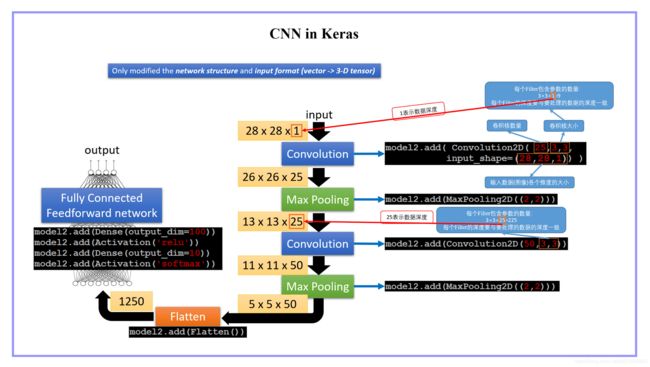
三、CNN in Keras
四、CNN的训练过程
- 同一般机器学习算法一样,先定义Loss function,衡量和实际结果之间差距。找到最小化损失函数的W和b,
- CNN中用的算法是SGD(随机梯度下降)。
- 卷积神经网络的训练过程分为两个阶段。第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段。另外一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向底层次进行传播训练的阶段,即反向传播阶段。

- 网络进行权值的初始化;
- 输入数据经过卷积层、下采样层、全连接层的向前传播得到输出值;
- 求出网络的输出值与目标值之间的误差;
- 当误差大于我们的期望值时,将误差传回网络中,依次求得全连接层,下采样层,卷积层的误差。各层的误差可以理解为对于网络的总误差,网络应承担多少;当误差等于或小于我们的期望值时,结束训练。
- 根据求得误差进行权值更新。然后在进入到第二步。
1、前向传播过程
在前向传播过程中,输入的图形数据经过多层卷积层的卷积和池化处理,提出特征向量,将特征向量传入全连接层中,得出分类识别的结果。当输出的结果与我们的期望值相符时,输出结果。
1.1 卷积层的向前传播过程
卷积层的向前传播过程是,通过卷积核对输入数据进行卷积操作得到卷积操作。数据在实际的网络中的计算过程,我们以图3-4为例,介绍卷积层的向前传播过程。其中一个输入为15个神经元的图片,卷积核为2×2×1的网络,即卷积核的权值为W1,W2,W3,W4。那么卷积核对于输入数据的卷积过程,如下图4-2所示。卷积核采用步长为1的卷积方式,卷积整个输入图片,形成了局部感受野,然后与其进行卷积算法,即权值矩阵与图片的特征值进行加权和(再加上一个偏置量),然后通过激活函数得到输出。

图片深度为2时,卷积层的向前传播过程如图4-3所示。输入的图片的深度为4×4×2,卷积核为2×2×2,向前传播过程为,求得第一层的数据与卷积核的第一层的权值的加权和,然后再求得第二层的数据与卷积核的第二层的权值的加权和,两层的加权和相加得到网络的输出。
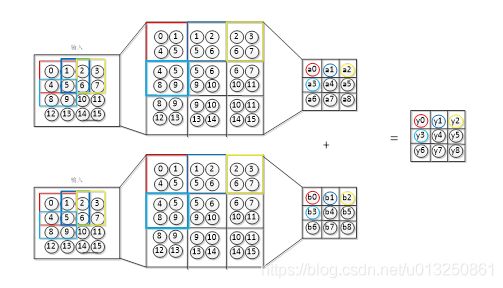
1.2 下采样层的向前传播过程
上一层(卷积层)提取的特征作为输入传到下采样层,通过下采样层的池化操作,降低数据的维度,可以避免过拟合。如图4-4中为常见的池化方式示意。最大池化方法也就是选取特征图中的最大值。均值池化则是求出特征图的平均值。随机池化方法则是先求出所有的特征值出现在该特征图中的概率,然后在来随机选取其中的一个概率作为该特征图的特征值,其中概率越大的选择的几率越大。

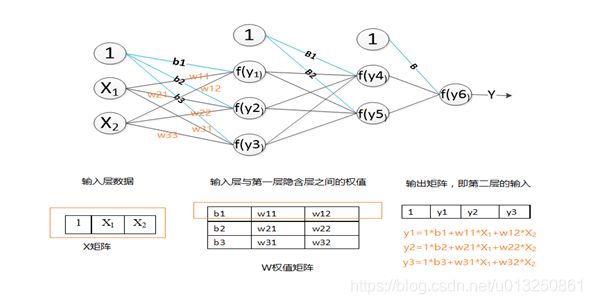
1.3 全连接层的向前传播过程
特征图进过卷积层和下采样层的特征提取之后,将提取出来的特征传到全连接层中,通过全连接层,进行分类,获得分类模型,得到最后的结果。下图为一个三层的全连接层。假设卷积神经网络中,传入全连接层的特征为x1,x2。则其在全连接层中的向前传播过程如图所示。第一层全连接层有3个神经元y1,y2,y3。这三个节点的权值矩阵为W,其中b1,b2,b3分别为节点y1,y2,y3的偏置量。可以看出,在全连接层中,参数的个数=全连接层中节点的个数×输入的特征的个数+节点的个数(偏置量)。其向前传递过程具体如图所示,得到输出矩阵后,经过激励函数f(y)的激活,传入下一层。
2、反向传播过程
当卷积神经网络输出的结果与我们的期望值不相符时,则进行反向传播过程。求出结果与期望值的误差,再将误差一层一层的返回,计算出每一层的误差,然后进行权值更新。该过程的主要目的是通过训练样本和期望值来调整网络权值。误差的传递过程可以这样来理解,首先,数据从输入层到输出层,期间经过了卷积层,下采样层,全连接层,而数据在各层之间传递的过程中难免会造成数据的损失,则也就导致了误差的产生。而每一层造成的误差值是不一样的,所以当我们求出网络的总误差之后,需要将误差传入网络中,求得该各层对于总的误差应该承担多少比重。
反向传播的训练过程的第一步为计算出网络总的误差:求出输出层n的输出a(n)与目标值y之间为误差。计算公式为:
![]()
其中,为激励函数的导函数的值。
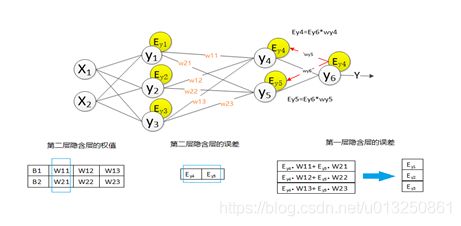
2.1 全连接层之间的误差传递
求出网络的总差之后,进行反向传播过程,将误差传入输出层的上一层全连接层,求出在该层中,产生了多少误差。而网络的误差又是由组成该网络的神经元所造成的,所以我们要求出每个神经元在网络中的误差。求上一层的误差,需要找出上一层中哪些节点与该输出层连接,然后用误差乘以节点的权值,求得每个节点的误差,具体如图所示:
2.2 当前层为下采样层,求上一层的误差
在下采样层中,根据采用的池化方法,把误差传入到上一层。下采样层如果采用的是最大池化(max-pooling)的方法,则直接把误差传到上一层连接的节点中。果采用的是均值池化(mean pooling)的方法,误差则是均匀的分布到上一层的网络中。另外在下采样层中,是不需要进行权值更新的,只需要正确的传递所有的误差到上一层。
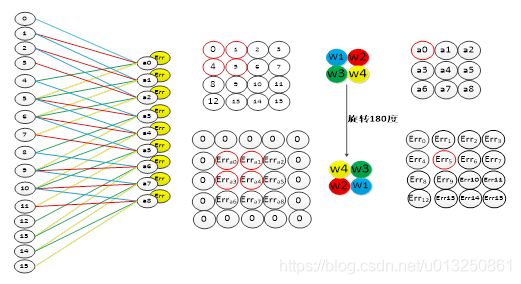
2.3 当前层为卷积层,求上一层的误差
卷积层中采用的是局部连接的方式,和全连接层的误差传递方式不同,在卷积层中,误差的传递也是依靠卷积核进行传递的。在误差传递的过程,我们需要通过卷积核找到卷积层和上一层的连接节点。求卷积层的上一层的误差的过程为:先对卷积层误差进行一层全零填充,然后将卷积层进行一百八十度旋转,再用旋转后的卷积核卷积填充过程的误差矩阵,并得到了上一层的误差。如图4-7为卷积层的误差传递过程。图右上方为卷积层的向前卷积过程,而右下方为卷积层的误差传递过程。从图中可以看出,误差的卷积过程正好是沿着向前传播的过程,将误差传到了上一层。

3、卷积神经网络的权值更新
3.1 卷积层的权值更新
卷积层的误差更新过程为:将误差矩阵当做卷积核,卷积输入的特征图,并得到了权值的偏差矩阵,然后与原先的卷积核的权值相加,并得到了更新后的卷积核。如图4-8,图中可以看出,该卷积方式的权值连接正好和向前传播中权值的连接是一致的。
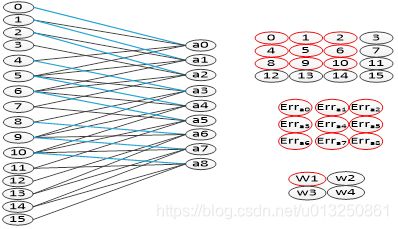
3.2 全连接层的权值更新过程
全连接层中的权值更新过程为:
- 求出权值的偏导数值:学习速率乘以激励函数的倒数乘以输入值;
- 原先的权值加上偏导值,得到新的权值矩阵。具体的过程如图4-9所示(图中的激活函数为Sigmoid函数)。

五、卷积神经网络之优缺点
1、CNN的优点
- 共享卷积核,对高维数据处理无压力
- 无需手动选取特征,训练好权重,即得特征分类效果好
2、CNN的缺点
- 需要调参,需要大样本量,训练最好要GPU
- 物理含义不明确(也就说,我们并不知道每个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
六、典型CNN
- LeNet,这是最早用于数字识别的CNN
- AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比
- LeNet更深,用多层小卷积层叠加替换单大卷积层。
- ZF Net, 2013 ILSVRC比赛冠军
- GoogLeNet, 2014 ILSVRC比赛冠军
- VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
七、Fine-Tuning
- fine-tuning就是使用已用于其他目标、预训练好模型的权重或者部分权重,作为初始值开始训练。
- 那为什么我们不用随机选取选几个数作为权重初始值?原因很简单,第一,自己从头训练卷积神经网络容易出现问题;第二,fine-tuning能很快收敛到一个较理想的状态,省时又省心。
- fine-tuning的具体做法是?
- 复用相同层的权重,新定义层取随机权重初始值
- 调大新定义层的的学习率,调小复用层学习率
八、卷积神经网络的常用框架
Caffe
- 源于Berkeley的主流CV工具包,支持C++,python,matlab
- Model Zoo中有大量预训练好的模型供使用
Torch
- Facebook用的卷积神经网络工具包
- 通过时域卷积的本地接口,使用非常直观
- 定义新网络层简单
TensorFlow
- Google的深度学习框架
- TensorBoard可视化很方便
- 数据和模型并行化好,速度快
九、CNN的参数优化方法
一般来说,提高泛化能力的方法主要有以下几个:
- 正则化
- 增加神经网络层数
- 使用正确的代价函数
- 使用好的权重初始化技术
- 人为拓展训练集
- 弃权技术
1、使用L2正则化,dropout技术,扩展数据集等,有效缓解过拟合,提升了性能;
2、使用ReLU,导数为常量,可以缓解梯度下降问题,并加速训练;
3、增加Conv/Pooling与Fc层,可以改善性能。(我自己实测也是如此)
Note:
1、网络并非越深越好,单纯的Conv/Pooling/Fc结构,增加到一定深度后由于过拟合性能反而下降。
2、网络结构信息更重要,如使用GoogleNet、ResNet等。
十、CNN经典结构:VGG案例-cifar100数据集
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 放在 import tensorflow as tf 之前才有效
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
# 一、获取数据集
(X_train, Y_train), (X_val, Y_val) = datasets.cifar100.load_data()
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
Y_train = tf.squeeze(Y_train)
Y_val = tf.squeeze(Y_val)
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
# 二、数据处理
# 预处理函数:将numpy数据转为tensor
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x, y
# 2.1 处理训练集
# print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
db_train = tf.data.Dataset.from_tensor_slices((X_train, Y_train)) # 此步骤自动将numpy类型的数据转为tensor
db_train = db_train.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
# 从data数据集中按顺序抽取buffer_size个样本放在buffer中,然后打乱buffer中的样本。buffer中样本个数不足buffer_size,继续从data数据集中安顺序填充至buffer_size,此时会再次打乱。
db_train = db_train.shuffle(buffer_size=1000) # 打散db_train中的样本顺序,防止图片的原始顺序对神经网络性能的干扰。
print('db_train = {0},type(db_train) = {1}'.format(db_train, type(db_train)))
batch_size_train = 2000 # 每个batch里的样本数量设置100-200之间合适。
db_batch_train = db_train.batch(batch_size_train) # 将db_batch_train中每sample_num_of_each_batch_train张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_train张图片
print('db_batch_train = {0},type(db_batch_train) = {1}'.format(db_batch_train, type(db_batch_train)))
# 2.2 处理测试集:测试数据集不需要打乱顺序
db_val = tf.data.Dataset.from_tensor_slices((X_val, Y_val)) # 此步骤自动将numpy类型的数据转为tensor
db_val = db_val.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
batch_size_val = 2000 # 每个batch里的样本数量设置100-200之间合适。
db_batch_val = db_val.batch(batch_size_val) # 将db_val中每sample_num_of_each_batch_val张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_val张图片
# 三、构建神经网络
# 1、卷积神经网络结构:Conv2D 表示卷积层,激活函数用 relu
conv_layers = [ # 5 units of conv + max pooling
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu), # 64个kernel表示输出的数据的channel为64,padding="same"表示自动padding使得输入与输出大小一致
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
# 2、全连接神经网络结构:Dense 表示全连接层,激活函数用 relu
fullcon_layers = [
layers.Dense(300, activation=tf.nn.relu), # 降维:512-->300
layers.Dense(200, activation=tf.nn.relu), # 降维:300-->200
layers.Dense(100) # 降维:200-->100,最后一层一般不需要在此处指定激活函数,在计算Loss的时候会自动运用激活函数
]
# 3、构建卷积神经网络、全连接神经网络
conv_network = Sequential(conv_layers) # [b, 32, 32, 3] => [b, 1, 1, 512]
fullcon_network = Sequential(fullcon_layers) # [b, 1, 1, 512] => [b, 1, 1, 100]
conv_network.build(input_shape=[None, 32, 32, 3]) # 原始图片维度为:[32, 32, 3],None表示样本数量,是不确定的值。
fullcon_network.build(input_shape=[None, 512]) # 从卷积网络传过来的数据维度为:[b, 512],None表示样本数量,是不确定的值。
# 4、打印神经网络信息
conv_network.summary() # 打印卷积神经网络network的简要信息
fullcon_network.summary() # 打印神经网络network的简要信息
# 四、梯度下降优化器设置
optimizer = optimizers.Adam(lr=1e-4)
# 五、整体数据集进行一次梯度下降来更新模型参数,整体数据集迭代一次,一般用epoch。每个epoch中含有batch_step_no个step,每个step中就是设置的每个batch所含有的样本数量。
def train_epoch(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_train): # 每次计算一个batch的数据,循环结束则计算完毕整体数据的一次梯度下降;每个batch的序号一般用step表示(batch_step_no)
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}------------type(X_batch) = {4},type(Y_batch) = {5}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape, type(X_batch), type(Y_batch)))
Y_batch_one_hot = tf.one_hot(Y_batch, depth=100) # One-Hot编码,共有100类 [] => [b,100]
print('\tY_train_one_hot.shpae = {0}'.format(Y_batch_one_hot.shape))
# 梯度带tf.GradientTape:连接需要计算梯度的”函数“和”变量“的上下文管理器(context manager)。将“函数”(即Loss的定义式)与“变量”(即神经网络的所有参数)都包裹在tf.GradientTape中进行追踪管理
with tf.GradientTape() as tape:
# Step1. 前向传播/前向运算-->计算当前参数下模型的预测值
out_logits_conv = conv_network(X_batch) # [b, 32, 32, 3] => [b, 1, 1, 512]
print('\tout_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_conv = tf.reshape(out_logits_conv, [-1, 512]) # [b, 1, 1, 512] => [b, 512]
print('\tReshape之后:out_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_fullcon = fullcon_network(out_logits_conv) # [b, 512] => [b, 100]
print('\tout_logits_fullcon.shape = {0}'.format(out_logits_fullcon.shape))
# Step2. 计算预测值与真实值之间的损失Loss:交叉熵损失
MSE_Loss = tf.losses.categorical_crossentropy(Y_batch_one_hot, out_logits_fullcon, from_logits=True) # categorical_crossentropy()第一个参数是真实值,第二个参数是预测值,顺序不能颠倒
print('\tMSE_Loss.shape = {0}'.format(MSE_Loss.shape))
MSE_Loss = tf.reduce_mean(MSE_Loss)
print('\t求均值后:MSE_Loss.shape = {0}'.format(MSE_Loss.shape))
print('\t第{0}个epoch-->第{1}个batch step的初始时的:MSE_Loss = {2}'.format(epoch_no, batch_step_no + 1, MSE_Loss))
# Step3. 反向传播-->损失值Loss下降一个学习率的梯度之后所对应的更新后的各个Layer的参数:W1, W2, W3, B1, B2, B3...
variables = conv_network.trainable_variables + fullcon_network.trainable_variables # list的拼接: [1, 2] + [3, 4] => [1, 2, 3, 4]
# grads为整个全连接神经网络模型中所有Layer的待优化参数trainable_variables [W1, W2, W3, B1, B2, B3...]分别对目标函数MSE_Loss 在 X_batch 处的梯度值,
grads = tape.gradient(MSE_Loss, variables) # grads为梯度值。MSE_Loss为目标函数,variables为卷积神经网络、全连接神经网络所有待优化参数,
# grads, _ = tf.clip_by_global_norm(grads, 15) # 限幅:解决gradient explosion或者gradients vanishing的问题。
# print('\t第{0}个epoch-->第{1}个batch step的初始时的参数:'.format(epoch_no, batch_step_no + 1))
if batch_step_no == 0:
index_variable = 1
for grad in grads:
print('\t\tgrad{0}:grad.shape = {1},grad.ndim = {2}'.format(index_variable, grad.shape, grad.ndim))
index_variable = index_variable + 1
# 进行一次梯度下降
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始')
optimizer.apply_gradients(zip(grads, variables)) # network的所有参数 trainable_variables [W1, W2, W3, B1, B2, B3...]下降一个梯度 w' = w - lr * grad,zip的作用是让梯度值与所属参数前后一一对应
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束\n')
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 六、模型评估 test/evluation
def evluation(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
total_correct, total_num = 0, 0
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_val):
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape))
# 根据训练模型计算测试数据的输出值out
out_logits_conv = conv_network(X_batch) # [b, 32, 32, 3] => [b, 1, 1, 512]
print('\tout_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_conv = tf.reshape(out_logits_conv, [-1, 512]) # [b, 1, 1, 512] => [b, 512]
print('\tReshape之后:out_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_fullcon = fullcon_network(out_logits_conv) # [b, 512] => [b, 100]
print('\tout_logits_fullcon.shape = {0}'.format(out_logits_fullcon.shape))
# print('\tout_logits_fullcon[:1,:] = {0}'.format(out_logits_fullcon[:1, :]))
# 利用softmax()函数将network的输出值转为0~1范围的值,并且使得所有类别预测概率总和为1
out_logits_prob = tf.nn.softmax(out_logits_fullcon, axis=1) # out_logits_prob: [b, 100] ~ [0, 1]
# print('\tout_logits_prob[:1,:] = {0}'.format(out_logits_prob[:1, :]))
out_logits_prob_max_index = tf.cast(tf.argmax(out_logits_prob, axis=1), dtype=tf.int32) # [b, 100] => [b] 查找最大值所在的索引位置 int64 转为 int32
# print('\t预测值:out_logits_prob_max_index = {0},\t真实值:Y_train_one_hot = {1}'.format(out_logits_prob_max_index, Y_batch))
is_correct_boolean = tf.equal(out_logits_prob_max_index, Y_batch.numpy())
# print('\tis_correct_boolean = {0}'.format(is_correct_boolean))
is_correct_int = tf.cast(is_correct_boolean, dtype=tf.float32)
# print('\tis_correct_int = {0}'.format(is_correct_int))
is_correct_count = tf.reduce_sum(is_correct_int)
print('\tis_correct_count = {0}\n'.format(is_correct_count))
total_correct += int(is_correct_count)
total_num += X_batch.shape[0]
print('total_correct = {0}---total_num = {1}'.format(total_correct, total_num))
acc = total_correct / total_num
print('第{0}轮Epoch迭代的准确度: acc = {1}'.format(epoch_no, acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 七、整体数据迭代多次梯度下降来更新模型参数
def train():
epoch_count = 1 # epoch_count为整体数据集迭代梯度下降次数
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no)
evluation(epoch_no)
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
if __name__ == '__main__':
train()
打印结果:
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000, 1)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'numpy.ndarray'>
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000,)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'tensorflow.python.framework.ops.EagerTensor'>
db_train = <ShuffleDataset shapes: ((32, 32, 3), ()), types: (tf.float32, tf.int32)>,type(db_train) = <class 'tensorflow.python.data.ops.dataset_ops.ShuffleDataset'>
db_batch_train = <BatchDataset shapes: ((None, 32, 32, 3), (None,)), types: (tf.float32, tf.int32)>,type(db_batch_train) = <class 'tensorflow.python.data.ops.dataset_ops.BatchDataset'>
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 2, 2, 512) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 1, 1, 512) 0
=================================================================
Total params: 9,404,992
Trainable params: 9,404,992
Non-trainable params: 0
_________________________________________________________________
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 300) 153900
_________________________________________________________________
dense_1 (Dense) (None, 200) 60200
_________________________________________________________________
dense_2 (Dense) (None, 100) 20100
=================================================================
Total params: 234,200
Trainable params: 234,200
Non-trainable params: 0
_________________________________________________________________
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第1个batch step的初始时的:MSE_Loss = 4.605105400085449
grad1:grad.shape = (3, 3, 3, 64),grad.ndim = 4
grad2:grad.shape = (64,),grad.ndim = 1
grad3:grad.shape = (3, 3, 64, 64),grad.ndim = 4
grad4:grad.shape = (64,),grad.ndim = 1
grad5:grad.shape = (3, 3, 64, 128),grad.ndim = 4
grad6:grad.shape = (128,),grad.ndim = 1
grad7:grad.shape = (3, 3, 128, 128),grad.ndim = 4
grad8:grad.shape = (128,),grad.ndim = 1
grad9:grad.shape = (3, 3, 128, 256),grad.ndim = 4
grad10:grad.shape = (256,),grad.ndim = 1
grad11:grad.shape = (3, 3, 256, 256),grad.ndim = 4
grad12:grad.shape = (256,),grad.ndim = 1
grad13:grad.shape = (3, 3, 256, 512),grad.ndim = 4
grad14:grad.shape = (512,),grad.ndim = 1
grad15:grad.shape = (3, 3, 512, 512),grad.ndim = 4
grad16:grad.shape = (512,),grad.ndim = 1
grad17:grad.shape = (3, 3, 512, 512),grad.ndim = 4
grad18:grad.shape = (512,),grad.ndim = 1
grad19:grad.shape = (3, 3, 512, 512),grad.ndim = 4
grad20:grad.shape = (512,),grad.ndim = 1
grad21:grad.shape = (512, 300),grad.ndim = 2
grad22:grad.shape = (300,),grad.ndim = 1
grad23:grad.shape = (300, 200),grad.ndim = 2
grad24:grad.shape = (200,),grad.ndim = 1
grad25:grad.shape = (200, 100),grad.ndim = 2
grad26:grad.shape = (100,),grad.ndim = 1
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第2个batch step的初始时的:MSE_Loss = 4.605042934417725
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 3,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第3个batch step的初始时的:MSE_Loss = 4.604988098144531
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 4,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第4个batch step的初始时的:MSE_Loss = 4.6049394607543945
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 5,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第5个batch step的初始时的:MSE_Loss = 4.604981899261475
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 6,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第6个batch step的初始时的:MSE_Loss = 4.604642391204834
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 7,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第7个batch step的初始时的:MSE_Loss = 4.604847431182861
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 8,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第8个batch step的初始时的:MSE_Loss = 4.604538440704346
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 9,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第9个batch step的初始时的:MSE_Loss = 4.604290008544922
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 10,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第10个batch step的初始时的:MSE_Loss = 4.603418827056885
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 11,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第11个batch step的初始时的:MSE_Loss = 4.603573322296143
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 12,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第12个batch step的初始时的:MSE_Loss = 4.6028618812561035
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 13,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第13个batch step的初始时的:MSE_Loss = 4.602911472320557
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 14,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第14个batch step的初始时的:MSE_Loss = 4.600880146026611
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 15,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第15个batch step的初始时的:MSE_Loss = 4.601419925689697
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 16,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第16个batch step的初始时的:MSE_Loss = 4.601880073547363
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 17,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第17个batch step的初始时的:MSE_Loss = 4.596737384796143
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 18,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第18个batch step的初始时的:MSE_Loss = 4.593438625335693
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 19,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第19个batch step的初始时的:MSE_Loss = 4.589395523071289
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 20,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第20个batch step的初始时的:MSE_Loss = 4.584603786468506
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 21,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第21个batch step的初始时的:MSE_Loss = 4.579631328582764
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 22,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第22个batch step的初始时的:MSE_Loss = 4.5727949142456055
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 23,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第23个batch step的初始时的:MSE_Loss = 4.568104267120361
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 24,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第24个batch step的初始时的:MSE_Loss = 4.55913782119751
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 25,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第25个batch step的初始时的:MSE_Loss = 4.540274143218994
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 51.0
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 39.0
epoch_no = 1, batch_step_no = 3,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 41.0
epoch_no = 1, batch_step_no = 4,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 43.0
epoch_no = 1, batch_step_no = 5,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 47.0
total_correct = 221---total_num = 10000
第1轮Epoch迭代的准确度: acc = 0.0221
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
Process finished with exit code 0
参考资料:
彻底搞懂感受野的含义与计算
CS231n Convolutional Neural Networks for Visual Recognition
How convolutional neural networks see the world
CNN visualization toolkit:Understanding Neural Networks Through Deep Visualization
CNN visualization toolkit:3D Visualization of a Convolutional Neural Network
How to let machine draw an image: (PixelRNN) Pixel Recurrent Neural Networks
How to let machine draw an image:(VAE) Auto-Encoding Variational Bayes
How to let machine draw an image:(GAN) Generative Adversarial Networks
激活函数博客01
激活函数博客02
激活函数博客03
激活函数博客04
卷积神经网络(CNN)的参数优化方法
卷积神经网络的训练过程
从神经网络到卷积神经网络(CNN)
卷积核(kernel)和过滤器(filter)的区别
卷积神经网络(CNN)学习笔记
YJango的卷积神经网络——介绍