Linux:为什么性能工具需要 BPF 技术
了解更多BPF技术内幕,推荐阅读《BPF之巅:洞悉Linux系统和应用性能》一书。
▼
BPF是近年来Linux 系统技术领域一个巨大的创新。作为 Linux 内核的一个关键发展节点,其重要程度不亚于虚拟化、容器、SDN 等技术。
▼BPF 的工作方式十分有趣 :
最终用户使用 BPF 虚拟机的指令集(也称 BPF 字节码)定义过滤器表达式,然后传递给内核,由解释器执行。这使得包过滤可以在内核中直接进行,避免了向用户态进程复制每个数据包,从而提升了数据包过滤的性能,tcpdump(8) 就是这样工作的。
BPF 还提供了安全性保障,因为用户定义的过滤器在执行前必须首先通过安全性验证。
早期的包过滤必须在内核空间执行,安全是一个硬性要求。大家可以从下图了解这一切是如何工作的。
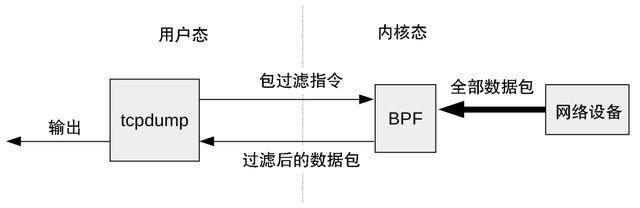
tcpdump 和 BPF
在运行 tcpdump(8) 时带上命令行参数 -d,可以打印出使用过滤器表达式的 BPF 指令。例如 :
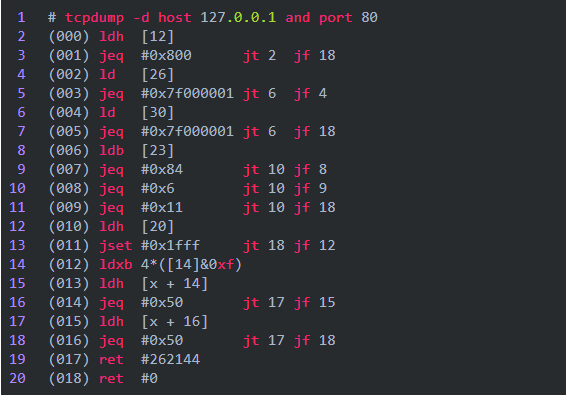
▊ 经典 BPF 与扩展版 BPF
最初的 BPF 现在被称为“经典 BPF”,它是一个功能有限的虚拟机。它有两个寄存器,一个由 16 个内存槽位组成的临时存储区域和一个程序计数器。以上部件均按 32 位寄存器大小运行。经典 BPF 于 1997 年进入 Linux 内核版本 2.1.75。
而后Alexei Starovoitov 创造了扩展版 BPF(eBPF)。这是 20 年来 BPF 的第一次重大更新,此举也将 BPF 扩展为一个通用的虚拟机。
虽然BPF通常被称为虚拟机,不过这往往指的是它的实现规范。BPF在Linux中的实际实现(运行时支持)同时包括一个解释器和一个可即时编译为本机指令的编译器。
“虚拟机”一词似乎意味着在处理器之上运行另一个机器层,而实际BPF执行并非如此。JIT编译后的代码会像任何其他本地内核代码一样,直接在处理器上运行。要注意,在Spectre漏洞公布之后,一些发行版默认在x86架构上启用JIT,完全移除了内核中的解释器实现(通过条件编译直接排除了相关代码)。
扩展版的 BPF 中增加了更多寄存器,并将字长从 32 位增至 64 位,创建了灵活的BPF 映射型存储(map),并允许调用一些受限制的内核功能。同时,eBPF 被设计为可以使用即时编译(JIT),机器指令与寄存器可以一对一映射。这就使得先前的处理器本地指令优化技术,可以重用于 BPF 之上。BPF 验证器也进行了更新以便支持这些扩展,而且能够拒绝任何不安全的代码。
经典 BPF 和扩展版 BPF 之间的差异如下。

在最早的代码补丁中,扩展版BPF曾被简写为 eBPF,不过如今有关的开发讨论中,都直接使用BPF 这种叫法。
Linux BPF 运行时(runtime)的各模块的架构如下图。
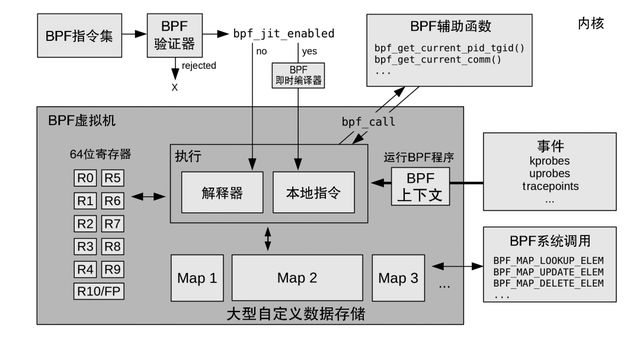
BPF 运行时的内部结构
上图展示了 BPF 指令如何通过 BPF 验证器验证,再由 BPF 虚拟机执行。
BPF 虚拟机的实现既包括一个解释器,又包括一个 JIT 编译器 :JIT 编译器负责生成处理器可直接执行的机器指令。验证器会拒绝那些不安全的操作,这包括针对无界循环的检查 :BPF 程序必须在有限的时间内完成。
BPF 可以利用辅助函数获取内核状态,利用 BPF 映射表进行存储。BPF 程序在特定事件发生时执行,包括 kprobes、uprobes 和跟踪点等事件。
接下来我们来讨论一下,为什么性能工具需要 BPF 技术。
▊ 为什么性能工具需要 BPF 技术
性能工具使用扩展版 BPF 来实现可编程性。BPF 程序可以执行自定义的延迟计算和统计摘要等功能。这些特性本身就足够使 BPF 成为一个有趣的工具。
不过事实上有很多跟踪工具都具备了这些功能。BPF 与众不同之处在于,它还同时具备高效率和生产环境安全性的特点,并且它已经被内置在 Linux 内核中。
有了 BPF,你就可以在生产环境中直接运行这些工具,而无须增加新的内核组件。
▼
下面我们通过一个工具的输出和一幅图来看一下性能工具是如何使用 BPF 的。
这个 例子的输出来自性能优化大师Gregg以前发布的一个叫作 bitehist 的 BPF 工具,它用直方图的形式展示磁盘 I/O 的尺寸分布:
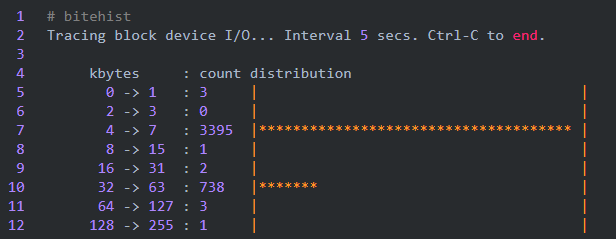
下图显示了使用 BPF 之前和之后的直方图生成过程。

使用 BPF 之前和之后生成直方图过程的对比
这里的关键变化是,直方图可以在内核上下文中生成,这大大减少了需要复制到用户空间的数据量。这里的效率提升是如此的显著,以至于工具的额外开销减小到可以在生产环境下直接运行的程度。
使用 BPF 之前,制作这一直方图摘要的最佳步骤如下。
1.在内核中 :开启磁盘 I/O 事件的插桩观测。
2.在内核中,针对每个事件 :向 perf 缓冲区写入一条记录。如果使用了跟踪点技术(推荐方式),记录中会包含关于磁盘 I/O 的几个元数据字段。
3. 在用户空间 :周期性地将所有事件的缓冲区内容复制到用户空间。
4. 在用户空间 :遍历每个事件,解析字节字段的事件元数据字段。其他字段会被忽略。
5. 在用户空间 :生成字节字段的直方图摘要
其中步骤 2 到步骤 4 对于高 I/O 的系统来说性能开销非常大。可以想象一下,将 10000个磁盘 I/O 跟踪记录复制到用户空间程序中,然后解析以生成摘要信息—每秒执行 1 次。
使用 BPF 之后,bitesize 程序执行的步骤如下。
1. 在内核中:启用磁盘 I/O 事件的插桩观测,并挂载一个由 bitesize 工具定义的BPF 程序。
2. 在内核中,对每次事件 :运行 BPF 程序。它只获取字节字段,并将其保存到自定义的 BPF 直方图映射数据结构中。
3.在用户空间 :一次性读取 BPF 直方图映射表并输出结果。
这个过程避免了将事件复制到用户空间并再次对其处理的成本,也避免了对未使用的元数据字段的复制。如前面的程序输出截图所示,唯一需要复制到用户空间的数据是“count”列,其是一个数字数组。
▊ BPF 与内核模块的对比
还有一种方法可以理解 BPF 在可观测性方面的优势 :将其与内核模块进行比较。
kprobes 和跟踪点已经出现多年了,可以直接从可加载的内核模块中使用。与使用内核模块相比,使用 BPF 进行跟踪的优势如下 :
● BPF 程序会通过验证器的安全性检查 ;内核模块则可能会引入 bug(内核崩溃)或安全漏洞。
● BPF 通过映射提供丰富的数据结构支持。
● BPF 程序可以一次编译,然后在任何地方运行,因为 BPF 指令集、映射表结构、辅助函数和相关基础设施属于稳定的 ABI。(当然,有些 BPF 程序包含了不稳定的因素,比如使用了 kprobes 来观测内核数据结构,这会影响 BPF 程序的自身稳定性)
● BPF 程序的编译不依赖内核编译过程的中间结果。
● 与开发内核模块所需的工程量相比,BPF 编程更加易学,可以让更多人上手。
请注意,在网络领域应用 BPF 还有额外的好处,包括原子性替换 BPF 程序的能力。如果使用内核模块,则需要先从内核中将其完全卸载,然后再次加载,这可能会导致相关服务中断。
使用内核模块的一个好处是 :在模块中可以使用其他内核函数和内核设施,而不仅限于 BPF 提供的辅助函数。
不过,如果调用任意内核函数的能力被滥用,也会带来引入bug 的额外风险。
了解更多BPF技术内幕,推荐阅读《BPF之巅:洞悉Linux系统和应用性能》一书。

▊《BPF之巅:洞悉Linux系统和应用性能》
【美】Brendan Gregg 著
孙宇聪 吕宏利 刘晓舟 译
- Gregg大师新作,《性能之巅》再续新篇
- 性能优化的万用金典,150+分析调试工具深度剖析
本书作为全面介绍 BPF 技术的图书,从 BPF 技术的起源到未来发展方向都有涵盖,不仅全面介绍了 BPF 的编程模型,还完整介绍了两个主要的 BPF 前端编程框架 — BCC 和 bpftrace,更给出了一系列实现范例,生动展示了 BPF技术的实际能力和未来发展前景。