大数据入门级学习——Hadoop集群搭建总结(VM+centOS7)
步入大数据的第一步:
必须学会搭建大数据集群的框架
那么第一步必须要在linux系统上搭建Hadoop集群
目录
一、安装并配置虚拟机(centOS7)
二、克隆出三台虚拟机
三、安装及配置JDK
四、安装Hadoop
五、Hadoop的三种运行模式学习过程
1.本地运行模式
官方Grep案例过程记录
官方WordCount案例过程记录
2.伪分布式运行模式
启动HDFS并运行MapReduce程序
启动YARN并运行MapReduce程序
配置历史服务器
配置日志的聚集
3.完全分布式运行模式
SSH无密登录模式
群起集群
一、安装并配置虚拟机(centOS7)
先在VM中创建一台虚拟机(VM傻瓜式安装即可):

下面简单介绍一下安装centOS7的过程:
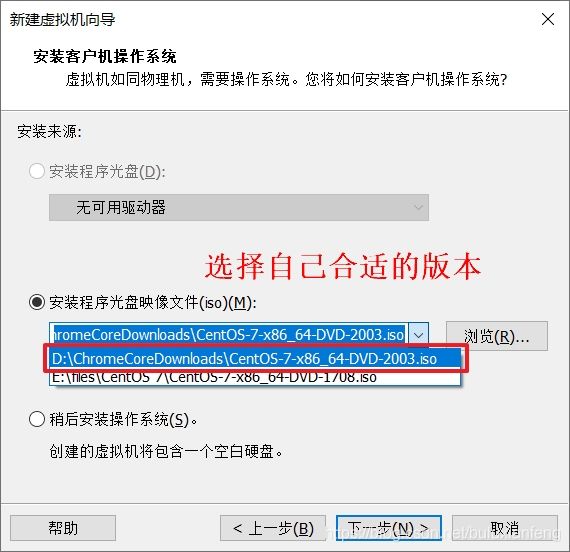

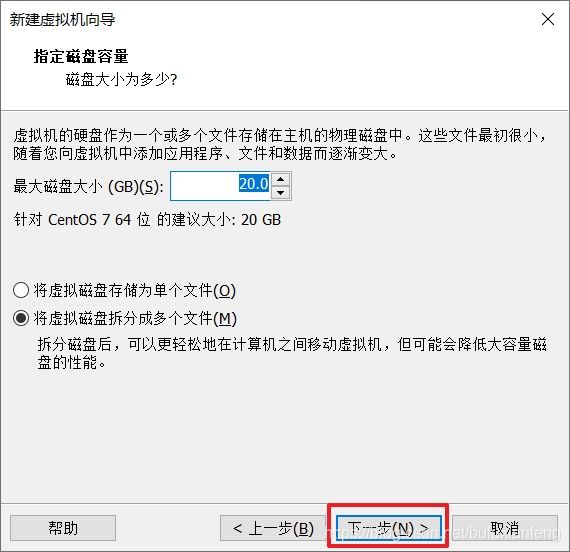
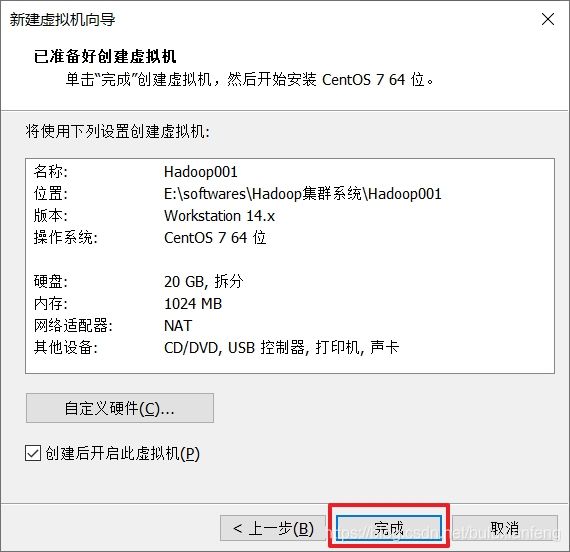
安装centOS7的过程(安装桌面版):

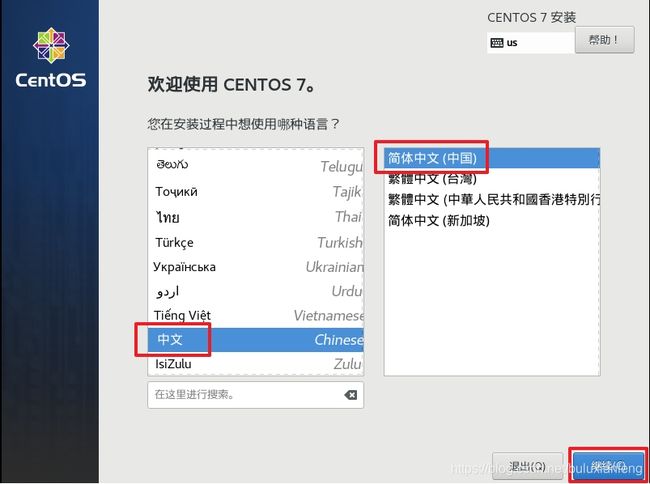




安装完成,下面开始配置:
注意:centOS6与centOS7的配置选项不同!(如果安装的是centOS6,最后的文件夹为.../ifcfg-ens0)

这是原文件的内容(暂不做修改,下文做修改):

修改过程如下:
查看VM的虚拟网络编辑器:
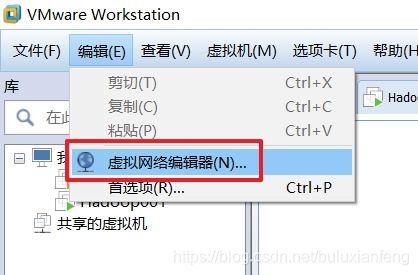

选择VMnet8查看其中的DHCP设置和NAT设置:

注意:这是起始和结束的IP地址,每台机器的IP地址不同,不能直接照搬!
网关查看方法如下:

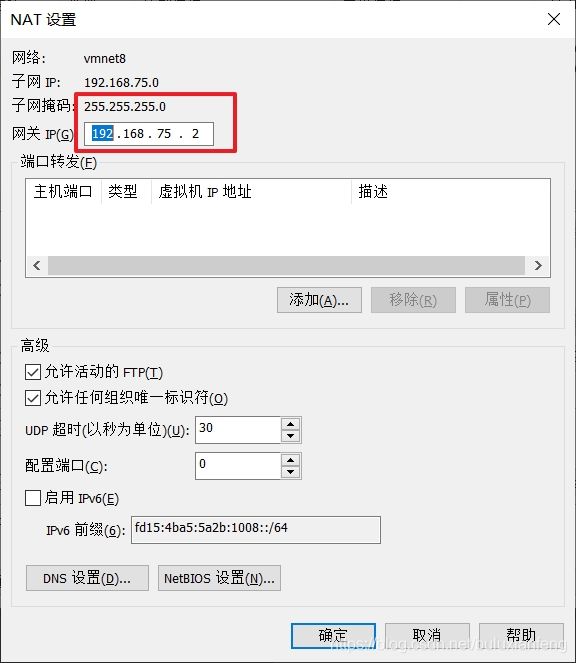
现在可以按照上述查看出的配置信息修改文件中内容:

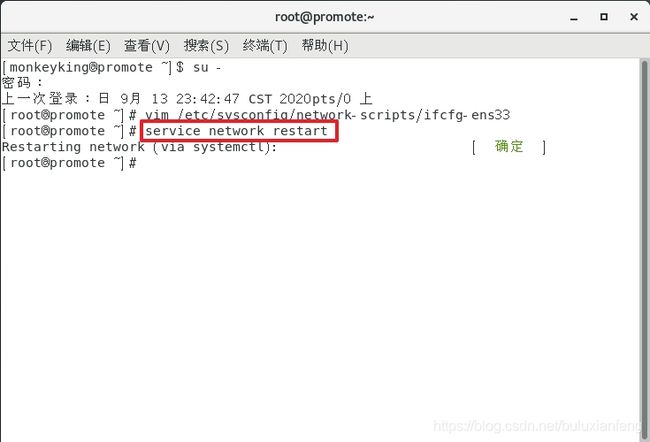
配置结束,重启网络:
service network restart
尝试ping百度和本机电脑的IP地址,查看网络的连通性:

在本机查看IP地址并连接虚拟机:



均成功,说明文件修改成功,如果没有成功,请按照上述步骤重新配置。
二、克隆出三台虚拟机
关闭虚拟机,并克隆:





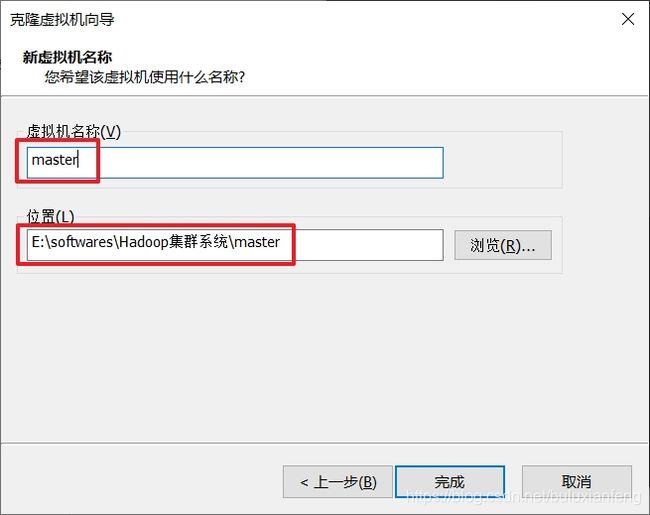
省略剩余两台虚拟机的克隆过程...(取名Hadoop002和Hadoop003)
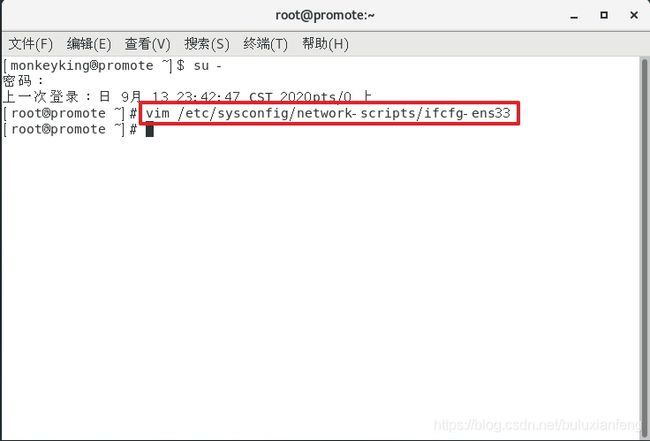

在虚拟机中更改名字:
vi /etc/hostname然后重启生效:
reboot更改所有虚拟机中的名字:
vim /etc/hosts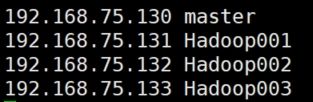
注意:填写正确的IP地址和主机名(并且不能有空格)
在本机也相应修改IP地址和主机名:
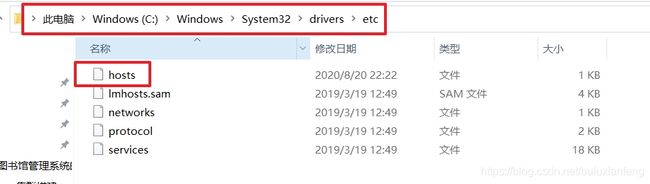

同样配置如上图的IP地址和主机名。
三、安装及配置JDK
Linux下(centOS7中)安装以及配置JDK
四、安装Hadoop
本文先安装Hadoop2.7.2,下载链接:
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
将安装包hadoop-2.7.2.tar.gz导入至opt目录下的software中(可用XShell中的sftp或者FileZilla传输)
在software中解压文件到module文件夹中:
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/将Hadoop添加到环境变量中:
sudo vi /etc/profile添加如下内容:
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让文件立即生效:
source /etc/profile测试安装是否成功:

安装成功,如果没有跳转出来,可以尝试重启机器!
五、Hadoop的三种运行模式学习过程
-
本地运行模式
-
伪分布式运行模式
-
完全分布式运行模式
1.本地运行模式
(总结)本地运行模式不需要启用单独进程,直接可以运行,适合测试和开发时使用。
有以下特征:
- Hadoop默认处于该模式下,并且使用于开发和测试;
- 不对配置文件进行修改;
- 使用本地文件系统而并非分布式文件系统;
- 不会启动NameNode、DataNode等进程,用于对MapReduce程序的逻辑进行测试。
官方Grep案例过程记录
进行字符匹配的练习:
// 1.创建input文件夹
mkdir input
// 2.将etc/hadoop下的xml文件全部copy到input目录下
cp etc/hadoop/*.xml input
// 3.执行mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
// 4.查看output文件夹下的所有内容
cat output/*执行完毕出现以下结果:

说明执行成功!
可以查看结果:
cat part-r-00000官方WordCount案例过程记录
进行文件中的重复字符的个数:
// 1.创建一个文件夹
mkdir wcinput
// 2.创建一个文件
cd wcinput
touch wc.input
// 3.编辑文件,在文件中添加重复的字符
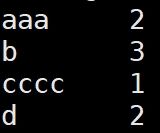
vim wc.input
(内容如下)
aaa aaa
b b b
cccc
d d
// 4.返回hadoop-2.7.2目录下,执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
// 5.查看结果
cat wcoutput/part-r-00000
查看结果如下:
两个案例均在本地执行完毕,本地模式所展示的内容到此结束,由于使用该模式较少,了解即可!
2.伪分布式运行模式
(总结)伪分布式模式在单节点上同时启动Namenode、Datanode、Jobtracker、Tasktracker、Secondarynamenode等5个进程,模拟分布式运行的各个节点。
有以下特征:
- 在一台服务器上模拟多台主机工作;
- Hadoop启动NameNode、DataNode、JobTracker、TaskTracker、Secondarynamenode的守护进程,并且独立;
- Hadoop使用分布式文件系统,每个作业也是由JobTraker服务,并且管理这些独立的进程;
- 在本地模式上增加了代码调试的功能,允许检查内存的使用情况,HDFS的输入输出,以及其他守护进程的交互,类似于完全分布式系统;
- 这种模式常用来开发测试Hadoop程序的执行是否正确;
- 需要格式文件系统。
搭建伪分布式运行模式,其实就是配置完全分布式模式的前奏,需要配置文件信息保证程序的正常运行。
启动HDFS并运行MapReduce程序
首先,配置hadoop-env.sh文件信息:
// 1.获得JAVA_HOME的路径
echo $JAVA_HOME
// 2.在hadoop-env.sh文件中修改
export JAVA_HOME=/opt/module/jdk1.8.0_144如图所示:

接着,配置core-site.xml文件信息:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
接着,配置hdfs-site.xml文件信息:
dfs.replication
1
启动集群:
// 1.格式化NameNode
bin/hdfs namenode -format
(注意!只需要第一次启动时格式化,频繁格式化会导致错误,博主有一篇博客的错误发生在这里)
// 2.启动NameNode
sbin/hadoop-daemon.sh start namenode
// 3.启动DataNode
sbin/hadoop-daemon.sh start datanode查看集群:
jps会出现Jps,NameNode,DataNode三个节点的信息。
web端查看HDFS文件系统:
http://master:50070/dfshealth.html#tab-overview

查看产生的log日志文件信息:
// 在hadoop-2.7.2的logs目录下
ls操作集群:
// 1.在HDFS文件系统上创建一个input文件夹
bin/hdfs dfs -mkdir -p /user/master/input
// 2.将测试文件内容上传到文件系统上
bin/hdfs dfs -put wcinput/wc.input /user/master/input/
// 3.查看上传的文件是否正确
bin/hdfs dfs -ls /user/master/input/
bin/hdfs dfs -cat /user/master/ input/wc.input
// 4.运行MapReduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/master/input/ /user/master/output
// 5.查看输出结果
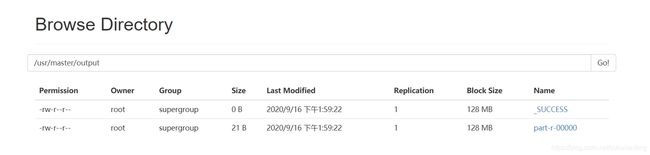
bin/hdfs dfs -cat /user/master/output/*
// 6.将测试文件内容下载到本地
hdfs dfs -get /user/master/output/part-r-00000 ./wcoutput/
// 7.删除输出结果
hdfs dfs -rm -r /user/master/output
浏览器中查看内容如下:
启动YARN并运行MapReduce程序
同理,首先要配置相关文件的信息:
首先,配置yarn-env.sh文件信息:
// 将JAVA_HOME插入到文件中去
export JAVA_HOME=/opt/module/jdk1.8.0_144接着,配置yarn-site.xml文件信息:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
接着,配置mapred-env.sh文件信息:
// 将JAVA_HOME导入到文件中
export JAVA_HOME=/opt/module/jdk1.8.0_144接着配置mapred-site.xml.template文件信息:
// 1.将其重命名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
// 2.修改文件信息
mapreduce.framework.name
yarn
启动集群:
// 1.刚刚已经启动了NameNode和DataNode,如果关闭则需要重新启动
// 2.启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
// 3.启动NodeManager
sbin/yarn-daemon.sh start nodemanagerYARN的浏览器页面查看地址:
http://master:8088/cluster

// 1.删除文件系统上的output文件
bin/hdfs dfs -rm -R /user/master/output
// 2.执行MapReduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/master/input /user/master/output
// 3.查看运行结果
bin/hdfs dfs -cat /user/master/output/*页面显示结果如下:

配置历史服务器
首先,配置mapred-site.xml文件信息:
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
启动历史服务器:
sbin/mr-jobhistory-daemon.sh start historyserver网页中查看JobHistoryServer:
http://master:19888/jobhistory
网页查看结果如下:

配置日志的聚集
配置日志文件信息的聚集,首先必须需要重新启动NodeManager 、ResourceManager和HistoryManager节点,否则可能会报错。
配置日志文件信息聚集的好处:可以方便的查看到程序运行详情,方便开发调试。
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
开启日志聚集的步骤如下:
首先,配置yarn-site.xml文件信息:
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
重新启动NodeManager 、ResourceManager和HistoryManager节点:
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
// 1.删除HDFS上已经存在的输出文件
bin/hdfs dfs -rm -R /user/master/output
// 2.执行WordCount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/master/input /user/master/output
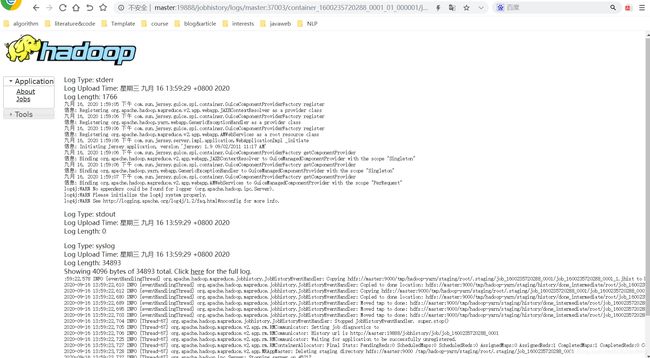
现在可以在刚刚的网址上,点击查看具体日志文件信息。
如下图所示:

整体伪分布式运行模式已经介绍完毕,详细的过程可以参考下面的完全分布式运行模式,毕竟完全分布式模式运用更多!
3.完全分布式运行模式
(总结)完全分布式运行模式真正用于实际生活应用中,用户进程运行在多主机搭建的集群上。
有以下特征:
- 在所有主机上安装JDK和Hadoop,并且互联互通;
- 能够免密SSH进行登录;
- 需要修改每台主机的文件系统,配置相关文件,每台主机各司其职,做好集群中的工作;
- 需要格式化文件系统。
完全分布式运行模式我们需要准备三台同样的虚拟机,在不同的虚拟机上进行不同的配置操作。
首先,进行同步操作,有几种不同的方法:
方法一:
使用scp安全拷贝,该方法能实现服务器与服务器之间的数据拷贝,例如:
// 将hadoop001上的opt/module以及etc/profile上的文件进行拷贝到hadoop002上
scp -r /opt/module root@hadoop002:/opt/module
sudo scp /etc/profile root@hadoop002:/etc/profile
(同理,可以将hadoop001上的文件拷贝到hadoop002以及hadoop003上,不再赘述)方法二:
使用rsync 远程同步工具,该方法不同于scp的地方在于速度快,以及高效,它仅复制文件中有差异的地方,相同的地方不再复制,会省去不少的时间。
选项参数说明:
| 选项 | 功能 |
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
// 将hadoop001的opt/module复制到hadoop002的目录下
rsync -rvl /opt/software/ root@hadoop002:/opt/software方法三:
使用xsync集群分发脚本,使文件能够循坏地分发到所有主机的相同目录下。
首先,在根目录下创建文件夹并创建xsync文件,命令如下:
mkdir bin
cd bin/
touch xsync
vim xsync
(编写代码如下:)
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop00$host:$pdir
done

// 修改xysnc具有执行权限
chmod 777 xsync
// 脚本调用形式
xsync 文件名称集群部署规划:
| hadoop001 | hadoop002 | hadoop003 | |
| HDFS | NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
根据上述表格信息配置集群核心文件:
配置core-site.xml文件信息:
fs.defaultFS
hdfs://hadoop001:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
HDFS配置文件:
// 1.配置hadoop-env.sh文件(添加JAVA_HOME的依赖环境)
export JAVA_HOME=/opt/module/jdk1.8.0_144
// 2.配置配置hdfs-site.xml文件
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop003:50090
YARN配置文件:
// 1.配置yarn-env.sh文件(添加JAVA_HOME的依赖环境)
export JAVA_HOME=/opt/module/jdk1.8.0_144
// 2.配置yarn-site.xml文件
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop002
MapReduce配置文件:
// 1.配置mapred-env.sh(添加JAVA_HOME依赖环境信息)
export JAVA_HOME=/opt/module/jdk1.8.0_144
// 2.配置mapred-site.xml(修改名称)
cp mapred-site.xml.template mapred-site.xml
编辑内容:
mapreduce.framework.name
yarn
在集群上发布配置好的文件:
xsync /opt/module/hadoop-2.7.2/集群的单点启动:
同伪分布式运行模式,区别就是在不同的主机上启动相应的节点信息,并查看是否启动成功。
SSH无密登录模式
利用SSH免密登录可以节约远程登录访问时要输入密码的麻烦,减少访问的时间,更加快捷高效地使集群工作。
基本思想为非对称加密,防止秘钥泄露,公钥加密,私钥解密,公钥公开而私钥不公开,但是一旦私钥泄露那么安全性就无从考证。
免密登录配置过程:
// 在~/.ssh目录下生成公钥和私钥
ssh-keygen -t rsa
// 将公钥拷贝到需要登录的目标机器上(hadoop001上)
ssh-copy-id hadoop001
ssh-copy-id hadoop002
ssh-copy-id hadoop003
(同理在hadoop002以及hadoop003上配置).ssh文件夹下的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
群起集群
配置slaves文件:
// 路径:/opt/module/hadoop-2.7.2/etc/hadoop/slaves
文件中增加:
hadoop001
hadoop002
hadoop003
// 同步所有节点的文件信息
xsync slaves如果集群是第一次启动,需要格式化NameNode,同上不能多次格式化,容易出现不可解决的错误。
// 启动HDFS/YARN
sbin/start-dfs.sh
sbin/start-yarn.sh通过jps进行查询每个主机的节点时,发现每个主机都各司其职,启动节点各不相同。
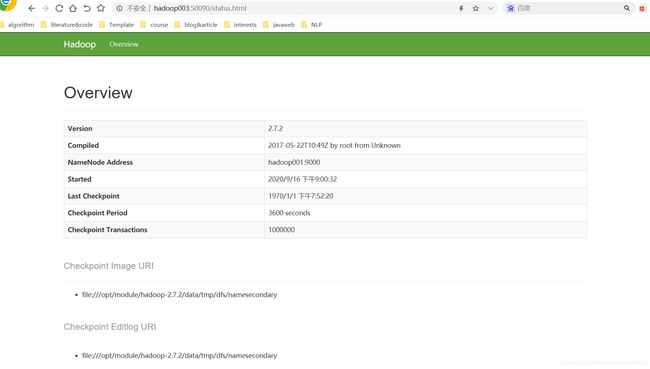
web端查看SecondaryNameNode:
http://hadoop003:50090/status.html
上传、下载、删除等操作和伪分布式运行模式相近,这里不再举例。
集群整体的启动、停止:
// 1.分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
// 2.启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
// 3.整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
// 4.整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
集群时间同步:找一台服务器作为时间服务器,进行校准,所有的机器与这台集群时间进行定时的同步。
至此,所有三大模式一一介绍总结完毕!
欢迎关注博主,欢迎互粉,一起学习!
感谢您的阅读,不足之处欢迎指正!