Hadoop2.x的集群搭建与配置(七)——Hadoop安装与配置
这一步开始正式搭建hadoop,但是要确保前面的每一步都完成
首先要下载一个一些工具:
1.hadoop的安装包,linux版本的,后缀名市是tar.gz的这种
2.跨平台数据传输工具,这里推荐使用xshell和xftp,xshell用来链接linux,而xftp则用来将一些文件从本机传到linux中(这个是在本机安装的,不要放到虚拟机里)
第一步:将hadoop的安装包传输到master中,然后解压:tar -xvf hadoop2.x.x.tar.gz
第二步:hadoop配置部署:
1. cd /etc/Hadoop (保证在hadoop2.x.x目录中), 在这里将centOS文件目录切换到Hadoop文件夹下
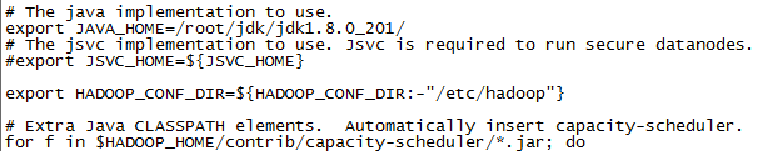
2. vi hadoop-env.sh 使用vi或者vim编辑器打开hadoop-env.sh这个配置文件,要在这里告诉hadoop,jdk的路径在哪里。打开的配置文件本身会有内容,找到和下面图片差不多的位置进行修改,下面的操作同样。
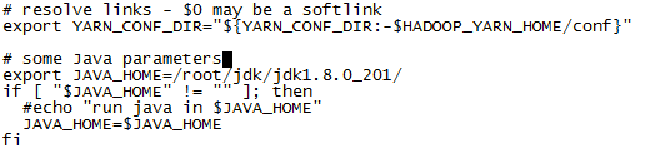
3. vi yarn-env.sh 同样用vi/vim打开yarn-env.sh配置文件,顾名思义,这里是用来管理yarn的配置文件。不过这里只写最基本的,用来能够让hadoop启动运行的简单配置,这里告诉yarn,JDK放在哪里了
4. vi core-site.xml 这里要配置的时核心组件!这个非常重要,有很多种配置方法,同样也有很多种属性可以进行配置。我们同样只挑选最基本,能够让集群起来并使用的配置。这里大致的意思就是配置默认的文件系统端口为master节点的9000端口,并且设置hadoop.tmp.dir的路径,这个路径里面将会存放特别重要的配置文件,不能大意了
5. cd 这里返回根目录,方便创建文件夹(就是创建上面的hadoop.tmp.dir,如果细心的话你会发现这个文件夹时根本不存在的)
mkdir /root/hadoopdata
6. vi hdfs-site.xml 配置文件系统HDFS,因为我们建立的是节点很少的伪分布式,所以就设置hdfs文件自动拷贝这个机制默认就在别的节点复制一次就行,多了不大号,很大概率出问题
7. vi yarn-site.xml 配置yarn
8. 这里要配置计算框架,也就是传说中的mapreduce!操作并不嫩,但却不只是一个指令的问题了,注意看!
cp mapred-site.xml.template mapred-site.xml 这里献给配置文件做出一个他该有的样子
vi mapred-site.xml 编辑配置文件,内容如下:
9. vi slaves 配置slaves文件,用来管理master手下的slave节点们,在文件里写上子节点的名字(一行一个),比如我就只有一个叫做’slave‘的子节点,那就只写:
slave
10. master的配置改就这样,下面要把相应的配置拷贝到slave节点上
scp -r hadoop-x.x.x root@slave:~/ 这里运用scp指令,把hadoop.x.x.x文件夹整体拷贝到名为slave的节点中根目录下,大街根据自己的集群信息进行修改
11. 配置hadoop启动系统环境变量
cd
vi .bash_profile 还有其他方法,我更偏爱这种,下面开始配置环境变量,要把hadoop的环境,路径啥的向JDK一样卸载系统环境变量里,一家人就是要整整齐齐嘛!
这里配置好了不要忘记像JDK一样刷新配置文件,不然不生效下面就要坏事!
export HADOOP_HOME=/root/hadoop-2.5.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
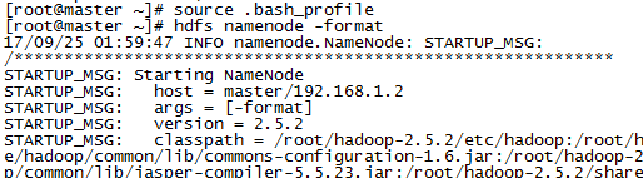
12. hdfs namenode -formate 格式化文件系统,指令运行之后会弹出很多东西,抓重点看成功与否,失败了的话看看前面哪错了,实在不行重新来过,集群是要反反复复搭建几遍才会熟能生巧的。大概的样子如下:
13. cd hadoop-x.x.x/sbin 启动Hadoop的第一步就是进入sbin文件夹(别人我轻易不说,因为启动文件在这里)
14. ./start-all.sh 打开hadoop启动文件:start-all.sh (其实配置过hadoop环境变量后这个语句应该可以在根目录直接运行的)
15. 这个时候hadoop已经启动,我们使用JSP指令查看进程,看看有效进程是否一一启动,没有的话去前面抠细节,看看哪里出的问题
指令: jsp
运行结果应该是:
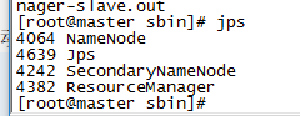
Master节点至少要有:
Jsp(这个有没有都行,没有只能说明你电脑有毒)
NameNode
SecondaryNamenode
ResourceManager
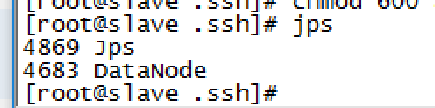
Slave节点至少要有:
Jsp
DataNode
16. 注:启动Hadoop集群:需要关闭CentOS 7 中的firewall才能完全启动集群。
Systemctl start firewalld.service(启动防火墙命令)
Systemctl enable firewalld.service(开机启动防火墙)
Systemctl disable firewalld.service(开机禁用防火墙)
16. 下面运行hadoop自带的实例,测试一下集群好不好用,算Π(pi)值,不过不要对结果的正确性抱有期待:
cd ~/hadoop-x.x.x/share/hadoop/mapreduce/
hadoop jar ~/hadoop-x.x.x/share/hadoop/mapreduce /hadoop-mapreduce-examples-x.x.x.jar pi 10 10
17.启动Hadoop集群:
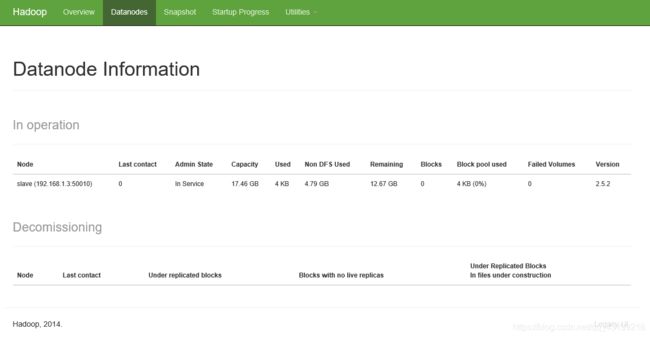
在浏览器中打开:http://master:50070/ (仔细检查是否每个节点都活着)