Python爬虫之批量爬取B站视频封面(内含爬虫概念理解、requests、xpath初级教学及爬虫遇反爬和内容乱码的解决手段)
文章目录(Are you ready?)
- 对于此教程
-
- 1、前言
- 2、什么是网络爬虫?及其合法性
- 3、请求和响应的流程
-
- A、一张自制的流程图(超潦草)
- B、解释一下下
- 4、开机,上号!
-
- A、正式开始前,我们先来做下必要工作!
- B、requests模块的使用(get)
-
- 一.调用模块
- 二.分析B站网页,获取目标所在位置
- 三.通过requests.get()方法获取网站源码
- C、网页元素分析与xpath使用
-
- 一、怎么理解元素层关系?“就是套娃”
- 二、借用浏览器开发者工具进行层分析
- D、使用lxml库的etree类来使用xpath
-
- 一、etree.HTML()与etree.parse()的区别
- 二、xpath基础语法(注意,返回的是列表形式[list])
- E、实现保存与批量爬取
- F、运行演示与最终代码
- 5、处理爬取文本乱码和反爬reapones.content.decode()/headers
对于此教程
未经允许,不可转载!!!如果文章内容有不恰当之处,还请指出!
1、前言
本篇教程比较基础,适合写爬虫没思路、不知道内部机制的萌新看。文章内容可能有点乱,但全是干货!
注:虽然内容基础,但仍需要对python有一定的基础,纯萌新阅读此文可能会有一点吃力
编译工具及环境:
- 操作系统:Windows10
- Python版本:3.7.x
- 使用pip工具(版本20X)
- 编译工具:Pycharm 2020
2、什么是网络爬虫?及其合法性
1.简单的说,网络爬虫就是电脑按照你所编写的代码对网络中资源进行处理,并根据你指定的方式进行保存或其他骚操作。类似于针对网络资源进行批处理
2.爬虫的合法性:这个就很难说了。不过我可以举个栗子,来比喻一下

图片来自网络
刀这种工具大家都知道,都用过,我们平常使用刀都是用来做饭,切东西、拆快递等。但有些亡命之徒用他来sha人,伤害其他人,这使我们知道刀也是一种危险的东西,但我们又不能离开这种工具,不能一拍子全打死,直接将刀禁用,毕竟我们又没违法,对吧。
而Python爬虫合法性也类似于这种概念-----违不违法不取决于这门技术内容,而是取决于使用者的行为
所以我们只要不干违法的事就可以了,其他的可以由我们任意发挥都无所谓。
3、请求和响应的流程
*如果你比较了解可以直接跳过
我们平时在使用浏览器浏览东西时,请求和响应这两个环节可以说是最频繁触发的了,不过,其内容比较简单,可以参考看望病人或串亲戚的流程。
A、一张自制的流程图(超潦草)

这就是一个基础的请求与响应流程,接下来会进行一些小解释
B、解释一下下
其实也没什么好说的

请求时我们的浏览器会发送请求,而请求中会带有一些信息,而这些信息有一个简单易懂的名字----“headers 头(请求头信息)”。
英语好的同学,可能已经发现一点点端倪了,这个header它加了个s
”唉?这是为什么啊,头为什么还可以是复数形式的?“
“因为他有多个头,是个怪物”
这是因为请求头信息有多条,并不是单单只有一条,这就好比你去串亲戚,总不能拿瓶饮料就去吧?(如果你连饮料都不拿,那你真是。。。)肯定要精心准备,多拿些东西,不然没牌face。
而请求头也是这样的,带着多种信息去请求服务器。
*headers是请求信息,且不唯一(也不一定为多个,具体信息数量由服务器决定),同时,这也是服务器检查是否为爬虫的关键
大体解释完了,接下来我们来实战!!!
4、开机,上号!

A、正式开始前,我们先来做下必要工作!
#均使用pip工具,原因:一键式安装,快捷方便
下载Requests库,一切的基础
- requests这个模块会模仿浏览器向网站发送get/post等形式的请求,并且可以返回获取到的网页源码 ,是网络爬虫的必备库
- 优点:与python自带的urllib3库相比,人性化了需多,且操作更加方便,代码更优雅
这里使用了清华的镜像,如果你已经设置过镜像,可以不加-i后缀
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
下载lxml库,解析库
- 内置xpath,我们下载他主要是为了使用xpath
- xpath优点:语法简单、人性化、识别速度快
后文会说明为什么下载此库,现在只做简单解释:为xpath使用做铺垫
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
B、requests模块的使用(get)
一.调用模块
# -*- coding: utf-8 -*-
#名称:bilibili封面批量下载
#作者:漫游感知
#CSDN:https://blog.csdn.net/qq_45429426?spm=1001.2014.3001.5343
import requests
from lxml import etree #这里调用lxml库中的etree方法,来使用etree下的xpath方法
二.分析B站网页,获取目标所在位置
- 我们先随便找一个视频,用浏览器调试工具看一下视频页面下的源码(这里使用Google浏览器)
举例视频URL:https://www.bilibili.com/video/BV1Az4y1S7cY
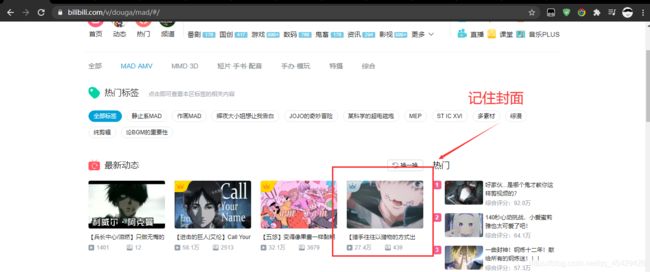
- 接着我们Ctrl+U查看一下网页源码,并搜找.jpg这个关键字
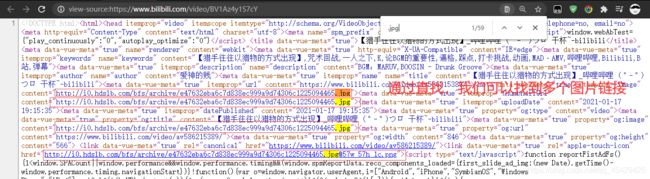
- 其中,这几条链接前三条是一模一样的,比较可疑,所以我们任意选择其中一条,看看是不是封面链接
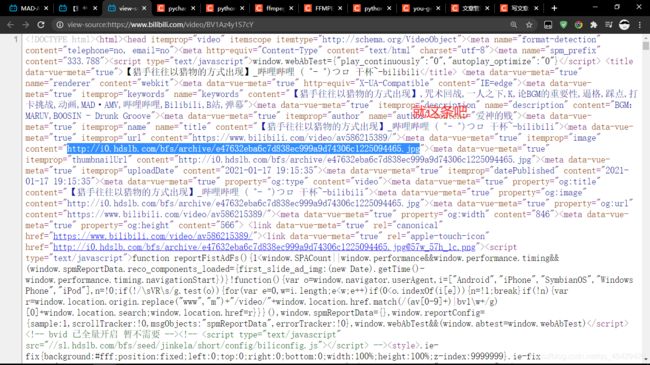
图片URL:http://i0.hdslb.com/bfs/archive/e47632eba6c7d838ec999a9d74306c1225094465.jpg
- 发现和视频封面一样!
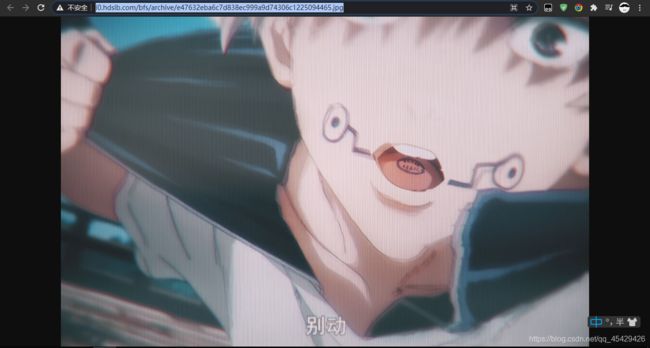
- 由这些可以断定出视频封面在每个视频页面下,接着我们把页面源码复制下来,来分析链接所在元素(先备着,要用)。
- 但在进行元素位置定位前,我们应该先通过python获取页面的源码,这就需要requests.get()方法了
三.通过requests.get()方法获取网站源码
| 方法 | 常用参数 |
|---|---|
| requests.get() | url=* , headers=* |
- 其中url参数传入的必须为一个字符串类型(str)
- headers参数传入的必须为一个字典格式(dict),这个参数的传入内容就是反反爬的关键
实例代码如下(B站貌似并未使用反爬,但为了保证正常,还是先修改了headers,修改方式如下代码。文章第5个部分专讲反爬及headers运用)
# -*- coding: utf-8 -*-
#名称:bilibili封面批量下载
#作者:漫游感知
#CSDN:https://blog.csdn.net/qq_45429426?spm=1001.2014.3001.5343
import requests #发送请求与接收响应数据
from lxml import etree #这里调用lxml中的etree类型为使用xpath铺垫
def bili(url):
"""
这里定义一个名为“bili”的函数,并要求传入一个数值----url
这个函数用于获取视频页面源码
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
} #这里必须是字典格式(键值对形式)
url = str(url) #将传入信息转为字符串(保险)
resp = requests.get(url=url,headers=headers) #发送get请求,并使用自带头信息来进行反反爬
html_text = resp.text #将获取信息转为文本
if resp.status_code == 200: #如果状态码为200(请求成功)则返回网页数据
return html_text
else:
print('Get error')
url = 'https://www.bilibili.com/video/BV1Az4y1S7cY'
get_web = bili(url)
print(get_web)
-
反馈到的信息与网页源码进行比较,会发现数据相同,说明数据爬取成功
-
浏览器网页源码

-
pycharm终端网页源码(获取到的)

整体数据获取没问题了,接下来就是对目标进行定向获取
C、网页元素分析与xpath使用
- 首先我们来到我们前面复制的网页源码文件中,通过Pycharm搜索功能来找到我们确认的链接位置
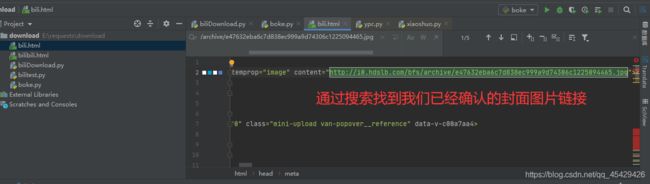
- 接着我们可以从Pycharm编译区的左下方发现一个层关系
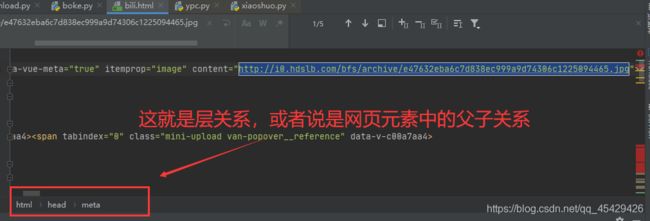
一、怎么理解元素层关系?“就是套娃”
- please look look the photo

在这个图当中,可以把每个矩形方框当做一个盒子,并且较大盒子会包裹较小的盒子(类似套娃)
即:html这个大盒子包裹了head这个较小盒子,这个head盒子又包裹了4个同名的mate盒子及一个oprt盒子等
假设我们需要让电脑取出五角星这个图形,那么我们应该怎么表达呢?
那是不是应该先告诉电脑,去html中(/html),取出head(/html/head),再取出第三个mate(/html/head/mate[3]),最后明确是第三个mate中的五角星(/html/head/mate[3]/@五角星)。
上述这一流程就是xpath语法编写的流程,其中/和@分别类似于路径符号和选择
二、借用浏览器开发者工具进行层分析
- 按F12进行操作
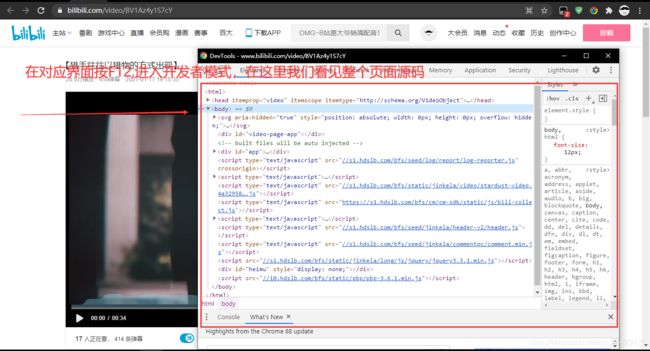
- 进行层分析
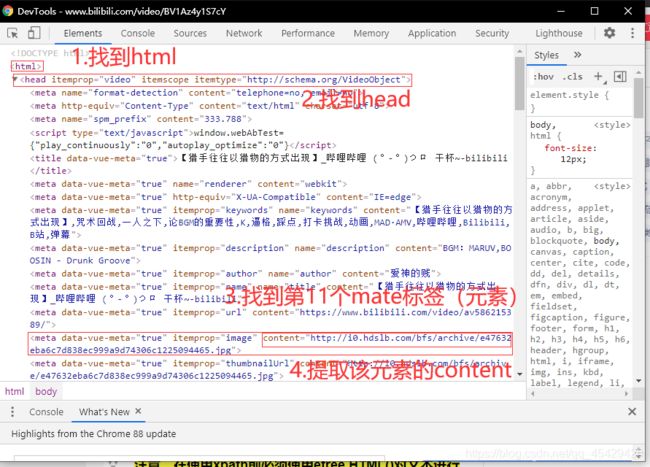
- 编写xpath语法,与上述所对
'/html/head/meta[11]/@content' #下文会进行讲述
D、使用lxml库的etree类来使用xpath
注意,在使用xpath前必须使用etree.HTML()对文本进行初处理,实例:
def bili_get_img(text):
"""
这里定义一个名为bili_get_img的函数,用来解析图片链接,即反馈为链接
同时要求传入一个文本,即bili函数反馈的网页源码
"""
text = str(text)
reap_xpath = etree.HTML(text) #初处理,并赋值给reap_xpath
一、etree.HTML()与etree.parse()的区别
| 方法 | 适用于 |
|---|---|
| etree.HTML() | requests库所获取的内容,即非本地文件 |
| etree.parse() | 处理本地xml、html等文件,即本地支持文件 |
二、xpath基础语法(注意,返回的是列表形式[list])
| 符号 | 意思 |
|---|---|
| / | 选取此节点的所有子节点。即一层一层选择 |
| // | 从根节点选取。即所有选择 |
| @ | 选取有指定class的元素 |
代码实例:
def bili_get_img(text):
"""
这里定义一个名为bili_get_img的函数,用来解析图片链接,即反馈为链接
同时要求传入一个文本,即bili函数反馈的网页源码
"""
text = str(text)
reap_xpath = etree.HTML(text) #初处理,并赋值给reap_xpath
img_url = reap_xpath.xpath('/html/head/meta[11]/@content') #xpath语法,传入的是字符串,并将结果赋值给img_url
print(img_url) #打印结果
结果>>> ['http://i0.hdslb.com/bfs/archive/e47632eba6c7d838ec999a9d74306c1225094465.jpg']
转为字符串(加[0],有基础都知道)
def bili_get_img(text):
"""
这里定义一个名为bili_get_img的函数,用来解析图片链接,即反馈为链接
同时要求传入一个文本,即bili函数反馈的网页源码
"""
text = str(text)
reap_xpath = etree.HTML(text) #初处理,并赋值给reap_xpath
img_url = reap_xpath.xpath('/html/head/meta[11]/@content')[0] #xpath语法,传入的是字符串,必将结果赋值给img_url
print(img_url) #打印结果
结果>>> http://i0.hdslb.com/bfs/archive/e47632eba6c7d838ec999a9d74306c1225094465.jpg
E、实现保存与批量爬取
随便写一个with…open就可以实现保存,这算是基础就不讲了,给个代码实例:
def download_img(url,path):
"""
定义下载函数
url参数:前面解析出的图片链接
path:让用户输入的保存路径
"""
url = str(url)
path = str(str(path) + str(url).split('/')[-1]) #避免因为链接中\\影响保存路径来引发报错
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
} #这里必须是字典格式(键值对形式)
file_img = requests.get(url=url,headers=headers) #这里使用头文件保证安全
with open(path,'wb') as file:
file.write(file_img.content)
file.close()
print('图片保存完毕')
批量爬取无非就是for…in循环
if __name__ == '__main__':
path = input('请输入保存路径')
with open('url_list.txt','r') as e_list:
list_url = e_list.read() #可以让用户把想要的视频封面所对的视频链接放在这个文件
for url in list_url:
url = url
get_web = bili(url) #调用前面编写的源码获取函数来获取源码
url_img = bili_get_img(get_web) #调用解析源码函数来获取图片链接
download_img(url_img, path) #保存图片
加一点细节处理
if __name__ == '__main__':
path = input('请输入保存路径:')
try:
with open('url_list.txt', 'r') as e_list:
list_url = e_list.read() # 可以让用户把想要的视频封面所对的视频链接放在这个文件
except FileNotFoundError:
#如果没有文件,则说明是头次运行,为保证正常使用可以加个try...except
with open('url_list.txt','w+') as file:
file.write(',,')
print('错误!现已创建一个名为url_list的文本文件,文件内容写入方式为:链接与链接之间请用英文逗号隔开!如:wwww.111.com,www.222.com')
exit()
for url in list_url.split(','):
url = url
if str(url) == '':
print('错误,文本中没有链接,或者有空余的链接位置!') #防止因为传入空信息而报错
else:
get_web = bili(url) # 调用前面编写的源码获取函数来获取源码
url_img = bili_get_img(get_web) # 调用解析源码函数来获取图片链接
download_img(url_img, path) # 保存图片
print('所有下载完成')
F、运行演示与最终代码
运行演示:
最终代码:
# -*- coding: utf-8 -*-
#名称:bilibili封面批量下载
#作者:漫游感知
#CSDN:https://blog.csdn.net/qq_45429426?spm=1001.2014.3001.5343
import requests #发送请求与接收响应数据
from lxml import etree #这里调用lxml中的etree类型为使用xpath铺垫
def bili(url):
"""
这里定义一个名为“bili”的函数,并要求传入一个数值----url
这个函数用于获取视频页面源码
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
} #这里必须是字典格式(键值对形式)
url = str(url) #将传入信息转为字符串(保险)
resp = requests.get(url=url,headers=headers) #发送get请求,并使用自带头信息来进行反反爬
html_text = resp.text #将获取信息转为文本
if resp.status_code == 200: #如果状态码为200(请求成功)则返回网页数据
return html_text
else:
print('Get error')
def bili_get_img(text):
"""
这里定义一个名为bili_get_img的函数,用来解析图片链接,即反馈为链接
同时要求传入一个文本,即bili函数反馈的网页源码
"""
text = str(text)
reap_xpath = etree.HTML(text) #初处理,并赋值给reap_xpath
img_url = reap_xpath.xpath('/html/head/meta[11]/@content')[0] #xpath语法,传入的是字符串,必将结果赋值给img_url
print(img_url) #打印结果
return img_url
def download_img(url,path):
"""
定义下载函数
url参数:前面解析出的图片链接
path:让用户输入的保存路径
"""
url = str(url)
path = str(str(path) + str(url).split('/')[-1]) #避免因为链接中\\影响保存路径来引发报错
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
} #这里必须是字典格式(键值对形式)
file_img = requests.get(url=url,headers=headers) #这里使用头文件保证安全
with open(path,'wb') as file:
file.write(file_img.content)
file.close()
print('图片保存完毕')
if __name__ == '__main__':
path = input('请输入保存路径:')
try:
with open('url_list.txt', 'r') as e_list:
list_url = e_list.read() # 可以让用户把想要的视频封面所对的视频链接放在这个文件
except FileNotFoundError:
with open('url_list.txt','w+') as file:
file.write(',,')
print('错误!现已创建一个名为url_list的文本文件,文件内容写入方式为:链接与链接之间请用英文逗号隔开!如:wwww.111.com,www.222.com')
input('请重新运行程序!按任意键退出本次运行')
for url in list_url.split(','):
url = url
if str(url) == '':
print('错误,文本中没有链接,或者有空余的链接位置!') #防止因为传入空信息而报错
else:
get_web = bili(url) # 调用前面编写的源码获取函数来获取源码
url_img = bili_get_img(get_web) # 调用解析源码函数来获取图片链接
download_img(url_img, path) # 保存图片
print('所有下载完成')
- 程序流程图:

PS:你还可以加入判断是否为B站视频链接等其他功能
5、处理爬取文本乱码和反爬reapones.content.decode()/headers
PS:这里找一个会出现乱码问题及有反爬机制的网站,下面是所找的网站链接:
https://www.qidian.com/
- 我们先来触发一下反爬:
import requests
url = 'https://www.qidian.com/'
resp = requests.get(url=url) #直接向网站方式请求
print(resp.text)
结果>>>
g_data.staticPath = '//qidian.gtimg.com/qd';</script><script data-ignore="true" id="LBFnode" src="//qidian.gtimg.com/lbf/1.1.0/LBF.js?max_age=31536000"></script><script>// LBF é
ç½®
LBF.config({
"paths":{
"site":"//qidian.gtimg.com/qd/js","qd":"//qidian.gtimg.com/qd","common":"//qidian.gtimg.com/common/1.0.0"},"vars":{
"theme":"//qidian.gtimg.com/qd/css"},"combo":true,"debug":false});
LBF.use(['lib.jQuery'], function ($) {
window.$ = $;
});</script><script>LBF.use(['monitor.SpeedReport', 'qd/js/component/login.a4de6.js', 'qd/js/index/index.3fe03.js' ], function (SpeedReport, Login, Index) {
// 页é¢é€»è¾‘å
¥å£
if(Login){
Login.init().always(function(){
Index && typeof Index === 'function' && new Index();
})
}
if(219 && 219 != ''){
$(window).on('load.speedReport', function () {
// speedTimer[onload]
speedTimer.push(new Date().getTime());
var f1 = 7718, // china reading limited's ID
f2 = 219, // site ID
f3 = 4; // page ID
// chrome & IE9 Performance API
SpeedReport.reportPerformance({
flag1: f1,
flag2: f2,
flag3IE: f3,
flag3Chrome: f3,
。。。。。。。。省略。。。。。。。。。。
- 接着我们再对比一下网站真正的源码
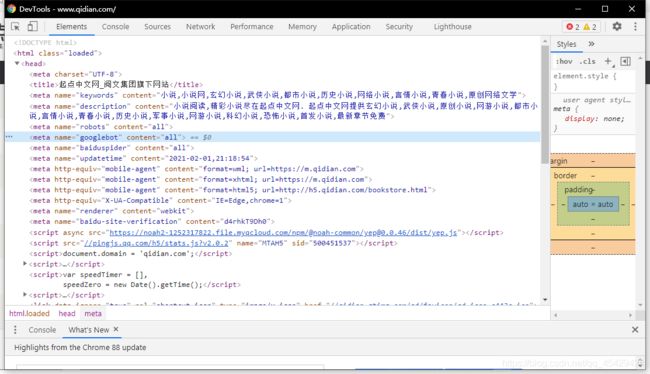
啊这,很明显不一样,从前几行上看就不一样
-
引出问题:
用浏览器访问发现网站是正常的,这说明不是网站的问题,而是我们的请求有问题,被拒绝连接了。
这时,我们应有疑惑,为什么我们的请求会被拒绝?为什么浏览器就可以正常请求呢? -
分析:
– 1.被拒绝,说明网站有反爬机制,我们携带的请求信息被网站视为爬虫了,即我们的伪装不到位
– 2.那我们请求时都带什么数据去请求了?即我们的请求头是什么?
– 3.既然我们的请求头不行,那为什么浏览器发送的请求头可以?即浏览器的请求头是什么?
– 4.如果我们用浏览器的请求头去请求网站是不是也可以请求成功了?即使用浏览器的请求头
一通分析下来,目标就很明确了
目标:把自己的头信息全部改为浏览器的头信息
- 首先我们要查看请求头信息,看我们请求时带的是什么玩意
怎么查看呢?
使用如下指令查看:
import requests
url = 'https://www.qidian.com/'
resp = requests.get(url=url)
# print(resp.text)
print(resp.requests.headers) #查看请求时使用的头信息
结果>>>
{
'User-Agent': 'python-requests/2.25.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
看到反馈值中的一个字样,我们就应该明白了
这个字样就是“python”
好家伙,上来就自报家门,大声告诉服务器:“我是个爬虫,想要爬取信息”,这不拒绝你拒绝谁啊?!
- 好了,我们中的问题就是出在我们的请求头上了,那我们接下来应该要开始改它的请求头了,可怎么改?改成什么样子呢?
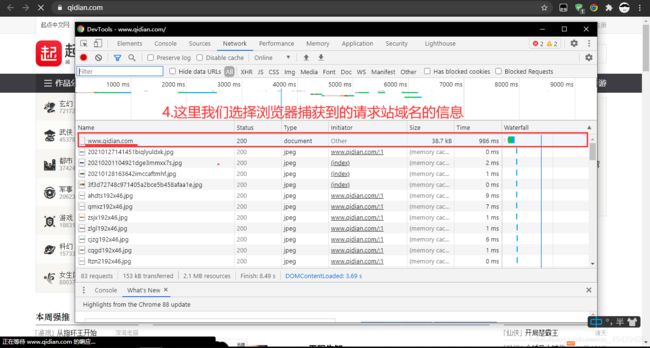
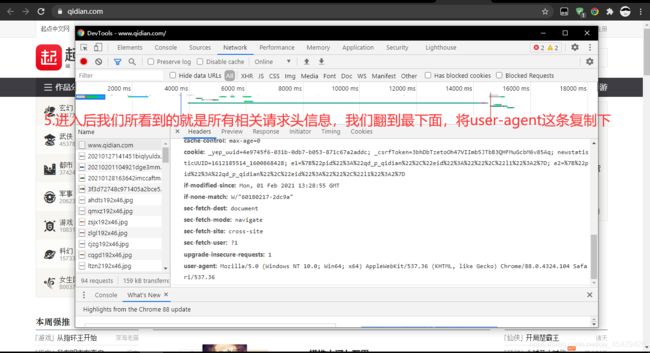
在我们修改前,我们先学会如何使用浏览器的调试工具来获取浏览器头信息
-
请根据下列图片中提示来(这里使用的Google浏览器)
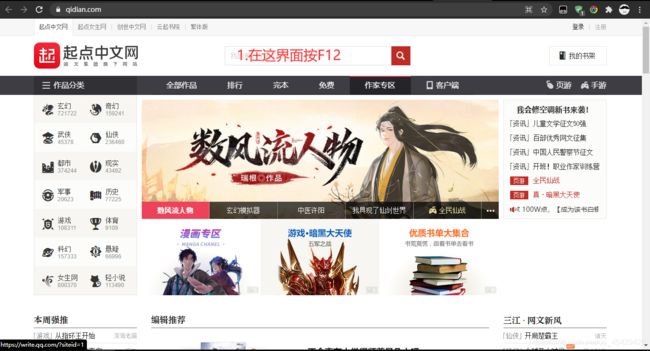
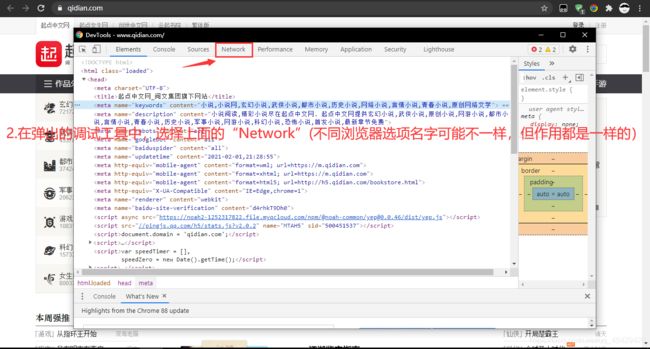
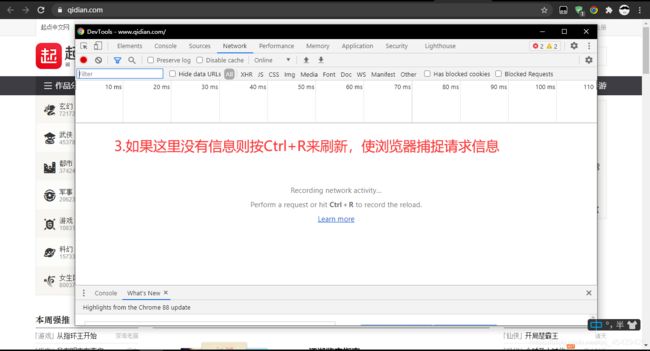
-
复制后,我们来到我们的编译器,创建个字典,并将刚才复制的信息以键值对形式粘贴到字典中
-
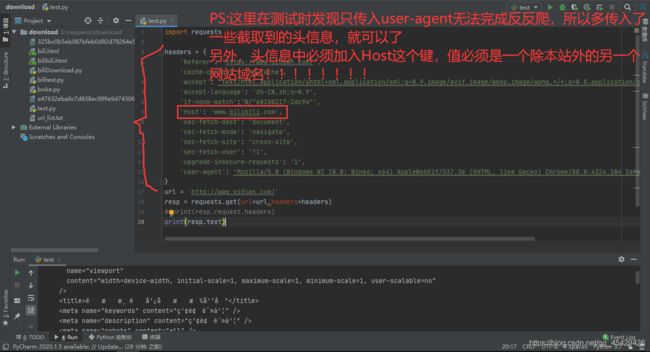
并在requests.get()中加入一个参数,完成我们的修改头信息
实例代码如下:
请务必看图片中的红字部分!!!!
- 随后我们再次请求,看一下反馈的网页源码
结果>>>
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no"
/>
<title>é˜
æ–‡æ¸ é“广告投放平å°</title>
<meta name="keywords" content="红袖读书" />
<meta name="description" content="红袖读书" />
<meta name="robots" content="all" />
<meta name="googlebot" content="all" />
<meta name="baiduspider" content="all" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="renderer" content="webkit" />
<meta name="publicPath" content />
<script>
(function (i, s, o, g, r, a, m) {
i["QDAnalyticsObject"] = r;
(i[r] =
i[r] ||
function () {
(i[r].q = i[r].q || []).push(arguments);
}),
(i[r].l = 1 * new Date());
(a = s.createElement(o)), (m = s.getElementsByTagName(o)[0]);
a.async = 1;
a.src = g;
m.parentNode.insertBefore(a, m);
})(
window,
document,
"script",
"https://noah2-1252317822.file.myqcloud.com/npm/@noah-common/yep@latest/dist/yep.js",
"yep"
);
yep("set", {
rate: 0.8, appid: 10042 });
</script>
<link rel="stylesheet" href="/static/css/ad40750e846edc80a8ac.css" />
<script>
window.routerBase = "/";
</script>
<script>
//! umi version: 3.2.22
</script>
</head>
<body>
<div id="root">
<div
style="
position: absolute;
top: 50%;
left: 0;
width: 100%;
text-align: center;
margin-top: -0.5em;
line-height: 1em;
"
>
资æºåŠ è½½...
</div>
</div>
<script src="/static/js/da8a876a19ad89802b15.js"></script>
</body>
</html>
》》》结束
Process finished with exit code 0
这时,我们获取的源码才是网站真正的网页代码,反反爬成功!但通过观察,可以发现获取的网页源码存在乱码问题,那么,接下来我们就来看看如何解决乱码问题吧↓↓↓↓
为什么会出现乱码情况?
分析:
- 编码格式不同导致的乱码。
每一种编码格式都不同,如果没有使用正确的编码格式进行编译就会出现乱码或者错误。其道理就如同你拿着自家房间钥匙去开他人房间,互不照应,自然就无法正常进门
解决方法:
- 对网站进行分析,获取网站对应编码格式(这里已Google浏览器为例)
1、在对应网站界面空白处右键,选择“查看网页源代码”(或在对应界面按Ctrl+U,不同浏览器可能会有些许差异)
2.找取编码信息(基本每个网站都不同,但编码格式信息一般会在前几行中声明)

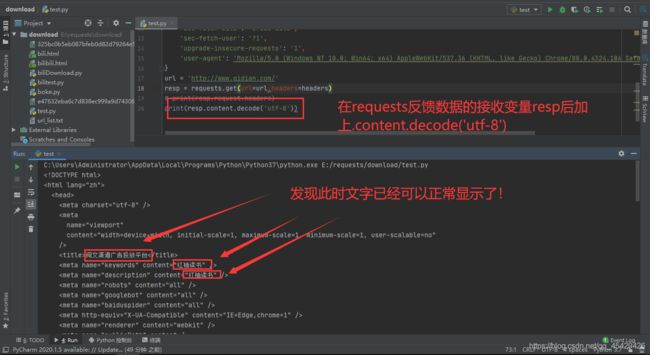
知道编码格式为UTF-8后,那么接下来我们就指定编译格式为UTF-8
实例代码:
完整爬取代码:
import requests
headers = {
'Referer': 'https://www.qidian.com/',
'cache-control': 'no-cache',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9',
'if-none-match':'W/"60180217-2dc9a"',
'Host': 'www.bilibili.com',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'cross-site',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
url = 'http://www.qidian.com/'
resp = requests.get(url=url,headers=headers)
# print(resp.request.headers)
print(resp.content.decode('utf-8'))
文章中所述技术可以运用在任何相似问题网站上!
下一篇内容大体预告:
批量爬取小说网站的小说并保存为TXT文件
END
PS:文中表情包来自网络