AI人工智能(调包侠)速成之路八(RNN循环神经网络 Recurrent Neural Networks)
未来的程序员必定需要掌握调用神经网路模型实现人工智能功能的能力,(调包侠)一定是未来程序员的必经之路。好在新工具平台的不断出现,功能调用越来越向API方向发展,补上相关知识继续上路吧。
RNN循环神经网络与时空序列数据
RNN全称循环神经网络(Recurrent Neural Networks),是用来处理时空序列数据的。语言、文章、股票走势这些都是常见的序列信号,我们交谈的时候要听懂一句话的内容,首先要依次听懂和记住前面每个单词,然后把后续听到的单词内容综合到前面的信息里面去,最后才能理解整个句子的内容。例如:“经过调查伊拉克政府没有大规模杀伤性武器,非也......”。一个句子中前后单词并不是独立的先后顺序也不能打乱。RNN循环神经网路就是专门处理这类时空序列数据的。
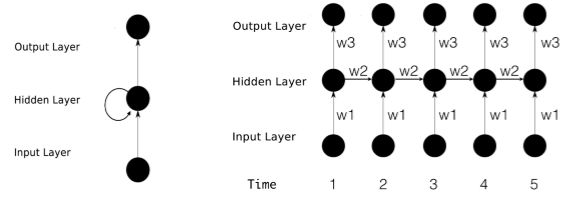
时空序列数据的表示与转换 Sequence Embedding
时空数据常见的是表格的形式表示例如:股票历史数据中的最低价、最高价、开盘价、收盘价、交易量、交易额、跌涨幅等。
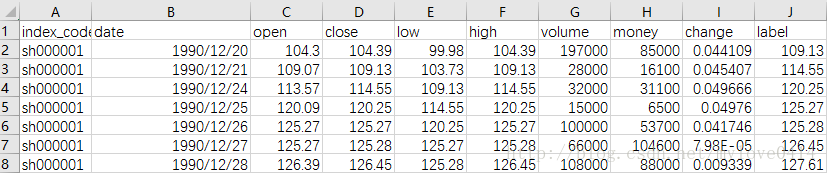
语言信息数字采样

声音的波形数字采样也可以直接计算和处理, 比较困难的是非数值类型的信号,例如自然语言和文字的数字化表示。好在这些基础的问题现在的工具都已经内部集成了解决方案。只需要设置下参数就可以使用了。
from tensorflow.keras import layers
self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)实战LSTM:情感分类问题
LSTM全称长短期记忆人工神经网络(Long-Short Term Memory),是对RNN循环神经网络的经典实现和解决方案。训练集我们使用的是 IMDB 数据集。这个数据集包含 25000 条电影评论数据,其中 12500 条正向数据,12500 条负向数据。要实现的目标是让神经网络能读懂评论信息,自动分辨出好评和差评。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
batchsz = 128
total_words = 10000 # 最大词汇量
max_review_len = 80 # 最长句子单词数(短的句子后面补齐长度,长的句子超过80个单词截断丢弃)
embedding_len = 100 # 转换后的变量维度
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)上面的代码加载数据集分成训练和测试数据。下面先定义循环神经网络模型。
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# transform text to embedding representation
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
self.rnn = keras.Sequential([
layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(units, dropout=0.5, unroll=True)
])
# fc, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# x: [b, 80, 100] => [b, 64]
x = self.rnn(x,training=training)
# out: [b, 64] => [b, 1]
x = self.outlayer(x)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob定义的神经网络用了容器keras.Sequential,里面是两层LSTM,第一层需要return_sequences=True参数,dropout是一个模型优化方法。并且调用layers.Embedding功能将单词编码成了100维的变量。
下面就可以将转换后的变量用来训练神经网络模型了。
if __name__ == '__main__':
units = 64
epochs = 4
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
循环神经网络的发展:时空序列预测
循环神经能从历史信息里面提取出规律并对后续的数据给出预测,于是网上出现了大量使用LSTM模型预测股票走势,预测彩票结果的文章。如果真能实现这种效果那学习人工智能真是花多大的代价都值得了,巴菲特、西蒙斯什么老古董都入土吧!如果价格的变化走势能用一个公式表达出来,那么用循环神经网络肯定是能拟合预测出未来走势,问题转换成了“价格的变化走势能否用一个公式表达出来?”很明显答案是否定的。
近年来流行的行为金融学给出了一些定性的非理性认知偏差(过度自信、盲信权威、从众效应、盲信喜好)。用神经网络去定量研究特定情形下,特定时间段的非理性行为或许是个不错的方向。成功难以复制,失败或可避免。
用ST-LSTM预测学习的循环神经网络 PredRNN
论文下载: http://ise.thss.tsinghua.edu.cn/~mlong/doc/predrnn-nips17.pdf
Casual LSTM和GHU解决时空预测学习中的深度困境 PredRNN++
论文下载地址:http://proceedings.mlr.press/v80/wang18b/wang18b.pdf
当前理论发展迅速,工具明显跟不上进度了。(调包侠)只能等待最新的集成工具出来。