集合基础知识
Java 集合框架
一、集合
如果你有很多数据需要存储,可以使用数组来存储,但数组的长度不可变,这点比较难受。数组,在初始化的时候就被指定了数组长度,且不可变。如果想要存储数量会发生变化的数据,就没办法了。
集合,可以保存数量不确定的数据,更吸引人的是,集合能保存具有映射关系的数据。集合中只能保存对象(对象的引用变量),而数组元素可以是基本数据类型的值,也可以是对象(对象的引用变量)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MEnwFFne-1607863873349)(%E9%9B%86%E5%90%88.assets/1569571780253.png)]
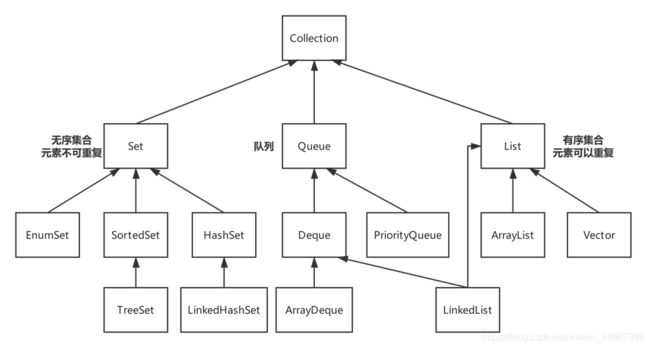
集合类,主要由两个接口派生而来:Collection 和 Map
1.1 Collection 集合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zSi8skbt-1607863873352)(%E9%9B%86%E5%90%88.assets/2243690-9cd9c896e0d512ed.gif)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-po71QUDe-1607863873361)(%E9%9B%86%E5%90%88.assets/1569567641403.png)]
1)Collection 接口派生的子接口:Set 和 List 接口
2)Java 提供的队列实现:Queue(类似 List)
重点掌握:HashSet、LinkedHashSet、TreeSet、ArrayDeque、ArrayList、LinkedList
1.2 Map 集合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uDTZ6vkV-1607863873362)(%E9%9B%86%E5%90%88.assets/1569567996051.png)]
Map 实现类,用于保存具有映射关系的数据,也就是 key-value 对,但 key 不会重复,一般需要通过 key 来找到对应的 value 值。
重点掌握:HashMap、TreeMap、LinkedHashMap
1.3 Set 集合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bWq4RnlK-1607863873364)(%E9%9B%86%E5%90%88.assets/1569568504618.png)]
Set 集合,元素无序号,且元素不能重复。
1.4 List 集合
List 集合,与数组非常相似,不仅可以通过索引记住元素顺序,长度还可变。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2CzpHBQl-1607863873366)(%E9%9B%86%E5%90%88.assets/1569568720714.png)]
1.5 学习重点
初级,我们只需要掌握 HashSet、ArrayList、ArrayDeque、LinkedList、HashMap 等实现类即可。
拓展,我们可以掌握 TreeSet、TreeMap 等实现类。
二、Collection 和 Iterator 接口
2.0 常用方法
Collection 主要是 List、Set 和 Queue 接口的父接口,所以它的方法都可以在这三个子接口中进行调用。
这些常用的方法,都可以通过开发者 API 文档中找到,非常多但不建议死记硬背,无非就是添加对象、删除对象、清空集合、判断集合是否为空等几个经典动作。建议,初学阶段要多去了解每个方法的作用,才能更好地知道都有哪些功能将来能用到实际开发中。
add(Object obj):在集合中,添加一个元素
addAll(Collection c):把集合 c 中的所有元素添加到指定的集合中。
clear():清除集合中所有元素。
contains(Object obj):常用于判断集合中是否包含指定元素。
containsAll(Collection c):常用于判断某集合中是否包含指定的 c 集合中的所有元素。
isEmpty():判断集合是否为空。
iterator():获取一个 Iterator 迭代器对象,用来遍历集合里的元素。
remove(Object obj):删除指定元素。
removeAll(Collection c):在某集合中删除指定 c 集合中包含的所有元素。
retainAll():在某集合中删除指定 c 集合中不包含的所有元素。
size():获取集合中元素的个数。length() 获取长度
toArray():把集合转成一个数组,集合元素会变成数组元素。
【案例1:Conllection 的使用】
这里主要演示 List、Set 集合的创建和常用方法操作,具体如下。
public class CollectionTest
{
public static void main(String[] args) {
//--------- 定义 List 集合 ---------
ArrayList list = new ArrayList();
// 1. 添加元素
list.add("翠花");
list.add("大宝");
System.out.println("list 集合的长度为:" + list.size());
// 2. 删除指定元素
list.remove("翠花");
System.out.println("list 集合的长度为:" + list.size());
// 3. 判断是否包含指定字符串
System.out.println("包含【翠花】吗?:" + list.contains("翠花"));
list.add("开课吧 Java");
System.out.println("list 集合的元素:" + list);
System.out.println("---------------------");
//--------- 定义 Set 集合 ---------
HashSet books = new HashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("翠花");
books.add("大宝");
System.out.println("list 中包含 books 集合?" + list.containsAll(books));
// 1. 用 list 集合减去 books 集合里的元素
list.removeAll(books);
System.out.println("list 集合的元素:" + list);
// 2. 删除 list 集合里所有元素
list.clear();
System.out.println("list 集合的元素:" + list);
// 3. 控制 books 集合里只剩下 list 集合里也包含的元素
books.retainAll(list);
System.out.println("books 集合的元素:" + books);
}
}
2.1 使用 Iterator 遍历集合元素
Iterator 主要用来遍历 Conllection 集合中的元素,也叫迭代器。它只能用于遍历集合,不能用来存放对象。
常用方法如下:
hasNext():判断集合中还有没有元素,如果有则返回 true。
next():取出集合中的下一个元素。
remove():移除上面 next() 方法中读取的元素。
public class IteratorTest
{
public static void main(String[] args) {
HashSet books = new HashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
// 通过 iterator() 方法,获取 books 集合对应的迭代器
Iterator it = books.iterator();
// 通过 hasNext() 方法进行迭代
while (it.hasNext()) {
// it.next()方法,返回的数据类型是 Object 类型,因此需要强制类型转换
String book = (String) it.next();
System.out.println(book);
// 通过 remove() 方法删除指定的元素
if (book.equals("怀孕一天一页")) {
it.remove();
}
// 对 book 变量赋值,不会改变集合元素本身
// Iterator 并不会把集合元素本身交给迭代变量,而是把集合元素的值交给了迭代变量
// 所以在修改迭代变量的值之后对集合远古三本身并没有任何覆盖。
book = "abc";
}
System.out.println(books);
}
}
如果,在使用 Iterator 迭代过程中进行修改集合元素,则会引发异常: java.util.ConcurrentModificationException
public class IteratorErrorTest
{
public static void main(String[] args) {
HashSet books = new HashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
Iterator it = books.iterator();
while (it.hasNext()) {
String book = (String) it.next();
System.out.println(book);
if (book.equals("怀孕一天一页")) {
// 使用Iterator迭代过程中,不可修改集合元素,下面代码引发异常
// java.util.ConcurrentModificationException
books.remove(book);
}
}
}
}
还好本质上,是因为 Iterator 迭代器使用了 fail-fast 机制(快速失败机制),在迭代过程中一旦发现有其他线程来修改该集合,则马上报 ConcurrentModificationException 异常,这样做可以避免共享资源而埋下其他隐患问题。
2.2使用 foreach 循环遍历集合元素
foreach 循环,是我们最常用的一种遍历方式。另外,foreach 循环中迭代变量也不是集合元素本身,其实也是把每个集合元素的值赋给了迭代变量。
public class ForeachTest
{
public static void main(String[] args) {
HashSet books = new HashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
// 所有的数据都在 books 中
// 循环遍历出来的每一个都赋值给 obj 变量保存着
for (Object obj : books) {
// 此处的 book 变量也不是集合元素本身
String book = (String) obj;
System.out.println(book);
if (book.equals("怀孕一天一页")) {
// 下面代码会引发ConcurrentModificationException异常
books.remove(book);
}
}
System.out.println(books);
}
}
2.3 使用 Predicate 操作集合(了解)
Predicate 翻译过来,叫“谓语”,主要用来描述主语的,做了件什么事儿。编程中,一般会使用 predicate 来指定某些条件。
JDK 8 中新增了 removeIf(Predicate filter) 方法,用来批量删除符合 ==filter 条件(过滤条件)==的所有元素。又因为 Predicate 属于函数式接口,所以能用 Lambda 表达式作为参数。
使用 Predicate 的主要目的,是为了简化集合的运算,减少执行循环的次数。
public class PredicateTest
{
public static void main(String[] args) {
HashSet books = new HashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
books.add("范志红详解孕产妇饮食营养全书");
books.add("协和怀孕大百科");
// 使用 Lambda 表达式(目标类型是 Predicate)过滤集合
books.removeIf(ele -> ((String) ele).length() < 10);
System.out.println(books);
}
}
public class PredicateTest2
{
public static void main(String[] args) {
HashSet books = new HashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
books.add("范志红详解孕产妇饮食营养全书");
books.add("协和怀孕大百科");
// 统计书名包含“孕”子串的图书数量
System.out.println(calAll(books, ele -> ((String) ele).contains("孕")));
// 统计书名字符串长度大于10的图书数量
System.out.println(calAll(books, ele -> ((String) ele).length() > 10));
}
// 定义一个 calAll() 方法来根据指定条件来处理指定的集合元素
// 然后实现了一个统计的功能,统计次数在 total 中
// 主要使用了 predicate 的 test() 方法
public static int calAll(Collection books, Predicate p) {
int total = 0;
for (Object obj : books) {
// 使用 Predicate 的 test() 方法,判断该对象是否满足 Predicate 指定的条件
if (p.test(obj)) {
total++;
}
}
return total;
}
}
三、Set 集合
Set 集合,元素是无序的,而且不能有重复的。
重点掌握 HashSet 实现类的使用。
3.1 HashSet 类(重点)
HashSet 的特点:
1)添加的元素是无序的。
2)HashSet 不是同步的,如果多个线程同时访问一个 HashSet,比如在修改时,一定要手动通过代码来保证同步,也就是保证安全。
3)集合元素值可以是 null。
往 HashSet 集合中添加一个元素的时候,默认调用 hashCode() 方法得到该对象的 hashCode 值,用于决定该对象在 HashSet 中存放的位置。
如果两个元素,通过 equals() 方法比较返回 true,但 hashCode() 返回的值不一样,说明两个元素是不一样的,则允许添加。
所以,HashSet 集合判断两个元素是否相等,就是通过 equals() 方法比较,还有 hashCode 值也一起比较。将来,如果有需要自定义一些判断方法,则可以模仿这里的操作方式。
// 类 A 的 equals 方法总是返回 true,但没有重写其 hashCode()方法
class A{
public boolean equals(Object obj){
return true;
}
}
// 类 B 的 hashCode() 方法总是返回 1,但没有重写其equals()方法
class B{
public int hashCode(){
return 1;
}
}
// 类C的hashCode()方法总是返回2,且重写其equals()方法总是返回true
class C{
public int hashCode(){
return 2;
}
public boolean equals(Object obj){
return true;
}
}
public class HashSetTest{
public static void main(String[] args){
HashSet books = new HashSet();
// 分别向books集合中添加两个A对象,两个B对象,两个C对象
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
}
}
当你想把一个对象放入 HashSet 中时,如果需要重写该对象对应类的 equals() 方法,则也应该重写它的 hashCode() 方法。只不过,需要注意的是,如果两个对象通过 equals() 方法得到 true,那么它们的 hashCode 值也应该相同。
如果说 equals() 方法得到 true,而 hashCode 值不一致,这就导致 Set 集合原有的规则冲突了。因为 equals 为 true 的时候,也就是元素相同的,但 hashCode 值不一样,也就是存储的位置可以是不同的,位置不同就意味着有一个空位可以保存这个元素,这就违反了 Set 集合中不能包含重复元素的原则。
如果说 hashCode 值一样,但 equals() 方法返回 false,更惨!hashCode 值一样,HashSet 就会让它们保存在同一个位置,这就会导致覆盖掉,只剩一个。怎么办呢?其实这里会采用“链式”结构来保存多个对象,但咱们的 HashSet 访问集合元素的时候采用的是 hashCode 值来快速定位的,访问的时候发现两个元素的 hashCode 值都一样,就会造成性能下降。
重写 hashCode() 方法时:
1)在程序执行的时候,同一个对象多次调用 hashCode() 方法时,一定要返回相同的值。
2)两个对象调用了 equals() 方法都返回 true 的时候,它们的 hashCode 值也应该返回是一样的。
3)对象中用作 equals() 方法比较实例变量,都应该用于计算 hashCode 值。
重写 hashCode() 的步骤:
1)将对象内的实例变量计算出一个 int 类型的 hashCode 值。
2)然后将多个 hashCode 值组合计算出一个 hashCode 值返回。
♥ 为了避免直接相加产生偶然相等,可以通过给实例变量的 hashCode 值乘上一个质数后再相加。
// R 类重写了 equals() 和 hashCode() 方法
class R {
int count;
public R(int count) {
this.count = count;
}
public String toString() {
return "R[count:" + count + "]";
}
// 重写 equals() 方法
public boolean equals(Object obj) {
if (this == obj){
return true;
}
if (obj != null && obj.getClass() == R.class) {
R r = (R) obj;
return this.count == r.count;
}
return false;
}
// 重写 hashCode() 方法
public int hashCode() {
return this.count;
}
}
public class HashSetTest2 {
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add(new R(55));
hs.add(new R(-3));
hs.add(new R(99));
hs.add(new R(-2));
// 打印HashSet集合,集合元素没有重复
System.out.println(hs);
// 取出第一个元素
Iterator it = hs.iterator();
R first = (R) it.next();
// 为第一个元素的count实例变量赋值
// 此处会导致与以有的元素一样
first.count = -3;
// 再次输出HashSet集合,集合元素有重复元素
System.out.println(hs);
// 删除 count 为 9 的 R 对象
hs.remove(new R(-3));
// 可以看到被删除了一个 R 元素
// 这里删掉其实是会删掉第二个位置上的 -3
// 因为第一个位置的 -3 是存储在原来 -2 的位置上
// 在删除的时候,其实对比了 hashCode 值,找到了对应位置
System.out.println(hs);
System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-3)));
System.out.println("hs是否包含count为-2的R对象?" + hs.contains(new R(-2)));
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u1HBunau-1607863873367)(%E9%9B%86%E5%90%88.assets/1570620199665.png)]
3.2 LinkedHashSet 类(重点)
LinkedHashSet 从名字上看,跟“链式”有关,它也是根据元素的 hashCode 值来决定元素的存储位置,但还多使用链表来维护元素的顺序。
访问它的时候,会根据元素的添加顺序来访问集合中的元素,有个好处,访问时的性能会很好。
但,就因为是链式的结构,在插入数据的时候,性能略差于 HashSet,插入元素时不建议使用。
public class LinkedHashSetTest
{
public static void main(String[] args) {
LinkedHashSet books = new LinkedHashSet();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
System.out.println(books);
// 删除 怀孕一天一页
books.remove("怀孕一天一页");
// 重新添加 怀孕一天一页
books.add("怀孕一天一页");
System.out.println(books);
}
}
3.3 TreeSet 类
有个强悍的特点,它可以进行排序,因为 TreeSet 是 SortedSet 接口的实现类。
TreeSet 可保证元素处于排序的状态,所以 TreeSet 采用的是红黑树的数据结构来存储集合元素的。
排序规则有:自然排序(默认)和定制排序。
public class TreeSetTest
{
public static void main(String[] args) {
TreeSet nums = new TreeSet();
// 向 TreeSet 中添加对象
nums.add(5);
nums.add(2);
nums.add(10);
nums.add(-9);
// 输出集合元素,看到集合元素已经处于排序状态
// 并没有按添加的先后顺序进行排列
System.out.println(nums);
// 输出集合里的第一个元素
System.out.println(nums.first()); // 输出-9
// 输出集合里的最后一个元素
System.out.println(nums.last()); // 输出10
// 返回小于4的子集,不包含4
System.out.println(nums.headSet(4)); // 输出[-9, 2]
// 返回大于5的子集,如果Set中包含5,子集中还包含5
System.out.println(nums.tailSet(5)); // 输出 [5, 10]
// 返回大于等于-3,小于4的子集。
// -3 < x < 4
System.out.println(nums.subSet(-3, 4)); // 输出[2]
}
}
1. 自然排序
TreeSet 会调用 compareTo(Object obj) 方法来比较元素之间的大小关系,按升序进行排列。
此方法属于 Comparable 接口,将返回一个整数值,实现该接口的类就可以用返回值来比较大小了。
Comparable 接口,主要提供了比较大小的标准,有些将来会碰到的常用类:BigDecimal、BigInteger、Character、Boolean、String 、Date、Time 等。
class Err {
}
public class TreeSetErrorTest
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet();
// 向TreeSet集合中添加Err对象
// 自然排序时,Err 没实现 Comparable 接口将会引发错误
// java.lang.ClassCastException
ts.add(new Err());
}
}
实现 compareTo() 方法时,都需要将被比较的对象强制类型转换为一样的,否则两个实例不能比较大小。
public class TreeSetErrorTest2
{
public static void main(String[] args) {
TreeSet ts = new TreeSet();
// 向 TreeSet 集合中添加两个对象
// 不同类型的元素,依然报 java.lang.ClassCastException
ts.add(new String("西尔斯怀孕百科"));
ts.add(new Date());
}
}
当 TreeSet 添加元素时,会调用 compareTo() 方法先去比较大小和根据红黑树去查找位置,如果通过 compareTo() 方法比较相等,就不能再添加了。
class Z implements Comparable {
int age;
public Z(int age) {
this.age = age;
}
// 重写equals()方法,总是返回true
public boolean equals(Object obj) {
return true;
}
// 重写了compareTo(Object obj)方法,总是返回1
public int compareTo(Object obj) {
return 1;
}
}
public class TreeSetTest2 {
public static void main(String[] args) {
TreeSet set = new TreeSet();
Z z1 = new Z(6);
set.add(z1);
// 第二次添加同一个对象,输出true,表明添加成功
System.out.println(set.add(z1));
// 下面输出set集合,将看到有两个元素
System.out.println(set);
// 修改set集合的第一个元素的age变量
((Z) (set.first())).age = 9;
// 输出set集合的最后一个元素的age变量,将看到也变成了9
System.out.println(((Z) (set.last())).age);
}
}
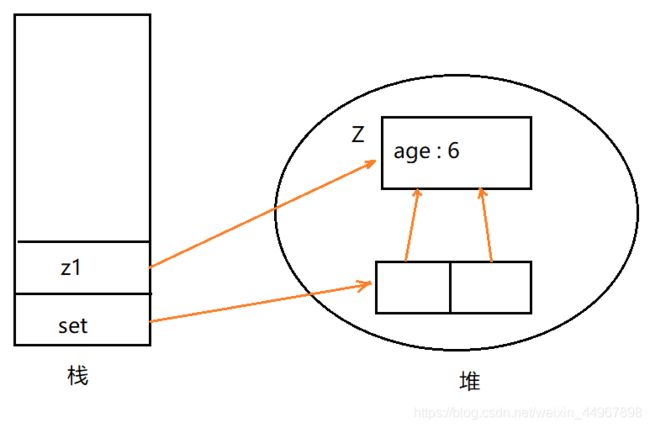
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q7yq6i6P-1607863873368)(%E9%9B%86%E5%90%88.assets/1570622266865.png)]
集合中的元素,保存的总是对象的引用,这里引用的是同一个对象。
所以,第一个 age 变了之后,最后一个 age 的值也跟着变了。
所以,当需要添加一个元素到 TreeSet 中,重写 equals() 方法时,也要保证该方法与 compareTo() 方法有一致的结果。注意到,如果两个对象通过 equals() 方法比较后返回 true,那么它们 compareTo() 方法比较后应该返回 0。
如果 compareTo() 返回 0,而 equals() 返回 false ,则会有麻烦。因为 compareTo() 比较相等后,就不会再让第二个元素添加进去了。
当我们往 TreeSet 中添加一个可变对象,后面又去修改可变对象的实例变量,会造成它与其他对象的大小发生改变,不过 TreeSet 不会去调整它们的顺序,则会导致 compareTo() 返回 0,具体看代码:
class RR implements Comparable {
int count;
public RR(int count) {
this.count = count;
}
public String toString() {
return "RR[count:" + count + "]";
}
// 重写 equals 方法,根据count来判断是否相等
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj != null && obj.getClass() == RR.class) {
RR RR = (RR) obj;
return RR.count == this.count;
}
return false;
}
// 重写compaRReTo方法,根据count来比较大小
public int compareTo(Object obj) {
RR RR = (RR) obj;
return count > RR.count ? 1 : count < RR.count ? -1 : 0;
}}
public class TreeSetTest3 {
public static void main(String[] aRRgs) {
TreeSet ts = new TreeSet();
ts.add(new RR(5));
ts.add(new RR(-3));
ts.add(new RR(9));
ts.add(new RR(-2));
// 打印TreeSet集合,集合元素是有序排列的
System.out.println(ts);
// 取出第一个元素
RR first = (RR) ts.first();
// 对第一个元素的count赋值
first.count = 20;
// 取出最后一个元素
RR last = (RR) ts.last();
// 对最后一个元素的count赋值,与第二个元素的count相同
last.count = -2;
System.out.println(ts);
// 删除失败
// 一旦改变了 TreeSet 集合中可变元素的实例变量,再去删是行不通的
System.out.println(ts.remove(new RR(-2)));
System.out.println(ts);
// 删除成功
// TreeSet 可以删除没有被修改实例变量、且不和其他被修改实例变量的对象重复的对象
System.out.println(ts.remove(new RR(5)));
System.out.println(ts);
}
}
2. 定制排序(拓展)
使用 compare(T obj1, T obj2) 方法,比较 obj1 和 obj2 的大小,返回正整数则 obj1 大于 obj2;如果返回 0,两者相等;如果返回负数,则 obj1 小于 obj2。
如果需要实现定制排序,则需要在创建 TreeSet 集合对象时,提供一个 Comparator 对象与该 TreeSet 集合关联,由此对象负责集合元素的排序逻辑。因为它是一个函数式接口,可以使用 Lambda 表达式来替代 Comparator 对象。
class M {
int age;
public M(int age) {
this.age = age;
}
public String toString() {
return "M [age:" + age + "]";
}
}
public class TreeSetTest4 {
public static void main(String[] args) {
// 此处 Lambda 表达式的目标类型是 Comparator
TreeSet ts = new TreeSet((o1, o2) -> {
// 此处,将两个变量直接强转
M m1 = (M) o1;
M m2 = (M) o2;
// 根据M对象的age属性来决定大小,age越大,M对象反而越小
return m1.age > m2.age ? -1 : m1.age < m2.age ? 1 : 0;
});
ts.add(new M(5));
ts.add(new M(-3));
ts.add(new M(9));
System.out.println(ts);
}
}
3.4 EnumSet 类(了解)
EnumSet 中的元素都必须是指定枚举类型的枚举值,EnumSet 以枚举值定义顺序来决定集合元素的具体顺序。
EnumSet 内部主要以位向量的形式存储,特点是非常紧凑、高效、占用内存小、运行效率很好,所以执行速度非常快,特别适合批量操作。
EnumSet 不能添加 null,否则会报空指针异常。
EnumSet 需要使用类方法来创建对象实例。
// 枚举类 相当是一个菜单,简单罗列一些值
enum Season {
SPRING, SUMMER, FALL, WINTER
}
public class EnumSetTest {
public static void main(String[] args) {
// 创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值
// allof() 方法其实是获取所有的元素
EnumSet es1 = EnumSet.allOf(Season.class);
// 输出[SPRING, SUMMER, FALL, WINTER]
System.out.println(es1);
// 创建一个EnumSet空集合,指定其集合元素是Season类的枚举值。
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println(es2); // 输出[]
// 手动添加两个元素
es2.add(Season.WINTER);
es2.add(Season.SPRING);
// 输出[SPRING, WINTER]
System.out.println(es2);
// 以指定枚举值创建EnumSet集合
EnumSet<Season> es3 = EnumSet.of(Season.SUMMER, Season.WINTER);
// 输出[SUMMER, WINTER]
System.out.println(es3);
EnumSet<Season> es4 = EnumSet.range(Season.SUMMER, Season.WINTER);
// 输出[SUMMER, FALL, WINTER]
System.out.println(es4);
// 新创建的EnumSet集合的元素和es4集合的元素有相同类型,
// es5的集合元素 + es4集合元素 = Season枚举类的全部枚举值
// 排除 es4 中已有的数据
EnumSet<Season> es5 = EnumSet.complementOf(es4);
// 输出[SPRING]
System.out.println(es5);
}
}
当复制 Collection 集合中的所有元素来创建新的 EnumSet 集合时,要求 Collection 集合中的所有元素必须是同一个枚举类的枚举值。
public class EnumSetTest2 {
public static void main(String[] args) {
HashSet c = new HashSet();
c.clear();
c.add(Season.FALL);
c.add(Season.SPRING);
// 复制Collection集合中所有元素来创建EnumSet集合
EnumSet enumSet = EnumSet.copyOf(c);
System.out.println(enumSet); // 输出[SPRING, FALL]
c.add("西尔斯怀孕百科");
c.add("睡前胎教故事");
// 下面代码出现异常:因为c集合里的元素不是全部都为枚举值
// java.lang.ClassCastException
enumSet = EnumSet.copyOf(c);
}
}
四、List 集合
4.1 List 和 ListIterator 接口
List 是一个元素有顺序、元素可重复的集合,集合中的每个元素都有对应的索引。
List 可以针对索引来操作集合的元素,比如插入、替换和删除集合元素。相关的方法都可以参考 API 文档。
public class ListTest{
public static void main(String[] args) {
ArrayList books = new ArrayList();
// 向books集合中添加三个元素
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
System.out.println(books);
// 将新字符串对象插入在第二个位置
books.add(1, new String("准爸爸必知99件事"));
for (int i = 0; i < books.size(); i++) {
System.out.println(books.get(i));
}
// 删除第三个元素
books.remove(2);
System.out.println(books);
// 判断指定元素在List集合中的位置:输出1,表明位于第二位
// 【注意1】这里有个细节,要特别注意,参考下面的分析
System.out.println(books.indexOf(new String("准爸爸必知99件事")));
// 将第二个元素替换成新的字符串对象
books.set(1, "睡前胎教故事");
System.out.println(books);
// 将books集合的第二个元素(包括)
// 到第三个元素(不包括)截取成子集合
System.out.println(books.subList(1, 2));
}
}
【注意1】这里通过调用 indexOf() 方法,返回新字符串对象在 List 集合中的位置,实际上 List 集合中并没有这个字符串对象,因为之前 List 添加字符串对象的时候,它是使用 new 关键字来创建的新字符串对象,然后这里再次使用 new 关键字创建新的字符串对象,所以很明显不是同一个对象。但 indexOf() 方法还是能返回 1。
那 List 判断两个对象相等的依据到底是什么呢?其实只要通过 equals() 方法比较返回 true 即可。佐证代码如下:
class AA {
public boolean equals(Object obj) {
return true;
}
}
public class ListTest2 {
public static void main(String[] args) {
ArrayList books = new ArrayList();
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
System.out.println(books);
// 删除集合中的 A 对象,将导致第一个元素被删除
books.remove(new AA());
System.out.println(books);
// 删除集合中的 A 对象,再次删除集合中的第一个元素
books.remove(new AA());
System.out.println(books);
}
}
调用 remove() 方法,想要从集合中删掉一个 AA 对象,List 对象就会调用这个对象的 equals() 方法挨个与集合元素来进行比较,如果该 equals() 方法以某个集合元素作为参数时返回 true,List 就会删掉该元素。
在这里 AA 类的 equals() 方法,总是返回 true,所以会删掉元素。
再看两个 JDK8 新增的方法:sort() 和 replaceAll()
sort() 方法:控制元素排序。排序的规则,字符串长度越大,字符串越长。
replaceAll() 方法:替换所有集合元素。替换规则,直接用集合元素(字符串)的长度作为新的集合元素。
public class ListTest3 {
public static void main(String[] args) {
ArrayList books = new ArrayList();
// 向books集合中添加4个元素
books.add("西尔斯怀孕百科");
books.add("睡前胎教故事");
books.add("怀孕一天一页");
books.add("准爸爸必知99件事");
// 使用目标类型为Comparator的Lambda表达式对List集合排序
books.sort((o1, o2) -> ((String) o1).length() - ((String) o2).length());
System.out.println(books);
// 使用目标类型为UnaryOperator的Lambda表达式来替换集合中所有元素
// 该Lambda表达式控制使用每个字符串的长度作为新的集合元素
books.replaceAll(ele -> ((String) ele).length());
System.out.println(books); // 输出[7, 8, 11, 16]
}
}
listIterator() 方法,将返回一个 ListIterator 对象,它增加了向前迭代的功能(Iteratro 只能向后迭代),还可以通过 add() 方法向 List 集合中添加元素(Iterator 只能删除元素)。
public class ListIteratorTest{
public static void main(String[] args) {
String[] books = {
"西尔斯怀孕百科", "睡前胎教故事", "怀孕一天一页"};
ArrayList bookList = new ArrayList();
for (int i = 0; i < books.length; i++) {
bookList.add(books[i]);
}
ListIterator lit = bookList.listIterator();
// 从前向后遍历
while (lit.hasNext()) {
System.out.println(lit.next());
lit.add("----------------");
}
System.out.println("======= 反向迭代 =======");
// 从后向前遍历
while (lit.hasPrevious()) {
System.out.println(lit.previous());
}
}
}
4.2 ArrayList 和 Vector 实现类
它们都是基于数组实现的 List 类,封装了一个动态的、允许再分配的 Object[] 数组,主要使用 initialCapacity 参数来设置该数组的长度,当添加的元素数量过多的话,则 initialCapacity 会自动增长,默认长度是 10。
有时候需要注意性能问题,如果向这两个集合中添加大量元素时,可用 ensureCapacity(int minCapacity) 方法一次性地增加 initialCapacity,这样可以减少重分配的次数,提高新能。
它们也可以使用 ensureCapacity(int minCapacity) 和 trimToSize() 方法来重新分配 Object[] 数组。
Vector 是一个比较老旧的集合,是 ArrayList 的前身,有很多缺点,不建议使用。
ArrayList 是线程不安全的,如果多个线程访问&修改了 ArrayList 集合,就需要手动保证集合的同步性。
Vector 是线程安全的,所以性能会比 ArrayList 稍低,哪怕是线程安全也不推荐使用。后面,我们可以用 Collections 工具类来讲 ArrayList 变成线程安全的。
4.3 长度不变的 List
Arrays 类的 asList(Object… a) 方法,可以把一个数组或指定个数的对象转成一个 List 集合,这个集合既不是 ArrayList 实现类的实例,也不是 Vector 实现类的实例,而是 Arrays 的内部类 ArrayList 的实例。
Arrays.ArrayList 是一个固定长度的 List 集合,只能访问元素,不能添加和删除集合中的元素。
public class FixedSizeList {
public static void main(String[] args) {
List<String> fixedList = Arrays.asList("西尔斯怀孕百科", "睡前胎教故事", "怀孕一天一页");
// 获取fixedList的实现类,将输出Arrays$ArrayList
System.out.println(fixedList.getClass());
// 使用方法引用遍历集合元素
fixedList.forEach(System.out::println);
// 试图增加、删除元素都会引发 UnsupportedOperationException 异常
fixedList.add("准爸爸必知99件事");
fixedList.remove("睡前胎教故事");
}
}
五、Queue 集合
Queue 用于模拟队列数据结构,主要是元素有“先进先出 FIFO”的特性。队列不允许随机访问队列中的元素。
Queue 接口有 PriorityQueue 实现类和 Deque 接口,其中 Deque 接口是一个“双端队列”,可以从两端添加、删除元素,所以 Deque 的实现类既可当成队列使用,也可以当成堆栈使用。
5.1 PriorityQueue 实现类
它主要是一个“比较标准”的队列实现类,而不是“完全标准”。它保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排列,一般使用 peek() 或者 poll() 方法取出元素的时候,取的是队列中最小的元素。
PriorityQueue 不允许插入 null 元素。
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue pq = new PriorityQueue();
// 下面代码依次向pq中加入四个元素
pq.offer(66);
pq.offer(-13);
pq.offer(26);
pq.offer(19);
// 输出pq队列,并不是按元素的加入顺序排列
System.out.println(pq);
// 访问队列第一个元素,其实就是队列中最小的元素:-13
System.out.println(pq.poll());
}
}
有时候,可能会看到队列中的元素并没有很好地按照大小进行排序,是因为受到了 PriorityQueue 的 toString() 方法的返回值的影响,可以多次调用它的 poll() 方法,就可以很明显看到元素按照从小到大的顺序一个一个“移出队列”了。
5.2 Deque 接口和 ArrayDeque 实现类
ArrayDeque 是一个基于数组实现的双端队列,创建 Deque 时同样可指定一个 numElements 参数,该参数用于指定 Object[] 数组的长度,如不指定,默认为 16。
ArrayDeque 当做“栈”来使用。
public class ArrayDequeStack
{
public static void main(String[] args) {
ArrayDeque stack = new ArrayDeque();
// 依次将三个元素 push 入"栈"
stack.push("准爸爸必知99件事");
stack.push("睡前胎教故事");
stack.push("协和怀孕大百科");
System.out.println(stack);
// 访问第一个元素,但并不将其pop出"栈",
System.out.println(stack.peek());
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack);
}
}
ArrayDeqye 当做“队列使用”
public class ArrayDequeQueue {
public static void main(String[] args) {
ArrayDeque queue = new ArrayDeque();
// 依次将三个元素加入队列
queue.offer("准爸爸必知99件事");
queue.offer("睡前胎教故事");
queue.offer("协和怀孕大百科");
System.out.println(queue);
System.out.println(queue.peek());
System.out.println(queue);
System.out.println(queue.poll());
System.out.println(queue);
}
}
ArrayDeque 不仅可以作为栈来用,也可以当做队列来用。
5.3 LinkedList 实现类
LinkedList 是一个功能十分强的集合类,可以根据索引来随机访问集合中的元素,可以当成双端队列来使用,因此可以被当做栈来用,也可以当成队列来使用。
LinkedList 与 ArrayList、ArrayDeque 的实现机制不同:
1)ArrayList、ArrayDeque 内部以数组的形式来保存集合中的元素,因此随机访问集合元素时有较好的性能。
2)LinkedList 内部以链表的形式来保存集合中的元素,因此随机访问集合元素时性能较差,但在插入、删除元素时性能比较出色。
后面的常用方式:先把某些数据,转成一个 list 集合,然后再转成一个 linkedList 集合,拆开操作完成之后,再组装回来。
public class LinkedListTest {
public static void main(String[] args) {
LinkedList books = new LinkedList();
// 将字符串元素加入队列的尾部
books.offer("准爸爸必知99件事");
// 将一个字符串元素加入栈的顶部
books.push("睡前胎教故事");
// 将字符串元素添加到队列的头部(相当于栈的顶部)
books.offerFirst("协和怀孕大百科");
// 以List的方式(按索引访问的方式)来遍历集合元素
for (int i = 0; i < books.size(); i++) {
System.out.println("遍历中:" + books.get(i));
}
// 访问、并不删除栈顶的元素
System.out.println(books.peekFirst());
// 访问、并不删除队列的最后一个元素
System.out.println(books.peekLast());
// 将栈顶的元素弹出“栈”
System.out.println(books.pop());
// 下面输出将看到队列中第一个元素被删除
System.out.println(books);
// 访问、并删除队列的最后一个元素
System.out.println(books.pollLast());
System.out.println(books);
}
}
六、Map 集合
Map 集合,也常被称为字典,因为它主要用于保存具有映射关系的数据,有 key,有 value,具体关系:key - value。所以 Map 中保存两组值,分别是 key 和 value,都可以保存任何引用类型的数据。
Map 中的 key 不能重复,要根据唯一的 key 找到对应的 value,集合中任何两个 key 使用 equals() 方法进行比较都会返回 false。
Map 与 Set 的关系:
如果把 Map 中所有的 key 放在一起来看,就是一个 Set 集合,因为元素不允许重复、没有顺序,Map 中的 key 刚好满足这个条件。
Map 中的 keySet() 方法可以返回一个 Set 集合,元素就是 Map 集合中所有的 key,此方法比较常用。
Map 的 key 集和 Set 集合中元素的存储形式非常相似,甚至名字都相似。
Set 集合中是单个元素,Map 集合中是 key-value 对,如果把 key-value 揉成一个整体来看的话,我们完全可以将 Map 集合当做 Set 集合来看,它们的关系是如此的微妙。
Map 提供了一个 Entry 内部类来封装 key-value 对,而计算 Entry 存储时只考虑 Entry 封装的 key。
Map 与 List 的关系:
如果把 Map 中所有的 value 放在一起,就是一个 List 集合,因为元素之间可以重复、有顺序、可以根据索引来查找。不过 Map 中不是通过整数值来当作索引的,而是另外一个对象作为索引。获取值,主要通过该元素的 key 索引。
常见方法,可见 API 文档。
Map 中的 Entry 内部类:
Entry 主要封装了 key-value 对,有三个常用的方法:
getKey()
getValue()
setValue(V value)
Map 的使用方式:
1)成对添加、删除 key-value 对
2)判断 Map 集合中是否包含指定 key,是否包含指定 value
3)通过 keySet() 方法获取所有的 key(其实就是一个 Set 集合),然后遍历集合。
6.1 Map 的使用
Map 所有的实现类,都重写了 toString() 方法,如果要查看具体内容,直接打印。
public class MapTest {
public static void main(String[] args) {
HashMap map = new HashMap();
// 成对放入多个key-value对
map.put("准爸爸必知99件事", 100);
map.put("睡前胎教故事", 99);
map.put("协和怀孕大百科", 77);
// 多次放入的key-value对中value可以重复
map.put("爸爸的声音:胎教诗词+胎教故事", 99);
// 放入重复的key时,新的value会覆盖原有的value
// 如果新的value覆盖了原有的value,该方法返回被覆盖的value
System.out.println(map.put("怀孕怎么吃 孕期营养与食谱全书", 99)); // 输出10
System.out.println(map); // 输出的Map集合包含4个key-value对
// 判断是否包含指定key
System.out.println("是否包含值为 协和怀孕大百科 的key:" + map.containsKey("协和怀孕大百科")); // 输出true
// 判断是否包含指定value
System.out.println("是否包含值为 99 的value:" + map.containsValue(99)); // 输出true
// 获取Map集合的所有key组成的集合,通过遍历key来实现遍历所有key-value对
for (Object key : map.keySet()) {
// map.get(key)方法获取指定key对应的value
System.out.println(key + "-->" + map.get(key));
}
map.remove("睡前胎教故事"); // 根据key来删除key-value对。
System.out.println(map);
}
}
public class MapTest2 {
public static void main(String[] args) {
HashMap map = new HashMap();
// 成对放入多个key-value对
map.put("准爸爸必知99件事", 100);
map.put("睡前胎教故事", 99);
map.put("协和怀孕大百科", 77);
// 尝试替换key为"怀孕怎么吃"的value,由于原Map中没有对应的key,
// 因此对Map没有改变,不会添加新的key-value对
map.replace("怀孕怎么吃", 66);
System.out.println(map);
// 使用原value与参数计算出来的结果覆盖原有的value
map.merge("七田真早教经典系列", 10, (oldVal, param) -> (Integer) oldVal + (Integer) param);
System.out.println(map);
// 当key为"Java"对应的value为null(或不存在时),使用计算的结果作为新value
map.computeIfAbsent("Java", key -> ((String) key).length());
System.out.println(map); // map中添加了 Java=4 这组key-value对
// 当key为"Java"对应的value存在时,使用计算的结果作为新value
map.computeIfPresent("Java", (key, value) -> (Integer) value * (Integer) value);
System.out.println(map); // map中 Java=4 变成 Java=16
}
}
6.2 HashMap 和 Hashtable 实现类
它们其实跟之前介绍的 ArrayList 和 Vector 是一样的概念,其实 Hashtable 是一个比较老的 Map 实现类,不建议使用了。
Hashtable 是一个线程安全的 Map 实现,但 HashMap 是线程不安全的实现,所以 HashMap 比 Hashtable 的性能会更好些;如果有多个线程访问同一个 Map 对象时,使用 Hashtable 会更好。
Hashtable 不能用 null 作为 key 和 value,会引发控制异常,但 HashMap 可以。
如果需要线程安全的 Map 实现类,不建议使用 Hashtable 了,可以用 Collections 工具类来处理即可。
为了在它们中存储、获取对象,用作 key 的对象必须实现 hashCode() 方法和 equals() 方法。
判断两个 key 是否相等:两个 key 通过 equals() 方法比较返回 true,两个 key 的 hashCode 值也相等。
Hashtable 判断两个 value 是否相等:只要两个对象通过 equals() 方法比较返回 true 即可。
class AAA {
int count;
public AAA(int count) {
this.count = count;
}
// 根据count的值来判断两个对象是否相等。
public boolean equals(Object obj) {
if (obj == this)
return true;
if (obj != null && obj.getClass() == AAA.class) {
AAA a = (AAA) obj;
return this.count == a.count;
}
return false;
}
// 根据count来计算hashCode值。
public int hashCode() {
return this.count;
}
}
class BB {
// 重写equals()方法,B对象与任何对象通过equals()方法比较都返回true
public boolean equals(Object obj) {
return true;
}
}
public class HashtableTest {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
ht.put(new AAA(60000), "西尔斯怀孕百科");
ht.put(new AAA(80000), "睡前胎教故事");
ht.put(new AAA(10000), new BB());
System.out.println(ht);
// 只要两个对象通过equals比较返回true,
// Hashtable就认为它们是相等的value。
// 由于Hashtable中有一个B对象,
// 它与任何对象通过equals比较都相等,所以下面输出true。
// 输出true
System.out.println(ht.containsValue("测试abc"));
// 只要两个A对象的count相等,它们通过equals比较返回true,且hashCode相等
// Hashtable即认为它们是相同的key,所以下面输出true。
// 输出true
System.out.println(ht.containsKey(new AAA(80000)));
// 下面语句可以删除最后一个key-value对
ht.remove(new AAA(10000));
System.out.println(ht);
}
}
6.3 LinkedHashMap 实现类
LinkedHashMap 也是用双向链表来维护 key-value 对的顺序,也就是 key 的顺序,该链表负责维护 Map 的迭代顺序,迭代顺序与 key-value 对的插入顺序保持一致。
LinkedList 因为需要维护元素的插入顺序,因此性能会比 HashMap 的稍低,但又因为它是链表结构来维护内部顺序,在迭代访问 Map 中全部元素时,性能较好。
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap scores = new LinkedHashMap();
scores.put("Java成绩", 80);
scores.put("PHP成绩", 82);
scores.put("Python成绩", 76);
// 调用forEach方法遍历scores里的所有key-value对
scores.forEach((key, value) -> System.out.println(key + "-->" + value));
}
}
6.4 使用 Properties 读写属性数据&文件
Properties 在处理属性文件时特别好用,项目开发中常用。
Properties 能把 Map 对象的 key-value 写入属性文件中,格式:属性名=属性值
public class PropertiesTest {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
// 向Properties中增加属性
props.setProperty("username", "Jss");
props.setProperty("password", "123456");
// 将Properties中的key-value对保存到a.ini文件中
props.store(new FileOutputStream("hello.properties"), "cuihua come on"); // ①
// 新建一个Properties对象
Properties props2 = new Properties();
// 向Properties中增加属性
props2.setProperty("gender", "male");
// 将a.ini文件中的key-value对追加到props2中
props2.load(new FileInputStream("hello.properties")); // ②
System.out.println(props2);
}
}
6.5 SortedMap 接口和 TreeMap 实现类
TreeMap 就是一个红黑树数据结构,每个 key-value 对就作为红黑树的一个节点。
TreeMap 存储 key-value 对(节点)时,需要根据 key 对节点进行排序,它能保证所有的 key-value 对处于有序状态。
TreeMap 有两种排序方式:自然排序和自定义排序。
自然排序:TreeMap 的所有 key 都应该实现 Comparable 接口。
自定义排序:
TreeMap 中判断两个 key 是否相等:两个 key 通过 compareTo() 方法返回 0,它就认为这两个 key 就是相等的。
class RRR implements Comparable {
int count;
public RRR(int count) {
this.count = count;
}
public String toString() {
return "RRR[count:" + count + "]";
}
// 根据count来判断两个对象是否相等。
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj != null && obj.getClass() == RRR.class) {
RRR r = (RRR) obj;
return r.count == this.count;
}
return false;
}
// 根据count属性值来判断两个对象的大小。
public int compareTo(Object obj) {
RRR r = (RRR) obj;
return count > r.count ? 1 : count < r.count ? -1 : 0;
}
}
public class TreeMapTest {
public static void main(String[] args) {
TreeMap tm = new TreeMap();
tm.put(new RRR(3), "西尔斯怀孕百科");
tm.put(new RRR(-5), "睡前胎教故事");
tm.put(new RRR(9), "怀孕一天一页");
System.out.println(tm);
// 返回该TreeMap的第一个Entry对象
System.out.println(tm.firstEntry());
// 返回该TreeMap的最后一个key值
System.out.println(tm.lastKey());
// 返回该TreeMap的比new R(2)大的最小key值。
System.out.println(tm.higherKey(new RRR(2)));
// 返回该TreeMap的比new R(2)小的最大的key-value对。
System.out.println(tm.lowerEntry(new RRR(2)));
// 返回该TreeMap的子TreeMap
System.out.println(tm.subMap(new RRR(-1), new RRR(4)));
}
}
6.6 WeakHashMap 实现类
它与 HashMap 用法几乎一样。
区别:HashMap 的 key 保留了对实际对象的强引用;WeakHashMap 的 key 只保留了对实际对象的弱引用。
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap whm = new WeakHashMap();
// 将WeakHashMap中添加三个key-value对,
// 三个key都是匿名字符串对象(没有其他引用)
whm.put(new String("Java"), new String("良好"));
whm.put(new String("Python"), new String("及格"));
whm.put(new String("PHP"), new String("中等"));
// 将 WeakHashMap中添加一个key-value对,
// 该key是一个系统缓存的字符串对象。
whm.put("iOS", new String("中等")); // ①
// 输出whm对象,将看到4个key-value对。
System.out.println(whm);
// 通知系统立即进行垃圾回收
System.gc();
System.runFinalization();
// 通常情况下,将只看到一个key-value对。
System.out.println(whm);
}
}
6.7 IdentityHashMap 实现类
实现机制与 HashMap 基本一致,它在处理两个 key 相等时比较特殊,在 IdentityHashMap 中,只有当两个 key 相等时(key1 == key2),才会认为两个 key 相等。
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap ihm = new IdentityHashMap();
// 下面两行代码将会向IdentityHashMap对象中添加两个key-value对
ihm.put(new String("语文"), 89);
ihm.put(new String("语文"), 78);
// 下面两行代码只会向IdentityHashMap对象中添加一个key-value对
// 如果没有通过 new String() 来初始化的字符串,其实都是在 字符串常量池的,可以通过 == 来比较,如果一样的话,则返回 true
ihm.put("java", 93);
ihm.put("java", 98);
System.out.println(ihm);
}
}
6.8 EnumMap 实现类
是一个与枚举类一起使用的 Map 实现,它所有的 key 都必须是单个枚举类的枚举值。创建 EnumMap 时,需要显示或隐式指定它对应的枚举类。
常见特征如下:
EnumMap 在内部采用数组的形式进行保存,非常紧凑、高效。
EnumMap 根据 key 的自然顺序来维护 key-value 对的顺序。
EnumMap 不允许采用 null 作为 key,但允许采用 null 作为 value。
创建 EnumMap 的时候,需要指定一个枚举类,才能将它们关联起来。
enum Season2
{
SPRING, SUMMER, FALL, WINTER
}
public class EnumMapTest
{
public static void main(String[] args)
{
// 创建EnumMap对象,该EnumMap的所有key都是Season枚举类的枚举值
EnumMap enumMap = new EnumMap(Season2.class);
enumMap.put(Season2.SUMMER, "夏日炎炎");
enumMap.put(Season2.SPRING, "春暖花开");
System.out.println(enumMap);
}
}