【新手专属】Python写一个爬取静态网站的爬虫第三期--去除广告(讲解)
前言:
这篇文章是以Python3.8.1为基础的 下 载链接:Python3.8.1
用的IDE是PyCharm2019.3.3 下载链接:PyCharm
用的库有BeautifulSoup4 和 requests
没有的可以先用这两行代码在Win+r中输入cmd的界面中下载
这是我第三个爬虫教程,如果没看过的可以从头开始看 链接:CSDN
pip install beautifulsoup4
pip install requests
转载请注明出处!侵权必究!
这一期我们来讲一讲如何去除爬到的图片会有广告的问题 (翻页爬取+去广告) 如果没看过我的翻页操作,链接: Blog
首先随便找一个网站
这里我还用那个网站 – 表情包网站:
http://www.17qq.com/bq-jinguanzhang.html
这里我们还是照顾一下新手小朋友,复习一下第一期的内容以免忘记:
首先,先打开开发者工具,按键盘F5(Lenovo用Fn+F5)或是鼠标右键点击检查(我依然推荐使用Google浏览器)
找到Network点击进去,并刷新一下
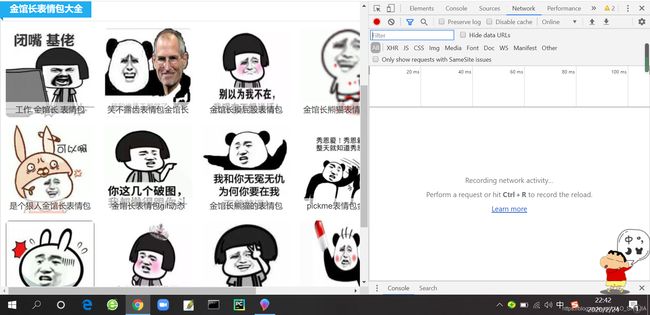
刷新后(Ctrl+R快捷键刷新或右上角手动刷新)
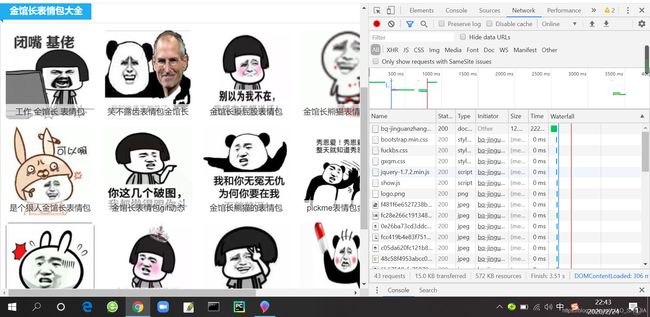
点开第一个文件,并点开Headers
这里边我们可以找到Requests Url(本网网址)、Starts Code(状态码)、UA(User-Agent用户代理码)和Cookies等等有用的信息
这些是爬取网站必备的信息
我们先找到UA先,将Header界面拉到最下边即可,并复制下来,这可以帮助我们不被网站管理员“反爬”
开始我们今天新内容:
今天我们来说一说如何去除爬下来的图片含义广告图片的问题,先上代码
# 引入库
import requests
from bs4 import BeautifulSoup
找到主网址,和规律网网址,这些上一期讲过了,先自己实践一下
# 主网址,用于补全图片链接
main_url = "http://www.17qq.com"
# 翻页网址,规律,以方便format方法填充用花括号进行弥补规律
page = "http://www.17qq.com/bq-jinguanzhang_{}.html"
找到自己的用户代理码,这个码每个人都是不同的,可以自己实践操作一下
# 利用开发者工具查找用户代理码
# 这是因人而异的
headers = {
"User-Agent": "自己的用户代理码"}
# 以简洁图片名字输出,初始图片为1,专为强迫症小朋友设计
count = 1 # 不要可以注释掉
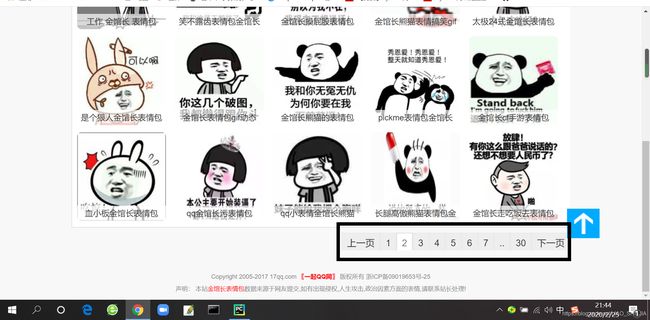
由这个图片可以看出,一共有30页,而第一页的规律不一致,所以我们用一个range(2, 31)来表示
利用一个for循环输出页码,存储到一个列表中
# 页码列表,以供format方法填充链接使用
pageNum = []
# 由上图看出,我们要循环30次,用range(2, 31)来表示
for i in range(2, 31):
# 将输出的i加入到页码列表中
pageNum.append(i)
利用format方法进行字符串格式化,将链接补全
如果不会format方法的话去这个网站看看,挺好的一个网站
链接:菜鸟教程
# 遍历页码列表,将列表内页码格式化
for item in pageNum:
# 将页面数字利用format方法进行填充Url
page_url = page.format(item)
# 用requests中的get方法请求,并生成一个response对象
response = requests.get(url=page_url, headers=headers)
# 用BeautifulSoup进行网页解析,生成一个soup对象
soup = BeautifulSoup(response.text, "html.parser") # 此处必须为response对象的text才能解析
现在呢,开始本期重要知识点
1.首先我们找一下表情包图片所在的div标签的class(有ID就看ID)
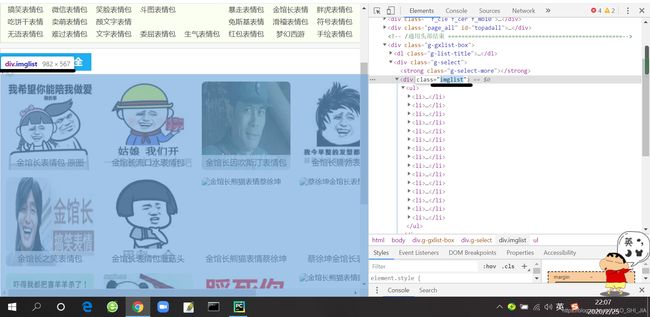
我们就来查找这个class的div标签,是一个叫imglist的
# 查找class是div的标签
div = soup.find("div", {
"class": "imglist"})
# 在这个标签下再次查找标签是img的对象
links = div.find_all_next("img") # 这里有些特殊,要记住
上面这串代码有点特殊,不是之前的find_all了,是find_all_next了,这我不做太多讲解,大家记住就好了
遍历links对象,查找src链接,并补全链接进行图片下载
# 遍历links对象,等到单一链接并进行字符串拼接,补全链接
for link in links:
Gif = main_url + link.get("src")
print(Gif)
现在就要将图片下载到一个文件夹(或者在本路径下)了
with open("./新建文件夹/{}.gif".format(count), "wb") as f_w: # 注意:图片是二进制的,要用wb才能写入
# 请求图片下载链接
gif = requests.get(url=Gif, headers=headers)
# 将图片写入(下载)到指定路径下
f_w.write(gif.content)
# 防止名字重复
count += 1
下面附上完整代码
"'
作者:廖世嘉
时间:2020/2/25 22:40发布
转载请注明出处!此文为本博主辛苦撰写的,侵权必究!
"'
# 引入库
import requests
from bs4 import BeautifulSoup
# 用于补全图片链接
main_url = "http://www.17qq.com"
# 每一页图片的Url的规律
url = "http://www.17qq.com/bq-jinguanzhang_{}.html"
# 利用开发者工具查找用户代理
# 这是因人而异的
headers = {
"User-Agent": "自己的用户代理码"}
count = 1
# 页码列表
pageNum = []
# 一共有30页,所以我们也要循环30次
for i in range(2, 31):
# 将页码加入到一个列表里
pageNum.append(i)
for item in pageNum:
# 将页面数字利用format方法进行填充Url
page_url = url.format(item)
# 用requests中的get方法请求,并生成一个response对象
response = requests.get(url=page_url, headers=headers)
# 用BeautifulSoup进行网页解析,生成一个soup对象
soup = BeautifulSoup(response.text, "html.parser") # 此处必须为response对象的text才能解析
# 查找id是imglist的div标签
div_tag = soup.find("div", {
"class": "imglist"})
# print(div_tag)
# 查找img标签
links = div_tag.find_all_next("img")
# 遍历links对象,得到单一的链接
for link in links:
# 由于一些因素,得到的链接不全,要与之前的main_url做一个字符串拼接
Gif = main_url + link.get("src") # 必须要做,不可去掉
print(Gif)
with open("./新建文件夹/{}.gif".format(count), "wb") as f_w:
gif = requests.get(url=Gif, headers=headers) # 重新请求链接
f_w.write(gif.content) # 将请求的链接写入(下载)到一个文件夹内
count += 1 # 防止图片名称重复