微信小程序知识点(上)
1.流式布局中flex-direction:属性要和display:flex搭配使用。
2.如果item过多,要是实现上下拖拽效果,容器选择scroll-view.
3.微信小程序获取input输入框的值
输入的内容:{
{first}}
输入的内容2:{
{second}}
searchBox:function(e){
const that = this;
let first,second;
that.setData({
first : e.detail.value.username,
second : e.detail.value.pwd
})
}
//这个函数一定要写在标签上才能用e.detail.value获取到4.如何在超链接添加下划线和删除线:
text-decoration:underline; //下划线
text-decoration:line-through;//删除线5.后台js函数中调用和设置data里面的数据
在调用data的变量时,要使用this.data.xxx,不要忘了这个data。
page({
data:{
test:'this is just test'
},
setup:function(e){
this.setData({//在函数中设置data中的值
test:'变化后的test值'
})
let test1 = this.data.test//获取data中的指定值
}
})6.如何获取到页面通过url传参传递过来的值
比如从A页面传参跳转到B页面。在B页面的onLoad(options)方法,从url路径中获取传递的参数值。
wx.navigateTo{
url:'../nextPage/nextPage?getid='+getid
}或者通过wxml的url直接传递参数
在页面B接收参数
onload:function(e){
var id = e.getid
}如果需要在页面之间传递对象,就需药在A页面中先使用 JSON.stringify(obj)对需要传递的对象数据进行转换, 然后在最后在B页面的onload方法里,使用JSON.parse(json) 转换为对象类型的数据。
Jump() {
var str= JSON.stringify(obj);
wx.navigateTo({
url: '/pages/list/list?str=' + str,
})
}
onload: function(option) {
var data = JSON.parse(option.str)
//现在data就是index.js中传过来的数据
}7.picker默认值设置
需求:
默认显示"请选择",当点击picker后弹出的才是这三个选项,请问这样该如何实现?
目前想到的是在range中添加第一项为“请选择”,但这样冗余数据会很多,因为有数个picker,请问这个需求该如何实现?小程序文档中picker已经查看。
解决办法:三目运算符
{
{typeIndex==null ? "请选择" : types[typeIndex]}}
Page({
data: {
types:["喜欢","一般","讨厌"],
typeIndex:null
},
typeChange(event){
this.setData({
typeIndex:event.detail.value
})
}
})8.如何通过checkbox选中状态控制组件的显示与隐藏
通过点击checkbox来切换后台show变量的值,从而控制模块是否进行显示。
添加投保家属
//后台js代码
page({
data:{
show:false,
},
isShow:founction(e){
var sh = this.data.show
this.setData({
show:!sh
})
}
})9.css样式优先级
| 选择器 |
权重值 |
|---|---|
| !important标识 |
10000 |
| 行内样式 |
1000 |
| id选择器 |
100 |
| 类选择器 |
10 |
| 标签选择器 |
1 |
| 通配符 * |
0 |
10.关于position的一些理解
absolute是针对他第一个父元素为相对或者绝对定位的位置来进行定位,如果没有,那么就会相对于body进行定位,如果下拉页面时那么该元素也会跟着页面下拉,而fixed是针对浏览器窗口进行定位,就是手机边框进行定位,下拉页面时不会跟随页面下拉,因此请尽量使用absolute值。
11.json值得范围
JSON的值只能是以下几种数据格式:
-
数字,包含浮点数和整数
-
字符串,需要包裹在双引号中
-
Bool值,true 或者 false
-
数组,需要包裹在方括号中 []
-
对象,需要包裹在大括号中 {}
-
Nul
另外需要注意的是,小程序的json配置是一种静态的配置文件,且无法在json配置文件中添加注释。
12.WXML一些注意事项
WXML 全称是 WeiXin Markup Language,
在动态绑定中,属性值可以动态的进行绑定,需要注意的是属性值,必须被双引号包裹,且变量名大小写敏感。动态bang通过 { { 变量名 }} 语法可以使得 WXML 拥有动态渲染的能力。
除此外还可以在 { { }} 内进行简单的逻辑运算。
hello world
hello world 所有wxml 标签都支持的属性称之为共同属性,如表2-1所示。
| 属性名 | 类型 | 描述 | 注解 |
|---|---|---|---|
| id | String | 组件的唯一标识 | 整个页面唯一 |
| class | String | 组件的样式类 | 在对应的 WXSS 中定义的样式类 |
| style | String | 组件的内联样式 | 可以动态设置的内联样式 |
| hidden | Boolean | 组件是否显示 | 所有组件默认显示 |
| data-* | Any | 自定义属性 | 组件上触发的事件时,会发送给事件处理函数 |
| bind*/catch* | EventHandler | 组件的事件 |
13.WXSS一些注意事项
表2-2 小程序WXSS支持的选择器
| 类型 | 选择器 | 样例 | 样例描述 |
|---|---|---|---|
| 类选择器 | .class | .intro | 选择所有拥有 class="intro" 的组件 |
| id选择器 | #id | #firstname | 选择拥有 id="firstname" 的组件 |
| 元素选择器 | element | view checkbox | 选择所有文档的 view 组件和所有的 checkbox 组件 |
| 伪元素选择器 | ::after | view::after | 在 view 组件后边插入内容 |
| 伪元素选择器 | ::before | view::before | 在 view 组件前边插入内容 |
WXSS优先级与CSS类似,权重如图2-13所示。
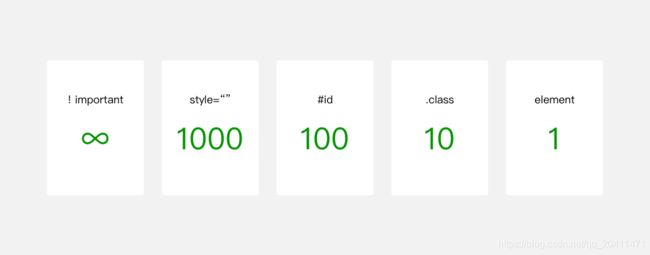
图2-13 WXSS选择器优先级
权重越高越优先。在优先级相同的情况下,后设置的样式优先级高于先设置的样式。
小程序的运行环境分成渲染层和逻辑层,第2章提到过 WXML 模板和 WXSS 样式工作在渲染层,JS 脚本工作在逻辑层。
14.在scroll-view中实现分页加载
在scroll-view中实现分页加载时,尤其是当页面底部有固定组件时会导致onReachBottom方法无法触发导致无法进行分页加载,这时候推荐使用scroll-view自己的滚动到底部触发的方法,bindscrolltolower,通过绑定该方法,实现scroll-view滚动到底部触发实现分页加载.
15.scroll-view组件使用的注意事项
如果想实现scroll-view的竖式滚动,需要设置scroll-y属性,且需要给scroll-view组件一个固定的height值,否则无法实现组件的滚动
16.组件内容垂直水平居中
通过在组件样式中添加下列代码,实现组件内的内容垂直/水平居中居中:
.list-item{
display: flex;
align-items:center;/*垂直居中*/
justify-content: center;/*水平居中*/
}17.wx:key的默认设置写法
{
{title}}
*this代表在 for 循环中的 item 本身,而{ {item}}的item是默认的,默认数组的当前项的下标变量名默认为 index,数组当前项的变量名默认为 item;使用 wx:for-item 可以指定数组当前元素的变量名,使用 wx:for-index 可以指定数组当前下标的变量名。
18.关于''和""以及特殊字符。
在实际应用中,总有一些具有特殊含义的字符无法直接输入,比如换行 \n、Tab键 \t、回车 \r、反斜杠 \\,这些我们称之为转义字符。JavaScript中单引号和双引号都表示字符串。如果字符串中存在双引号,建议最外层用单引号;如果字符串中存在单引号,建议最外层用双引号。如何在控制台给打印的字体添加颜色等,大家可以自行去研究。
19.关于变量和赋值。
JavaScript可以使用let语句声明变量,使用等号=可以给变量赋值,等号=左侧为变量名,右侧为给该变量赋的值,变量的值可以是任何数据类型。JavaScript常见的数据类型有:数值(Number)、字符串(String)、布尔值(Boolean)、对象(Object)、数组(array)、函数(Function)等。
在JS中,var用于声明全局变量,let用于声明局部变量,const用于声明常量,在使用时注意区分。
20.假性获取
并不是真的获取到了用户的信息,只是假性获取前台显示了一下,不用用户点击授权即可显示用户头像昵称等信息。
21.微信小程序通过JS动态修改页面标题setNavigationBarTitle
动态设置导航栏标题是一个非常简单的API,在技术文档里面可以了解到,只要给wx.setNavigationBarTitle()的title对象赋值,就能改变小程序页面的标题。
我们可以在页面生命周期函数onload里来调用API,例如在新页面动态设置标题:
onLoad: function (options) {
wx.setNavigationBarTitle({
title:"onLoad触发修改的标题"
})
},22.下拉小程序不出现空白
当我们下拉很多小程序的时候,都会出现一个白色的空白,很影响美观,但是如果我们在windows的配置项里把backgroundColor和navigationBarBackgroundColor的颜色配置成一样,下拉就不会有空白啦,比如:在app.json文件中添加
"window":{
"backgroundTextStyle":"light",
"navigationBarBackgroundColor": "#1772cb",
"navigationBarTitleText": "HackWork技术工坊",
"navigationBarTextStyle":"white",
"backgroundColor": "#1772cb"
},
23.wx:if
23.1.wx:if使用方法
在框架中,我们用wx:if="{ {condition}}"来判断是否需要渲染该代码块:
True 也可以用wx:elif和wx:else来添加一个else块:
1
2
3 因为wx:if是一个控制属性,需要将它添加到一个标签上。但是如果我们想一次性判断多个组件标签,我们可以使用一个wx:if控制属性。
view1
view2
注意:
23.2.wx:ifvs hidden
因为wx:if之中的模板也可能包含数据绑定,所以当wx:if的条件值切换时,框架有一个局部渲染的过程,因为它会确保条件块在切换时销毁或重新渲染。同时wx:if也是惰性的,如果在初始渲染条件为false,框架什么也不做,在条件第一次变成真的时候才开始局部渲染。
相比之下,hidden就简单的多,组件始终会被渲染,只是简单的控制显示与隐藏。一般来说,wx:if有更高的切换消耗而hidden有更高的初始渲染消耗。因此,如果需要频繁切换的情景下,用hidden更好,如果在运行时条件不大可能改变则wx:if较好。
24.如何在页面js里调用全局js的globalData
如何在其他界面调用app.js里面的数据
使用开发者工具新建一个user页面,然后在user.js的Page()函数前面添加如下代码:
let app = getApp()
console.log('user页面打印的app', app)
console.log('user页面打印的globalData', app.globalData.userInfo)
page({
globalData:{
userInfo:"123"
})25.关于用户登录后的用户信息存放地点
1.存放在app.js中的全局变量里面
2.使用在缓存里面
26.form表单基本结构
那我们如何才能让标题的内容可以根据用户提交的数据进行修改呢?这就涉及到表单的知识啦。小程序一个完整的数据表单收集通常包含:
-
form组件,
-
输入框或选择器组件(比如input组件)
-
button组件
使用开发者工具在form.wxml里输入以下代码:
数据表单涉及到的组件多(至少三个),参数以及参数的类型也比较多,上面有几个非常重要的点,大家可以结合上面的代码来理解:
- 表单最核心的在于表单组件form,输入框组件input和button组件要在内,form也会收集内部组件提交的数据;
- 绑定事件处理函数的不再是button,而是form,form的bindsubmit与button的 formType="submit"是一对,点击button,就会执行bindsubmit的事件处理函数;
- input是输入框,用户可以在里面添加信息;name是input组件的名称,与表单数据一起提交。
- 后台js文件获取form表单提交的组件值为e.detail.value.组件的name值
27.回调函数
那什么是回调函数呢?简单一点说就是:回调Callback是指在另一个函数执行完成之后被调用的函数。success、fail就都是在小程序的API函数执行完成之后,才会被调用,而success和fail它们本身也是函数,也能返回数据。而复杂一点说,就是回调函数本身就是函数,但是它们却被其他函数给调用,而调用函数的函数被称为高阶函数。这些大家只需要粗略了解就可以了。
28.异步与同步
我们前面也提及过异步,那什么会有异步呢?因为JavaScript是单线程的编程语言,就是从上到下、一行一行去执行代码,类似于排队一样一个个处理,第一个不处理完,就不会处理后面的。但是遇到网络请求、I/O操作(比如上面的读取图片信息)以及定时函数(后面会涉及)以及类似于成功反馈的情况,等这些不可预知时间的任务都执行完再处理后面的任务,肯定不行,于是就有了异步处理。
把要等待其他函数执行完之后,才能执行的函数(比如读取图片信息)放到回调函数里,先不处理,等图片上传成功之后再来处理,这就是异步。比如wx.showToast()消息提示框,可以放到回调函数里,当API调用成功之后再来显示提示消息。回调函数相当于是异步的一个解决方案。
29.模板
有这样一个应用场景,我们希望所有的页面都有一个相同的底部版权信息,如果是每个页面都重复写这个版权信息就会很繁琐,如果可以定义好代码片段,然后在不同的地方调用就方便了很多,这就是模板的作用。
29.1静态的页面片段
1.比如使用开发者工具在小程序的pages页面新建一个common文件夹,在common里新建一个foot.wxml,并输入以下代码
云开发技术训练营
2.在要引入的页面比如home.wxml的顶部,使用import引入这个模板,
3.然后在要显示的地方调用比如home.wmxl页面代码的最底部来调用这个模板。
29.2动态的页面片段
比如在页面的每一页都有一个相似的页面样式与结果,但是不同的页面有着不同的标题以及页面描述,用数据绑定就能很好的解决这个问题,不同的页面的js data里有不同的数据,而模板的wxml都是固定的框架。
1.比如使用开发者工具在小程序的pages页面新建一个common文件夹,在common里新建一个head.wxml,并输入以下代码:
{
{title}}
{
{desc}}
2.我们再给每个页面的js里的data里添加不同的title和desc信息,再来在页面先引入head.wxml,然后在指定的位置比如wxml代码的前面调用该模板。
我们注意创建模板时,使用的是,而调用模板时,使用的是,两者之间对应。
30.模块化与格式化
在新建模板小程序里(不使用云开发服务),有一个日志logs页面,这个日志logs虽然简单,但是包含着非常复杂的JavaScript知识,是一个非常好的学习参考案例,这里我们来对它进行一一解读。
模块化与引入模块
在实际开发中,日期、时间的处理经常会使用到,但是使用Date对象所获取到的时间格式与我们想要展现的形式是有非常大的差异的。这时我们可以把时间的处理抽离成为一个单独的 js 文件比如util.js(util是utility的缩写,表示程序集,通用程序等意思),作为一个模块。
把通用的模块放在util.js或者common.js,把util.js放在utils文件夹里等就跟把css放在style文件夹,把页面放在pages文件夹,把图片放在images文件夹里是一样的道理,尽管文件夹或文件的名称你可以任意修改,但是为了代码的可读性,文件结构的清晰,推荐大家采用这种一看就懂的方式。
30.1新建模块文件
使用开发者工具在小程序根目录新建一个utils文件夹,再在文件夹下新建util.js文件,在util.js里输入以下代码(也就是参考模板小程序的logs页面调用的util.js)
const formatTime = date => {
const year = date.getFullYear() //获取年
const month = date.getMonth() + 1 //获取月份,月份数值需加1
const day = date.getDate() //获取一月中的某一天
const hour = date.getHours() //获取小时
const minute = date.getMinutes() //获取分钟
const second = date.getSeconds() //获取秒
return [year, month, day].map(formatNumber).join('/') + ' ' + [hour, minute, second].map(formatNumber).join(':') //会单独来讲解这段代码的意思
}
const formatNumber = n => { //格式化数字
n = n.toString()
return n[1] ? n : '0' + n
}
module.exports = { //模块向外暴露的对象,使用require引用该模块时可以获取
formatTime: formatTime,
formatNumber: formatNumber
}
30.2引入模块文件
我们再来在file.js里调用这个模块文件util.js,也就是在file.js的Page()对象前面使用require引入util.js文件(需要引入模块文件相对于当前文件的相对路径,不支持绝对路径)
const util = require('../../utils/util.js')
30.3使用模块中的定义的函数
然后再在onLoad页面生命周期函数里打印看看这段时间处理的代码到底做了什么效果,这里也要注意调用模块里的函数的方式。
onLoad: function (options) {
console.log('未格式化的时间',new Date())
console.log('格式化后的时间',util.formatTime(new Date()))
console.log('格式化后的数值',util.formatNumber(9))
},
util.formatTime()就调用了模块里的函数,通过控制台打印的日志可以看到日期时间格式的不同,比如:
未格式化的时间 Mon Sep 02 2019 11:25:18 GMT+0800 (中国标准时间)
格式化后的时间 2019/09/02 11:25:18
显然格式化后的日期时间的展现形式更符合我们的日常习惯,而9这个数值被转化成了字符串”09″。那这段格式化日期时间的代码是怎么实现的呢?这里就涉及到高阶函数的知识,一般函数调用参数,而高阶函数会调用其他函数,也就是把其他函数作为参数。
相信格式化数字的代码比较好理解,如果是15日里的15,由于n[1]是15的第二位数字5,为true会直接return返回n,也就是15;比如9月里的数字9,n[1]不存在,也就是没有第二位数,于是执行 '0' + n给它加一个0,变成09;而formatNumber是一个箭头函数。
const formatNumber = n => { //格式化数字
n = n.toString() //将数值Number类型转为字符串类型,不然不能拼接
return n[1] ? n : '0' + n //三目运算符,如果字符串n第2位存在也就是为2位数,那么直接返回n;如果不存在就给n前面加0
}
而格式化日期时间则涉及到map,比如下面的这段代码就有map
return [year, month, day].map(formatNumber).join('/') + ' ' + [hour, minute, second].map(formatNumber).join(':')
map也是一个数据结构,它背后的知识非常复杂,但是我们只需了解它是做什么的就可以,如果你想对数组里面的每一个值进行函数操作并且返回一个新数组,那你可以使用map。
上面这段代码就是对数组[year, month, day]和[hour, minute, second]里面的每一个数值都进行格式化数字的操作,这一点我们可以在file.js的onLoad里打印看效果就明白了
onLoad: function (options) {
console.log('2019年9月2日map处理后的结果', [2019,9,2].map(util.formatNumber))
console.log('上午9点13分4秒map处理后的结果', [9, 13, 4].map(util.formatNumber))
},
从控制台打印的结果就可以看到数组里面的数字被格式化处理,有两位数的不处理,没有2位数的前面加0,而且返回的也是数组。至于数组Array的join方法,就是将数组元素拼接为字符串,以分隔符分割,上面[year, month, day]分隔符为”/”,[hour, minute, second]的分隔符为”:”。
30.4 module、exports、require
还有一些变量比如module,module.exports,exports等实际上是模块内部的局部变量,它们指向的对象根据模块的不同而有所不同,但是由于它们通用于所有模块,也可以当成全局变量:
- module对当前模块的引用,module.exports 用于指定一个模块所导出的内容,即可以通过 require() 访问的内容。
- require用于引入模块、JSON、或本地文件,可以从node_modules引入模块,可以使用相对路径引入本地模块,路径会根据 __dirname定义的目录名或当前工作目录进行处理。
- exports表示该模块运行时生成的导出对象。如果按确切的文件名没有找到模块,则 Nodejs会尝试带上.js、.json或.node拓展名再加载。
31.数据缓存strorage
logs页面还涉及到数据缓存Storage方面的知识。通过前面的学习,我们了解到点击事件生成的事件对象也好,使用数据表单提交的数据也好,还是上传的图片、文件也好,只要我们重新编译小程序,这些数据都会消失。前面我们也提到存储数据、文件的方式有三种,一是保存到本地手机、二就是缓存,三是上传到服务器(云开发会讲解),这里我们就来了解数据缓存方面的知识。
注意:尽管上传图片和上传文件都是把图片或文件先上传到临时文件里,但是保存图片wx.saveImageToPhotosAlbum()和保存文件wx.saveFile()是完全不同的概念,保存图片是把图片保存到手机本地相册;而保存文件则是把图片由临时文件移动到本地存储里,而本地存储每个小程序用户只有10M的空间。
在了解logs的数据缓存案例之前,我们先来看一个将上传的图片由临时文件保存到缓存的案例,使用开发者工具在file.wxml里输入以下代码:
临时文件的图片

缓存保存的图片

请选择文件
保存文件到缓存
然后在file.js的data里初始化临时文件的路径tempFilePath和本地缓存的路径savedFilePath:
data: {
tempFilePath: '',
savedFilePath: '',
},
再在file.js里添加事件处理函数chooseImage和saveImage(函数名有别于之前的chooseImg和saveImg,不要弄混了哦):
chooseImage:function() {
const that = this
wx.chooseImage({
count: 1,
success(res) {
that.setData({
tempFilePath: res.tempFilePaths[0]
})
}
})
},
saveImage:function() {
const that = this
wx.saveFile({
tempFilePath: this.data.tempFilePath,
success(res) {
that.setData({
savedFilePath: res.savedFilePath
})
wx.setStorageSync('savedFilePath', res.savedFilePath)
},
})
},
还没有完~我们还需要在file.js的onLoad生命周期函数里将缓存里存储的路径赋值给本地缓存的路径savedFilePath:
onLoad: function (options) {
this.setData({
savedFilePath: wx.getStorageSync('savedFilePath')
})
},
编译之后,点击请上传文件的button,会触发chooseImage事件处理函数,然后调用上传图片的API wx.chooseImage,这时会将图片上传到临时文件,并将取得的临时文件地址赋值给tempFilePath,有了tempFilePath,图片就能渲染出来了。
然后再点击保存文件到缓存的button,会触发saveImage事件处理函数,然后保存文件API wx.saveFile,将tempFilePath里的图片保存到缓存,并将取得的缓存地址赋值给savedFilePath(注意tempFilePath也就是临时路径是保存文件的必备参数),这时缓存保存的图片就渲染到页面了。然后会再来调用缓存API wx.setStorageSync(),将缓存文件的路径保存到缓存的key savedFilePath里面。有些参数名称相同但是含义不同,这个要注意。
通过wx.setStorageSync()保存到缓存里的数据,可以使用wx.getStorageSync()获取出来,我们在onLoad里把获取出来的缓存文件路径再赋值给savedFilePath。
编译页面,看看临时文件与缓存文件的不同,临时文件由于小程序的编译会被清除掉,而缓存文件有10M的空间,只要用户不刻意删除,它就会一直在。
缓存的好处非常多,比如用户的浏览文章、播放视频的进度(看了哪些文章,给个特别的样式,免得用户不知道看到哪里了)、用户的登录信息(用户登录一次,可以很长时间不用再登录)、自定义的模板样式(用户选择自己喜欢的样式,下次打开小程序还是一样)、最经常使用的小图片(保存在缓存,下次打开小程序速度更快)等等。
32.async/await的使用说明
async checkUser() {
const userData = await db.collection('clouddisk').get()
if(userData.data.length === 0){
return await db.collection('clouddisk').add({
data:{
"nickName": "",
"avatarUrl": "",
"albums": [ ],
"folders": [ ]
}
})
}else{
this.setData({
userData
})
}
},
async 是“异步”的简写,async 用于申明一个 function 是异步的,而 await 用于等待一个异步方法执行完成,await 只能出现在 async 函数中。await 在 async 函数中才会有效。假设一个业务需要分步完成,每个步骤都是异步的,而且依赖上一步的执行结果,甚至依赖之前每一步的结果,就可以使用Async Await来完成
小程序端现在完全支持async/await的写法,不过需要在开发者工具-详情-本地设置,勾选增强编译才行,否则会报以下错误。
Uncaught ReferenceError: regeneratorRuntime is not defined
async 函数返回值是 Promise 对象, async 函数内部 return 返回的值。会成为 then 方法回调函数的参数。如果 async 函数内部抛出异常,则会导致返回的 Promise 对象状态变为 reject 状态。抛出的错误而会被 catch 方法回调函数接收到。async 函数返回的 Promise 对象,必须等到内部所有的 await 命令的 Promise 对象执行完,才会发生状态改变。也就是说,只有当 async 函数内部的异步操作都执行完,才会执行 then 方法的回调。
在async函数中使用await,那么await这里的代码就会变成同步的了,意思就是说只有等await后面的Promise执行完成得到结果才会继续下去,await就是等待,这样虽然避免了异步,但是它也会阻塞代码,所以使用的时候要考虑周全。await会阻塞代码,每个await都必须等后面的fn()执行完成才会执行下一行代码。
33.promise对象是什么意思?

promise写法(promise.then.catch,注意promise不要与async/await混用):
function doIt() {
console.time("doIt");
const time1 = 300;
step1(time1)
.then(time2 => step2(time2))
.then(time3 => step3(time3))
.then(result => {
console.log(`result is ${result}`);
console.timeEnd("doIt");
});
}
doIt();
33.async/await
用法(对于async/await形式的异常,可以使用try/catch进行处理异常,捕捉异常,注意async/await写法不要与promise形式的写法混用):
async function request () {
try {
const result = await doSomething()
const newResult = await doSomethingElse(result)
const finalResult = await doThirdThing(newResult)
console.log('Got the final result: ' + finalResult)
} catch (error) {
failureCallback(error)
- 本方法使用async/await的方法进行,用于处理回调函数,可以使代码更整齐可读,解决回调地狱的问题。
- await 在 async 函数中才会有效。假设一个业务需要分步完成,每个步骤都是异步的,而且依赖上一步的执行结果,甚至依赖之前每一步的结果,就可以使用Async Await来完成
- 在async函数中使用await,那么await这里的代码就会变成同步的了,意思就是说只有等await后面的Promise执行完成得到结果才会继续下去,await就是等待,这样虽然避免了异步,但是它也会阻塞代码,所以使用的时候要考虑周全。await会阻塞代码,每个await都必须等后面的fn()执行完成才会执行下一行代码
- 对于处理async/await形式的异常,我们搭配try catch来使用,如果有很多需要捕捉的异常则都放在try块内,然后在catch中显示捕捉到的异常。
34.不可修改const定义的常量
const声明的常量无法再次修改,如果对const声明的量进行再次修改,会报data is read-only的错误。
35.openID简介
用户在小程序里有着独一无二的openid,相同的用户在不同的小程序openid也不同,相同的用户再公众号、小程序等里面的openid不同但是unionID相同,我们可以使用openID来区分用户。
- 使用云开发时,用户在小程序端上传文件到云存储,这个openid会被记录在文件信息里;
- 添加数据到数据库这个openid会被保存在
_openid的字段里;
- 我们还可以使用云函数的
Cloud.getWXContext()来获取用户的openid;
35.小程序目录结构
如果你的小程序项目之前没有使用云开发,或者你的小程序是在没有勾选云开发时创建的demo小程序,都可以通过以下改造来支持云开发。这个改造的过程并不会影响你原有的小程序的使用,无论是网络请求、页面逻辑还是数据传递,当然更不会影响到你原有的后端服务。
首先在小程序的根目录下新建两个文件夹,一个是cloudfunctions,用于存放本地的云函数以及云函数的依赖包;还有一个是miniprogram文件夹,把小程序除了project.config.json以外的其他文件,比如pages、utils、images、app.js、app.json等文件都放到miniprogram文件夹里,然后在project.config.json添加云函数文件夹的路径配置即可,
project // 你的小程序项目
├── cloudfunctions //云函数根目录
│ └── login //login云函数目录,可以通过右键云函数根目录来新建
├── miniprogram //你原有的小程序文件存放的目录
└── project.config.json
然后再在project.config.json添加miniprogramRoot配置:
"cloudfunctionRoot": "cloudfunctions/",
"miniprogramRoot":"miniprogram/",
使用云开发,可以让你更方便的使用云存储来存储用户产生的各类文件;用云函数以及云调用提供一些后端功能,你完全可以只使用云开发来做后端,也可以在自建服务器提供后端服务的情况下,让云开发作为后端功能的一个补充;云开发在用户登录鉴权方面也比自建服务器的登录系统要方便很多。

36.JSON语法
-
大括号 {}保存对象 ,我们来看一下app.json,哪些地方用到了大括号{},{}里面就是对象;
-
中括号 []保存数组 ,我们可以看到中括号[]里有“pages/index/index”等(这是小程序页面的路径),那这些页面路径就是数组啦;数组里的值都是平级的关系;
-
各个数据之间由 英文字符逗号, 隔开,注意这里的数据包括对象、数据、单条属性与值,大家可以结合app.json 仔细比对逗号,出现的位置 ,平级数据的最后一条数据不要加逗号,,也就是只有数据之间才有逗号。
-
字段名称(属性名)与值之间用**冒号:**隔开,字段名称在前,字段的取值在后;
-
字段名称用 双引号”” 给包着;
37.view里面的文字不换行解决办法
CSS添加style="white-space:pre-wrap",即可实现换行
38.showToast显示内容不全问题
wx.showToast的title内容多了导致显示不全,解决办法就是把icon:"none"。
wx.showToast({
icon: 'none',
title: '提交成功,感谢您的反馈。提交成功,感谢您的反馈!'
})
关键就在于icon: 'none' 这段代码,把icon: 'none'设置上就可以解决showToast字数限制不折行的问题了。
39.不同变量和true的比较结果
前面我们已经说过,值为非0的数字、非空字符串、非空数组等的时候,它们==true就是true,那它们的逻辑非就是false
40.禁止页面下拉
有的时候我们的页面做得比较短,为了增强用户体验,不希望用户可以下拉页面,因为下拉页面会有种页面松动的感觉,可以在该页面的json文件里配置,比如:
{ "window":
{ "disableScroll": true
}
}
注意,不是app.json文件,而是页面的json文件,为什么不是app.json文件而是页面的json文件呢?大家可以思考一下,小程序这么处理的逻辑(因为在app.json中定义会导致所有的页面都无法下拉)。
41.自定义顶部导航栏
官方默认的导航栏只能对背景颜色进行更改,对于想要在导航栏添加一些比较酷炫的效果则需要通过自定义导航栏实现。通过设置 app.json中页面配置的 navigationStyle(导航栏样式)配置项的值为 custom,即可实现自定义导航:
"window":{
"navigationStyle":"custom"
}
比如我们给小程序的页面配一个好看的壁纸,比如在home.wxss里添加以下样式:
page{
background-image: url(https://tcb-1251009918.cos.ap-guangzhou.myqcloud.com/background.jpg)
}
然后在手机上预览该页面,发现小程序固有的带有页面标题的顶部导航栏就被背景图片取代了。我们也还可以在顶部导航栏原有的位置上设计一些更加酷炫的元素,这些都是可以通过前面组件的知识来实现的。
42.承载网页容器web-view
承载网页的容器。会自动铺满整个小程序页面,个人类型的小程序暂不支持使用。web-view组件可打开关联的公众号的文章,这个对很多自媒体用户就比较友好了,公众号文章可以使用第三方的工具比如秀米、135编辑器等制作得非常精美,这些文章可以在小程序里打开啦。
web-view的也可以绑定备案好的域名,支持JSSDK的接口,因此很有小程序为了省开发成本,点击链接打开的都是网页,并没有做小程序的原生开发,这个就不再讨论范围之内了。
43.URL链接的特殊字符
在日常生活中,我们经常可以看到有的链接特别长,比如百度、京东、淘宝等搜索某个关键词的链接,下面是使用百度搜索云开发时的:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=云开发&rsv_pq=81ee270400007011&rsv_t=ed834wm24xdJRGRsfv7bxPKX%2FXGlLt6fqh%2BiB9x5g0EUQjyxdCDbTXHbSFE&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=20&rsv_sug1=19&rsv_sug7=100&rsv_sug2=0&inputT=5035&rsv_sug4=6227
这些链接通常包括以下特殊字符,以及都有着基本相同的含义,通过这些特殊字符,链接就被塞进了很多数据信息,其中?、&、=是我们接下来关注的重点。
/ 分隔目录和子目录? 分隔实际的URL和参数& URL中指定的参数间的分隔符= URL中指定的参数的值# 同一个页面的位置标识符,类似于页面的书签;
44.页面全局变量与data里面的变量对比
const user = {name:"李东bbsky",address:"深圳"}
console.log(user.address) //之前介绍过,这里可以访问user对象
Page({
data: {
title:"技术杂役"
},
onLoad: function(options) {
console.log(this.data.title)
console.log(user.name) //在生命周期函数里访问user对象
},
})
在前面我们已经介绍过,我们可以在Page({})对象前添加一些变量,比如我们声明了一个user变量,这个user变量可以在Page({})对象的生命周期函数里访问,因为user变量定义在了Page之外,它是整个页面的全局变量。但是Page里的data对象,就只能通过this.data来访问,不能在Page外面访问到。
45.声明变量的写法
值得一提的是在写JavaScript表达式的时候,我们要分清什么时候可以用=赋值(在page函数外定义全局变量、在page全局变量的方法体内比如onload函数内),啥时候需要用对象赋值,使用:(比如在data里面定义变量)
Page({
const school = "清华大学" //错误写法
data:{ //正确写法
},
onLoad: function(options) {
company:"腾讯" //错误写法
const company = "腾讯" //正确写法
},
})
46.回调函数与回调函数的写法
经过之前的学习,相信大家对回调函数success、fail有了一定的认识,那什么是回调函数呢?简单一点说就是:回调Callback是指在另一个函数执行完成之后被调用的函数。success、fail就都是在小程序的API函数执行完成之后,才会被调用,而success和fail它们本身也是函数,也能返回数据。而复杂一点说,就是回调函数本身就是函数,但是它们却被其他函数给调用,而调用函数的函数被称为高阶函数。
1、传入参数获取执行结果
在技术文档里可以看到几乎所有小程序的API都有success、fail、complete回调函数,success为接口调用成功的回调函数,fail为接口调用失败的回调函数,complete为接口调用结束的回调函数(调用成功、失败都会执行),原因在于这些API大多数是异步API。异步API的执行结果需要通过 Object类型的参数中传入的对应回调函数获取:
wx.getNetworkType({
success(res) { //传入res来获取回调函数的结果,res是对象
console.log(res)
},
fail(err){ //传入err来获取回调函数的结果,err也是对象
console.log(err)
},
complete(msg){//传入msg来获取回调函数的结果,msg也是对象
console.log(msg)
}
});
以上回调函数的写法如果使用箭头函数,它的形式如下:
wx.getNetworkType({
success: res => {
console.log(res)
},
fail: (err) => {
console.log(err)
},
complete: () => {
//没有传入参数,不获取返回结果
}
});
2、异步与同步
我们前面也提及过异步,那什么会有异步呢?因为JavaScript是单线程的编程语言,就是从上到下、一行一行去执行代码,类似于排队一样一个个处理,第一个不处理完,就不会处理后面的。但是遇到网络请求、I/O操作(比如上面的读取图片信息)以及定时函数(后面会涉及)以及类似于成功反馈的情况,等这些不可预知时间的任务都执行完再处理后面的任务,肯定不行,于是就有了异步处理。
把要等待其他函数执行完之后,才能执行的函数(比如读取图片信息)放到回调函数里,先不处理,等图片上传成功之后再来处理,这就是异步。比如wx.showToast()消息提示框,可以放到回调函数里,当API调用成功之后再来显示提示消息。回调函数相当于是异步的一个解决方案。
3、Promise调用方式
从基础库2.10.2版本起,小程序的异步API除了支持。当接口参数 Object对象中不包含 success/fail/complete 时将默认返回 promise,否则仍按回调方式执行。Promise调用方式的写法的如下:
wx.getNetworkType() //需要传参数的API,可以写成wx.getNetworkType({name:"呵呵"})
.then(res => {
console.log(res)
})
.catch(err => {
console.log(err)
})
尽管callback的写法也是ok的,但是我们更加推荐使用这种写法,不过要使用这种写法首先要注意你的基础库的版本是否设置为2.10.2以上。在后面云开发的部分,我们会更多的采用这种写法。
47、云函数中的main与return
云函数主要执行的是index.js中的main方法,因此要确保云函数中含有main函数,return主要有两个作用。
- 返回数据给云函数的调用方
- 终结云函数的执行。
在main函数的其他函数里要注意一些写法,比如云函数是支持async/await的,不过在await再用then链式写法,就没有返回值了(const data 的值会是undefined),因为返回值作为promise传递到then中了,而云函数调用的结果为空
const cloud = require('wx-server-sdk')
cloud.init({
env:cloud.DYNAMIC_CURRENT_ENV
})
const db = cloud.database()
const _ = db.command
exports.main = async(event, context) => {
const data = await db.collection("china")
.where({
_id:_.exists(true)
})
.get()
.then(res=>{
console.log("then打印的结果",res)//会返回数据库查询的结果
})
console.log("data对象",data)//data为undefined
return data //返回的data为空
}
面对这个问题,有两个解决方法,一是不要使用then链式,二是在then方法里return一个返回值,更加推荐采用第一种方式。
//方法一,不使用then链式,可以使用try..catch捕捉异常。
const data = await db.collection("china")
.where({
_id:_.exists(true)
})
.get()
//方法二,使用return返回一个data
const data = await db.collection("china")
.where({
_id:_.exists(true)
})
.get()
.then(res=>{
console.log("then打印的结果",res)
return res
})
console.log("data对象",data)
注意方法二里尽管我们在then方法里使用了return,但是return只是终结数据库请求,以及返回数据给data,并不会中断云函数的执行,也不会把res的数据返回给main。因此,下面的方法调用云函数时也的返回值也会是null:
await db.collection("china") //const data = await db.collection("china") 同样也不会给main返回任何数据
.where({
_id:_.exists(true)
})
.get()
.then(res=>{
console.log("then打印的结果",res)
return res
})
48.小程序数据查询
const db = wx.cloud.database() //获取数据库的引用
const _ = db.command //获取数据库查询及更新操作符
db.collection("china") //获取集合china的引用
.where({ //查询的条件操作符where
gdp: _.gt(3000) //查询筛选条件,gt表示字段需大于指定值。
})
.field({ //显示哪些字段
_id:false, //默认显示_id,这个隐藏
city: true,
province: true,
gdp:true
})
.orderBy('gdp', 'desc') //排序方式,降序排列
.skip(0) //跳过多少个记录(常用于分页),0表示这里不跳过
.limit(10) //限制显示多少条记录,这里为10
.get() //获取根据查询条件筛选后的集合数据
.then(res => {
console.log(res.data)
})
.catch(err => {
console.error(err)
})
大家可以留意一下数据查询的链式写法, wx.cloud.database().collection('数据库名').where().get().then().catch(),前半部分是数据查询时对对象的引用和方法的调用;后半部分是Promise对象的方法,Promise对象是get的返回值。写的时候为了让结构更加清晰,我们做了换行处理,写在同一行也是可以的。get查询会先进行权限匹配,再来查询,也就是如果集合里没有符合权限的记录,是查不到数据的。
48.1.构建查询条件的5个方法
不过值得注意的是这5个方法顺序不同查询的结果有时也会有所不同(如orderBy和skip多次打乱顺序的情况下),查询性能也会有所不同。通常skip最好放在后面,不要让skip略过大量数据。skip().limit()和limit().skip()效果是等价的。
构建查询条件的5个方法是基于集合引用Collection的,就拿where来说,不能写成wx.cloud.database().where(),也不能是 wx.cloud.database().collection("china").doc.where(),只能是 wx.cloud.database().collection("china").where(),也就是只能用于查询集合collection里的记录。
这五个方法是可以单独拆开使用的,比如只使用where或只使用field、limit,也可以从这5个中抽几个组合在一起使用,还可以一次查询里写多个相同的方法,比如orderBy、where可以写多次的。查询返回的结果都是记录列表,是一个数组。
1)查询条件 where
与记录的值本身相关的条件都会写在where方法里,where里可以是值匹配(如gdp: _.gt(3000));后面我们会介绍的command查询操作符比如筛选字段大于/小于/不等于某个值的比较操作符,同时满足多个筛选条件的逻辑操作符等,以及模糊查询的正则都是写在where内。
通过where构建条件来筛选记录,不仅可以用于查询get,还可以用于删除remove、更新update、统计记录数count以及实时监听watch(add不必用where)。
2)指定返回哪些字段field
查询时只需要传入 true|false(或 1|-1)就可以返回或不返回哪些字段,在上面的案例里我们就只返回city、province、gdp三个字段的值。
我们可以使用field不返回我们不需要的字段和字段值,这会减少返回的数据的体积,这也是性能优化比较重要的。
3)数据排序orderBy
排序的语法为orderBy('字段名', '排序方式'),里面为排序的条件,这里的字段名不受field的限制(不在field内只是不返回,但是还是会起作用)。
排序方式只支持desc降序、asc升序这两种方式,如果字段里面的值时数字就按照大小,如果是字母就按照先后顺序,不支持中文的排序方式。
排序支持按多个字段排序,多次调用orderBy即可,多字段排序时的顺序会按照orderBy调用顺序先后对多个字段排序。
如果需要对嵌套字段排序,可以使用点表示法,比如上面的books根据出版年份year从旧到新排序,可以写为orderBy('publishInfo.year','asc')
4)分页显示skip
skip常与limit一起用于分页,比如商品列表一页只显示20个商品,第1页显示整个数据的0~20个,那么第2页我们用skip(20)可以跳过第一页的20条数据,第3页则跳过40个数据,第N页则是skip((n-1)*20)个数据。
5)限制数量上限的limit
数据查询的数量上限limit在小程序端默认为20,上限也是20;在服务端(云函数)默认为100,上限则是1000,比如limit(30)在小程序端还是只会显示20条数据。
48.2.统计记录
对于通过构建查询条件得到的记录,不仅可以用户查询get,还可以用于删除remove、更新updata、统计记录count以及实时监听watch。
count()方法可以用来统计查询条件匹配到的记录数,和get()一样,count与集合权限设置有关,在小程序端一个用户仅能统计其有读权限的记录数,而云函数端由于不受权限设置的控制,可以统计集合内所有符合条件的记录数
const db = wx.cloud.database()
const _ = db.command
db.collection("china")
.where({
gdp: _.gt(3000)
})
.count().then(res => {
console.log(res.total)
})
//或者我们可以这样写,注意要写在async里,云函数的main自带async,小程序端要加async
const count = await db.collection("china")
.where({
gdp: _.gt(3000)
})
.count()
field、orderBy、skip、limit对count是无效的,只有where才会影响count的结果,count只会返回记录数,不会返回查询到的数据。注意count请求不能和get、remove、update等混用,如果你既想查询数据又想获取count值,只能分两次查询了。
49.关于小程序批量新增、删除、更新记录
目前云开发还不支持在小程序端批量新增记录,只能一条一条的加,data参数的值也必须是object,而不能是数组array,但是在服务端(云函数端和云开发控制台的高级脚本操作)可以支持一次性增加多条记录。
我们可以用remove请求删除多条记录,用update来更新多条记录,不过需要注意的是简易权限控制不支持在小程序端执行remove请求和批量更新(基于db.collection的update就是批量更新多条记录)。只有开启了安全规则(自定义权限)才行;当然,服务端具有最高权限,也可以在云函数端和通过脚本来操作多条记录。
50去除页面滚动条方法
.father{ //父元素
width: 100vw;
height: 100vh;
overflow-x: hidden;
overflow-y: auto;
}
//隐藏滚动条
::-webkit-scrollbar {
width: 0;
height: 0;
color: transparent;
display: none;
}
51.下载文件转发给好友功能
小程序官方文档中有一个打开文档的API,wx.openDocument,其中有一个showMenu的参数,设置为true的话,在打开文档后,右上角会出现一个按钮,其中包含了“发送给朋友。
wx.downloadFile({
url: that.data.downList[index].url,
success: function (res) {
wx.hideLoading()
wx.openDocument({
filePath: res.tempFilePath,
showMenu: true,/*设置该选项后,可以在打开文件的同时,将文件转发给其他用户。*/
success: function (res) {
console.log('打开文档成功', res)
},
fail: function (res) {
console.log("打开文档失败", res)
}
});
},
fail: function (err) {
wx.hideLoading()
console.log('下载失败:', err);
},
})
52.小程序的临时文件、本地文件、文件缓存和数据缓存
52.1.临时文件
文件在上传时比如使用wx.chooseMessageFile、wx.chooseImage会先将文件从相册或微信对话里上传至临时文件;而文件下载时,比如使用wx.downloadFile会将文件从远程服务器下载到临时文件,下载的临时文件最大50M,临时文件在用户关闭了小程序页面时,就不存在了。
openDoc(){
wx.downloadFile({
url: 'https://786c-xly-xrlur-1300446086.tcb.qcloud.la/bkzy20203_11.pdf', //链接可以替换为云存储里面的下载地址,文档格式需要是pdf、word、excel、ppt
success (res) {
console.log("成功回调之后的res对象",res)
if (res.statusCode === 200) {
wx.openDocument({
filePath: res.tempFilePath,//临时文件地址
success: function (res) {
console.log('打开文档成功')
},
fail:function(err){
console.log(err)
}
})
}
}
})
},
52.2.本地文件
在获取到临时文件地址之后,可以使用wx.saveImageToPhotosAlbum()接口将文件保存至本地相册。
52.3.本地缓存
在获取到临时文件地址后,可以使用wx.saveFile将文件下载至本地存储,但是本地存储只有10M大小,但是下载完成之后,只要不清理缓存,再次打开这个文件时就不要重新再次下载了,即使关闭这个页面。
downloadPDF(){
const that = this
wx.downloadFile({
url: 'https://786c-xly-xrlur-1300446086.tcb.qcloud.la/bkzy20203_11.pdf', //链接可以替换为云存储里面的下载地址,文档格式需要是pdf、word、excel、ppt
success (res) {
console.log("成功回调之后的res对象",res)
if (res.statusCode === 200) {
wx.saveFile({
tempFilePath: res.tempFilePath,
success (res) {
console.log(res)
that.setData({
savedFilePath:res.savedFilePath//文件在本地缓存的地址。
})
}
})
}
}
})
}
52.4、数据缓存
相比于临时文件、文件缓存,小程序的数据缓存可以维持的时间存储的时间更长,除非用户主动删除小程序,数据缓存里面的数据就一直有效;数据缓存的空间也有10M的大小,可以用来存储用户的阅读记录、购买记录、浏览记录、登录信息等比较关键的信息,增强用户的体验。
临时文件的图片
缓存保存的图片
data: {
tempFilePath: '',
savedFilePath: '',
},
chooseImage:function() {
const that = this
wx.chooseImage({
count: 1,
success(res) {
that.setData({
tempFilePath: res.tempFilePaths[0]
})
}
})
},
saveImage:function() {
const that = this
wx.saveFile({
tempFilePath: this.data.tempFilePath,
success(res) {
that.setData({
savedFilePath: res.savedFilePath
})
wx.setStorageSync('savedFilePath', res.savedFilePath)
},
})
},
onLoad: function (options) {
this.setData({
savedFilePath: wx.getStorageSync('savedFilePath')
})
},
编译之后,点击请上传文件的button,会触发chooseImage事件处理函数,然后调用上传图片的API wx.chooseImage,这时会将图片上传到临时文件,并将取得的临时文件地址赋值给tempFilePath,有了tempFilePath,图片就能渲染出来了。
然后再点击保存文件到缓存的button,会触发saveImage事件处理函数,然后保存文件API wx.saveFile,将tempFilePath里的图片保存到缓存,并将取得的缓存地址赋值给savedFilePath(注意tempFilePath也就是临时路径是保存文件的必备参数),这时缓存保存的图片就渲染到页面了。然后会再来调用缓存API wx.setStorageSync(),将缓存文件的路径保存到缓存的key savedFilePath里面。有些参数名称相同但是含义不同,这个要注意。
通过wx.setStorageSync()保存到缓存里的数据,可以使用wx.getStorageSync()获取出来,我们在onLoad里把获取出来的缓存文件路径再赋值给savedFilePath。编译页面,看看临时文件与缓存文件的不同,临时文件由于小程序的编译会被清除掉,而缓存文件有10M的空间,只要用户不刻意删除,它就会一直在。
53.globalData
在 app.js的全局文件globalData可以存放一些供其他页面使用的数据,比如登录信息,api的key等。将一些通用的数据、函数单独拿出来存放在globalData里或进行模块化,是在实际开发中会经常使用到的一种方法,它可以让数据、函数更容易管理以及可以重复利用,使得代码更加精简。
54.小程序端SDK和云函数端SDK的区别
小程序端SDK与云函数端SDK虽然有很多相似之处,不过有不少不同的地方,具体表现如下:
54.1.权限体系
小程序端自带微信用户鉴权和安全规则,用户可以免鉴权登录小程序,在对数据库、云存储操作时受简易权限或安全规则的控制,比如权限设置为仅创建者可读写时,用户A就无法看到或修改用户B创建的数据,保证了小程序端SDK操作云存储、云数据库和云函数等资源时的安全性;而云函数端SDK则拥有云开发资源的最高权限(管理员权限),不受简易权限或安全规则的影响,用户A调用云函数时也能增删改查用户B创建的数据(可以使用云函数的逻辑来限制)。
值得一提的是,只有小程序端SDK调用云函数才能获取用户的登录态,管理端(控制台、云函数)调用云函数是获取不到用户的openid的(如果有需要,可以使用数据库等方式将openid作为参数传入)。
54.2.对数据库的增删改查
在小程序端直接使用SDK增删改查数据库,相比先调用云函数,再通过云函数来操作数据库来说,前者无论是在速度上(直接对数据库进行crud速度大概快100ms左右),还是在云函数的资源消耗上(后者会消耗云函数的资源使用量GBs、外网出流量)都更优。一般情况下,更加建议使用这种方案。
不过通过云函数来操作数据库相比小程序直接操作数据库来说,一是更加安全(小程序端代码容易被逆向),二是处理更灵活(比如小程序的修改都需要发布并通过审核而云函数端不会),三是更容易跨端(多个小程序可以共用一个云开发环境里的一套云函数代码)。
通常情况下来说,能用小程序端SDK处理的就尽量使用小程序端SDK,将数据的处理放在小程序端可以有效的减轻云函数的压力,提升处理速度,也降低使用成本。
54.3PI的支持
比如实时数据推送watch方法只支持小程序端SDK,而聚合查询里的联表查询lookup就只能在云函数端进行;如果数据库使用的是简易权限控制,小程序端就无法对数据库进行批量更新或删除(where.update、where.remove)。
54.4网络请求
在小程序端使用wx.request()发起的网络请求只支持https,不支持http和ip,且域名需要备案,而在云函数端,我们可以使用axios、got等第三方模块发起网络请求,它不仅支持https、http、ip等,而且域名也不需要备案。此外,云函数也可以有固定的ip,尤其是数据库、公众号开发等对ip白名单有一定要求的情况。
54.5云调用以及定时触发器
云调用是云开发提供的基于云函数使用小程序、腾讯云开放接口的能力,比如订阅消息、云支付、图像处理等,尽管云调用也有https调用,不过云调用更加安全方便。
小程序端SDK的调用只有在用户打开和使用小程序的情况下才能执行,而云函数可以脱离小程序,在定时触发器的作用下定时/定期的执行一些任务。
54.5后端服务
云函数不仅可以在wx-server-sdk模块的支持下使用云函数端SDK调用云开发环境里的资源,还可以安装一些Node.js的模块,来为小程序提供一些后端服务,比如收发邮件、短信、通知消息,连接MySQL、Redis等数据库,进行图像、音视频等的处理等等(在《用云函数实现后端能力》会介绍)。
55.云开发的数据规划
当我们要开发一个功能比较复杂的小程序时,首先就要对功能函数模块和数据、数据库进行一个合理的规划与设计。
在相册小程序,我们使用了数据库的反范式化设计,将单个用户所需要的数据都嵌套在一个文档里,不过这种数据库的设计方式不适用于关系比较复杂的项目,比如博客、商城、CRM等相关的小程序。这时,我们需要将数据分散到不同的集合里,不同的集合可以通过唯一的ID来相互引用(使用联表查询或跨表多次查询),也就是范式化设计。
当我们要进行范式化设计时,就需要和关系型数据库一样,需要先确定实体(比如博客的文章、用户)、实体的属性(比如文章的标题,用户的用户名)、实体之间的联系(比如用户与文章的关系,是不是作者、收藏者、评论者以及指定唯一标识的字段,如_id、id、openid等)以及实体与联系之间的约束(比如只有登录的用户才能评论),并做出理清了实体、属性、关系等联系的E-R图,E-R图做出来之后,基础的集合与记录的结构就清晰了,最后根据E-R图来建立集合。文档型数据库并不需要像关系型数据库一样需先建好字段并约束字段的长度、类型等;也可以不必建立专门的联系表。
当然我们不可过度追求范式化,范式化会降低数据的读取速度,会出现为了读取数据需要跨多表甚至要要联表的情况。根据实际情况采取一定的反范式化设计,而反范式化就会增加一些冗余字段,用空间换取时间的做法在一些情况下是有必要的。反范式化的设计在数据一致性的处理上会比较麻烦,同时嵌套数组、对象有时候则要借助于聚合操作才能获取到值。在后面数据库的高阶用法章节里,我们还会提到数据库的设计的问题。
云开发数据库这种文档型的非关系型数据库,我们在设计时,即使是采用范式化设计,也并不需要像关系型数据库那样将所有的关系都分散成二维表,也就是不会做绝对的范式化,根据功能需要我们既可以将有些数据分散到多个集合里,也可以将有些数据以内嵌数组或对象的形式存储到集合的一个字段里,相比于关系型数据库来说,处理起来非常灵活。而我们到底应该怎么安排这些数据,取决于你对小程序功能的规划、控制数据访问的安全模式以及如何更有效提高数据请求的性能.
56.小程序的工程化
要开发一个相对比较复杂的小程序项目,在我们对小程序的数据流、交互功能、数据库设计有了清晰的认识后,就需要了解小程序的工程化,工程化主要包含规范化、组件化、模块化。
在我们进行正式的小程序开发之前,就应该对项目的目录结构、文件命名、函数命名、接口封装、代码格式等制定一个规范,这样的规范化有助于我们实际开发时就不致于混乱。
当页面的逻辑越来越多,一个小程序页面的代码过于复杂,或者同样的页面逻辑会在不同的页面重复使用,这个时候就需要我们会页面的功能或逻辑进行拆分,拆分时注意权衡细粒度与通用性,这方面的具体内容可以参考小程序技术文档里的自定义组件。
而模块化指的是将功能复杂的函数代码、CSS代码等划分成各司其职且又相互依赖的模块,比如前面介绍的js模块化(通过module.exports暴露接口和require引入公共代码)等。
57.云数据库安全规则
在控制台新建一个数据表,使用安全规则并将权限修改为“所有人可读,仅创建者可读写”,即{"read": true,"write": "doc._openid == auth.openid" },这样就启用了安全规则。
无论你是用简易版的权限设置,还是使用安全规则,在这里我们都不需要事先获取用户的openid,因为如果你使用的是简易版权限,对数据库进行增删改查时都会自带where({_openid:'{openid}'})的条件;而如果使用时安全规则,你可以直接使用这个条件,它不需要我们知道用户的openid具体是什么。也就说,我们没有必要先用云函数返回用户的openid,省了这样一个操作,能提升小程序的加载速度以及节省云开发资源。
比如我们想知道数据表handover中有那些是用户写入的数据(该数据的openid为该用户的openid)。
在简易规则的情况下的过滤条件:
db.collection('handover')
where({})
相当于
--------------------------
db.collection('handover')
where({
_openid:"{
{openid}}"
})
在开启数据库安全规则的情况下过滤条件:
db.collection('clouddisk').
where({
_openid:'{openid}' //一定要开启安全规则,不开安全规则{openid}会失效,没有开启安全规则,数据库查询自带openid的权限,就不需要写这个条件了
})
在通过删选后得到用户自己的数据(该数据的openid为该用户的openid),然后就可以对这些数据进行删、改、查了。
向数据库中增加数据,也是同一个道理,比如用户向数据表handover数据表中写入数据时,在简易规则的情况下:
db.collection('handover')
.add({
data:{
SN:"123456",
name:"张三"
}
})
相当于:
db.collection('handover')
.add({
data:{
_openid:"{openid}"
SN:"123456",
name:"张三"
}
})
在开启安全规则的情况下的写法:
db.collection('handover')
.add({
data:{
_openid:"{openid}"
SN:"123456",
name:"张三"
}
})
58.两种方式引入weui组件库步骤
58.1.useExtendedLib引入组件包
优点:
1.引入简单
2.不占用包体积
缺点:
1.自由化低,不能直接修改组件库,增加功能
2.不稳定,不同版本WeUI相同组件暴露的方法都会有较大差异,会发现突然有些功能不好使。(暂未发现指定版本配置,猜测是动态获取最新的)
3.不支持分包使用
引入步骤:
1、在全局配置文件app.json中
"style": "v2",
"sitemapLocation": "sitemap.json",
"useExtendedLib": {
"weui": true
}
2、在引用页面的json文件中声明组件名称
在json配置引用组件时,注意组件路径的写法,
{
"usingComponents": {
"mp-dialog": "weui-miniprogram/dialog/dialog"
}
}
3、在引用页面的wxml中直接使用该组件
test content
4、结果
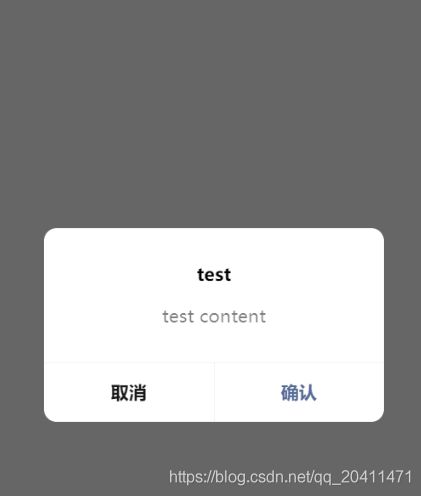
58.2.通过NPM构建引入weui组件库
优点:
1.稳定性良好(版本固定)
2.自由化程度高,可以自由改造或者增减组件的持有
3.分包依旧可以使用
缺点:
1.占用包体积
2.组件样式需要全局引用
引入步骤:
1.cd到项目根路径 npm install 初始化项目
npm install -y
然后按照提示完成初始化
2.下载weui-miniprogram到本地
npm install --save weui-miniprogram
3.通过编译器构建npm模块(工具——构建NPM)
4.编译本地设置勾选npm模块
5.全局样式引用
app.wxss文件中引入WeUI.样式,至此通过NPM构建的方式引入weui组件已经完成。
@import '/miniprogram_npm/weui-miniprogram/weui-wxss/dist/style/weui.wxss';
6.组件引用
//index.json
{
"usingComponents": {
"mp-dialog": "weui-miniprogram/dialog/dialog"
}
}
//wxml
test content
58.2.富文本渲染标签
html等富文本的渲染需要使用特殊的标签rich-text.
你可能感兴趣的:(微信小程序)