Javase常见面试题目的学习笔记、知识点整理(边学边补充)
1. 九种基本数据类型的大小,以及他们的封装类。
| 简单类型 |
boolean |
byte |
char |
short |
Int |
long |
float |
double |
void |
| 二进制位数 |
1 |
8 |
16 |
16 |
32 |
64 |
32 |
64 |
-- |
| 封装器类 |
Boolean |
Byte |
Character |
Short |
Integer |
Long |
Float |
Double |
Void |
参考:http://www.cnblogs.com/doit8791/archive/2012/05/25/2517448.html
2.Switch能否用String做参数?
Java7前不可以,Java7后可以使用String做参数。
Java7以后,支持的类型有:byte, short, int, char和它们的封装类,以及String, enum
注意,不支持long和浮点型。
3.equals与==的区别。
==比较的是两个数据的内存地址是否相同,是不是同一个对象。
equals在Object类里作用与==相同,但可以重写该方法,使其比较的是两个数据的内存地址存储的值是否相同,两个对象的内容是不是相同。
4.Object有哪些公用方法?
getClass(), equals(), hashCode(), clone(), toString(), wait(), notify(), notifyAll(), finalize()
| 方法摘要 | |
|---|---|
protected Object |
clone()创建并返回此对象的一个副本。 |
boolean |
equals(Object obj)指示其他某个对象是否与此对象“相等”。 |
protected void |
finalize()当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。 |
Class |
getClass()返回此 Object 的运行时类。 |
int |
hashCode()返回该对象的哈希码值。 |
void |
notify()唤醒在此对象监视器上等待的单个线程。 |
void |
notifyAll()唤醒在此对象监视器上等待的所有线程。 |
String |
toString()返回该对象的字符串表示。 |
void |
wait()在其他线程调用此对象的 notify() 方法或notifyAll() 方法前,导致当前线程等待。 |
void |
wait(long timeout)在其他线程调用此对象的 notify() 方法或notifyAll() 方法,或者超过指定的时间量前,导致当前线程等待。 |
void |
wait(long timeout, int nanos)在其他线程调用此对象的 notify() 方法或notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量前,导致当前线程等待。 |
5. Java的四种引用,强弱软虚,用到的场景。
参考:http://blog.csdn.net/u012403246/article/details/45741445
6. Hashcode的作用。
1、hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的;
2、如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同;
3、如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点;
4、两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们“存放在同一个篮子里”。
再归纳一下就是hashCode是用于查找使用的,而equals是用于比较两个对象的是否相等的。
参考:http://efany.github.io/2016/03/14/%E9%9D%A2%E8%AF%95%E9%A2%98J2SE%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
7. ArrayList、LinkedList、Vector、Stack的区别。
ArrayList 是一个可改变大小的数组。get和set的效率比LinkedList高(快),增加和删除的效率比LinkedList低(慢)。当需要请求空间时,每次对size增长50%.。
LinkedList 是一个双链表。get和set的效率比ArrayList低(慢),增加和删除的效率比ArrayList高(快)。实现了 Queue 接口。
Vector和ArrayList类似,也实现了可增长的数组。但是,它是同步的,是线程安全的,故效率比ArrayList低。一般在集合需要被多个线程共用时使用。当需要请求空间时,每次请求其大小的双倍空间。
Stack继承于Vector,实现了一个先进后出的栈。
8. String、StringBuffer与StringBuilder的区别。
String 字符串常量,+号追加内容,实际上是生成新对象。
StringBuffer 字符串变量(同步,线程安全),append()追加内容,速度比String快。
StringBuilder 字符串变量(非同步,非线程安全),append()追加内容,速度比StringBuffer 快。
参考:http://blog.csdn.net/rmn190/article/details/1492013
10. HashMap和HashTable的区别。
(1)HashMap和HashTable都实现了Map接口,但HashMap继承于AbstractMap,HashTable继承于废弃的类Dictionary。
(2)HashMap是非同步的,线程不安全的。HashTable是同步的,线程安全的。
(3)HashMap允许null值,HashTable不允许null值。
(4)HashMap通过Iterator遍历,HashTable可以通过Enumeration或Iterator遍历。
(5)HashMap重新计算hashCode(解决冲突),HashTable直接使用对象的hashCode。
(6)HashMap中hash数组的默认大小是16,而且一定是2的指数。 HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
11. HashMap和ConcurrentHashMap的区别,HashMap的底层源码。
HashMap是非同步的,线程不安全的。如果需要同步, 可以用Collections.synchronizedMap(HashMap map)方法使HashMap具有同步的能力。
ConcurrentHashMap是同步的,线程安全的。在hashMap的基础上,ConcurrentHashMap将数据分为多个segment,然后每次操作对一个segment加锁(即锁分段技术)。
HashMap底层源码参考:http://www.cnblogs.com/yumo/p/4909518.html
12.HashMap、LinkedHashMap、 TreeMap的区别。
HashMap无序,不可排序。
LinkedHashMap保存了插入顺序。
TreeMap能够根据键排序, 默认升序, 也可以指定排序的比较器。
13.Collection包结构,与Collections的区别。
Collection 是单列集合,子接口主要有:Set(无序,不可重复),List(有序,可重复),Queue(先进先出)等。(Map 是双列集合。)
Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。
Collections 是一个工具类,对集合类进行包装,提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
同样的,还有一个Arrays,这个是数组的工具类。
14. try catch finally,try里有return,finally还执行么?
会。程序会在执行完finally块之后,再return。
如果是System.exit(0);,那么finally不会执行。
15. Exception与Error包结构。OOM你遇到过哪些情况,SOF你遇到过哪些情况。
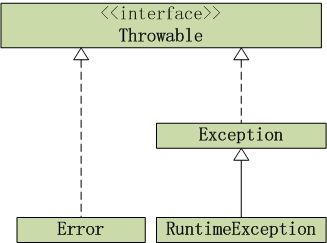
Throwable是 Java 语言中所有错误或异常的超类。
Error 是 Throwable 的子类,用于指示合理的应用程序不应该试图捕获的严重问题。大多数这样的错误都是异常条件。如:VirtualMachineError,IOError(不应该捕获)
Exception是 Throwable 的子类,它指出了合理的应用程序想要捕获的条件。 编译器会检查Exception异常。如:CloneNotSupportedException,IOException(必须捕获)
RuntimeException 是Exception的子类,是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。编译器不会检查RuntimeException异常。 如:ArithmeticException,IndexOutOfBoundsException,ClassCastException,IllegalArgumentException,NullPointerException (可以捕获,也可以不捕获)
OOM:Out Of Memory,引起OOM主要有2个原因,分别是内存泄漏和内存溢出(即堆溢出和栈溢出)。
SOF:Stack Over Flow,栈溢出主要发生在递归的调用中 。
OOM和SOF:递归调用可以导致栈溢出,不断创建对象可以导致堆溢出。
参考:http://www.cnblogs.com/yumo/p/4909617.html
16. Java面向对象的四个特征与含义。
抽象,封装,继承,多态。
参考:https://yq.aliyun.com/articles/52843
https://blog.csdn.net/liaohongqing_55/article/details/54947058
17.Override和Overload的含义去区别。
Override是重写,子类对从父类继承过来的方法作新的实现。当父类引用指向子类对象时,调用的是子类的方法,体现了运行时的多态性。
Overload是重载,在同一类中,允许函数名相同,但参数必须不同。体现了编译时的多态性。
18.Interface与abstract类的区别。
Interface是接口,没有构造方法,方法都是public abstract,java8之前不允许有方法体,java8允许接口有默认方法和静态方法。
abstract类是抽象类,可以有构造方法,但不能被实例化。
子类使用extends继承抽象类,使用implements实现接口,并且只允许单继承,但可实现多个接口。
参考:http://www.importnew.com/12399.html
19. Static class 与non static class的区别。
(1)非静态内部类能够访问外部类的静态和非静态变量,但是静态内部类只能访问外部类的静态变量。
(2)非静态内部类不能脱离外部类实体被创建,但是静态内部类可以。
参考:http://www.voidcn.com/blog/mingtianhaiyouwo/article/p-6148293.html
20. java多态的实现原理。
(1)编译时多态:通过函数重载来实现。
(2)运行时多态:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。必须具备的条件有:继承类(或实现接口),重写,父类引用指向子类对象。
21. 实现多线程的方法:
(1)继承Thread类。
(2)实现Runnable接口。
(3)实现Callable接口通过FutureTask包装器来创建Thread线程
(4)通过Executor框架创建线程池。
优先选择实现Runnable接口, 因为它不需要继承,便于以后程序的拓展。
参考:https://www.cnblogs.com/felixzh/p/6036074.html
22. 线程同步的方法:
sychronized关键字、lock接口、可重入锁reentrantLock等。
在并发量比较小的情况下,使用synchronized是个不错的选择,但是在并发量比较高的情况下,其性能下降很严重,此时ReentrantLock是个不错的方案。
参考:https://yq.aliyun.com/articles/52845
23. 锁的等级:
方法锁、对象锁、类锁。
方法锁和对象锁会存在竞争关系,也就是同一时刻,只能有一个在执行,另外一个处于等待的状态。
类锁不会跟对象锁造成矛盾,可以同时进行。
参考:https://yq.aliyun.com/articles/52851
24.写出生产者消费者模式。
参考:
马士兵教程。
https://zh.wikipedia.org/wiki/%E7%94%9F%E4%BA%A7%E8%80%85%E6%B6%88%E8%B4%B9%E8%80%85%E9%97%AE%E9%A2%98#Java_.E4.B8.AD.E7.9A.84.E4.BE.8B.E5.AD.90
http://java--hhf.iteye.com/blog/2064926
25.ThreadLocal的设计理念与作用。
在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。这时该变量是多个线程共享的,使用同步机制要求程序慎密地分析什么时候对变量进行读写,什么时候需要锁定某个对象,什么时候释放对象锁等繁杂的问题,程序设计和编写难度相对较大。
而ThreadLocal则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
概括起来说,对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
参考:http://blog.csdn.net/u011860731/article/details/48733073
http://itfish.net/article/22032.html
26.ThreadPool用法与优势。
用法:使用Executors框架创建线程池。
优势:
(1)降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;
(2)提高系统响应速度,当有任务到达时,无需等待新线程的创建便能立即执行;
(3)方便线程并发数的管控,线程若是无限制的创建,不仅会额外消耗大量系统资源,更是占用过多资源而阻塞系统或oom等状况,从而降低系统的稳定性。线程池能有效管控线程,统一分配、调优,提供资源使用率;
(4)更强大的功能,线程池提供了定时、定期以及可控线程数等功能的线程池,使用方便简单。
参考:http://blog.csdn.net/scboyhj__/article/details/48805881
http://gityuan.com/2016/01/16/thread-pool/
27.Concurrent包里的其他东西:ArrayBlockingQueue、CountDownLatch等等。
(1)ArrayBlockingQueue:是JAVA5中的一个阻塞队列,能够自定义队列大小,当获取队列中的头部元素时,如果队列为空,那么它将会使执行线程处于等待状态;当添加一个元素到队列的尾部时,如果队列已经满了,那么它同样会使执行的线程处于等待状态。
参考:http://www.jianshu.com/p/9a652250e0d1
http://www.cnblogs.com/belen/archive/2012/04/13/2446019.html
http://blog.csdn.net/mazhimazh/article/details/19239033
(2)CountDownLatch:一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
参考:http://zapldy.iteye.com/blog/746458 (简洁明了)
http://www.itzhai.com/the-introduction-and-use-of-a-countdownlatch.html
28. wait()和sleep()的区别。
(1)wait() 是Object类的方法,sleep()是Thread类的方法。
(2)wait() 只能在同步控制块或同步方法里使用,sleep() 没有此规定。
(3)wait() 会释放同步锁,sleep() 不会释放同步锁。
29. foreach与正常for循环效率对比。
遍历集合时,for > foreach > iterator。
参考:http://blog.csdn.net/zq602316498/article/details/39163899 (第五点)
30. Java IO与NIO。
(1)IO是面向流的,阻塞的。主要依靠Stream。
(2)NIO(New IO)是面向缓冲的,非阻塞的,主要依靠Chanel,Buffer和Selector。
参考:http://tutorials.jenkov.com/java-nio/selectors.html
31.反射的作用于原理
参考:http://www.voidcn.com/blog/zbuger/article/p-5771880.html
http://m.blog.csdn.net/article/details?id=50955303
32.List
(1)List
List ls = new ArrayList();
List
(2)泛型的特点:1.在编译时期自动检查转换类型 2.编译后不包含参数类型,即类型擦除。
参考:http://www.cnblogs.com/bin-study/archive/2013/01/22/2870968.html
33.解析XML的几种方式的原理与特点:DOM、SAX、PULL
1.DOM
DOM解析方法首先把xml文件读取到内存中,保存为节点树的形式,然后我们使用其API来读取树上的节点的信息。由于DOM解析xml文件时需要将其载入到内存,故xml文件较大时或内存较小的设备不适用该方法。
2.SAX
与DOM不同,SAX全称为Simple API for XML ,是基于事件驱动的解析手段。对于SAX而言分析xml能够立即开始,而不用等待所有的数据被处理。而且,由于SAX只是在读取数据时检查数据,因此不需要将数据存储在内存中。一般来说SAX解析比DOM解析快许多,但由于SAX解析xml文件是一次性处理,因此相对DOM而言没有那么灵活方便。
3.PULL
与SAX类似,Pull也是一种基于事件驱动的xml解析器。与SAX不同在于Pull让我们手动控制解析进度,通过返回eventType来让我们自行处理xml的节点,而不是调用回调函数,eventType有如下几种:
总结如下:
需要解析小的xml文件,需要重复解析xml文件或需要对xml文件中的节点进行删除修改排序等操作:使用DOM
需要解析较大的xml文件,只需要解析一次的xml文件:使用SAX或Pull
只需要手动解析部分的xml文件:使用Pull
参考:http://m.blog.csdn.net/article/details?id=50955303
http://www.jianshu.com/p/e636f4f8487b
34. Java与C++对比。
Java与C++的区别点很多,这里只列出几点区别:
(1)Java是完全面向对象的,属性与方法不能脱离类而存在; C++兼容了C语言,因此并非完全面向对象。
(2)Java由于JVM存在,可以实现跨平台;C++不行。
(3)Java拥有垃圾回收机制,GC会自动回收内存。C++必须手动回收内存。
(4)Java只支持单继承,C++支持多重继承。
(5)Java不支持运算符重载,C++支持。
(6)Java舍弃了C++的指针,采用引用来代替。
(7)Java不允许使用goto语句,C++允许。
(8)Java不支持预处理功能,C++支持。
(9)Java不支持自动强制类型转换,需要显式地进行强制类型转换;C++支持。
35. Java1.7与1.8新特性。
只记得比较重大的新特性:
Java1.7:
二进制形式的字面值表示
在数值类型的字面值中使用下划线分隔符联接
Switch语句支持String类型
新增try-with-resources语句
单个catch子句同时捕获多种异常类型(使用 | )
创建泛型实例时自动类型推断( 可以这样写:List
参考:
http://www.365mini.com/page/5.htm
Java1.8
接口可以定义默认方法和静态方法
引入Lambda表达式和函数式接口
方法引用
重复注解
参考:
http://www.jianshu.com/p/5b800057f2d8
http://www.cnblogs.com/tony-yang-flutter/p/3503935.html
36. 设计模式:单例、工厂、适配器、责任链、观察者等等。
参考马士兵视频,慕课网视频。
37. JNI的使用。
全称是Java Native Interface,使得在JAVA实现跨平台的同时,也能与其它语言(如C、C++)的动态库进行交互
参考:
http://landerlyoung.github.io/blog/2014/10/16/java-zhong-jnide-shi-yong/
http://www.cnblogs.com/icejoywoo/archive/2012/02/22/2363709.html