原文链接:http://tecdat.cn/?p=18782
本文我们讨论了期望寿命的计算。人口统计模型的起点是死亡率表。但是,这种假设有偏差,因为它假设生活条件不会得到改善。为了正确处理问题,我们使用了更完整的数据,其中死亡人数根据x岁而定,还包括日期t。
2. DE=read.table("DE.txt",skip = 3,header=TRUE)
3. EXPS=read.table("EXPS.txt",skip = 3,header=TRUE)我们用 Dx,t表示死亡人数,Ex,t表示暴露人数。因此,对于在日期t上x岁的某人,在该年死亡的概率为 qx,t = Dx,t / Ex,t。这些数据存储在矩阵中进行可视化,存储在数据库中进行回归。
2. QF[QF==0]=NA
3. QH[QH==0]=NA必须进行一些修改以避免出现零值的问题,因为(i)我们求出比率(ii)然后我们对数化)。我们可以可视化为x和t的函数。
persp(log(QF)) 或
2. persp3d(ages,annees,log(QH),col="light blue") 
为了模拟qx,t的演化,我们可以从Lee&Carter(1992)的模型中获得启发,该模型 假设log (qx,t)= Ax + Bx⋅Kt。A =(A0,A1,⋯,A110)在某种程度上是log(qx,t)。K =(K1816,K1817,⋯,K2015)使我们了解生活条件的改善,一年内死亡的可能性降低。这些改善不是均匀的,因此我们使用B =(B0,B1,⋯,B110)来使改善取决于l '年龄。
为了估计参数A,B和K,我们尝试使用二项式模型。B(Ex,t,qx,t),这是人寿保险的基本模型。这里Dx,t〜B(Ex,t,exp [ Ax + Bx⋅Kt])。
另一个线索是使用小数定律,即如果概率低(一年中的死亡概率就是这种情况),则二项式定律可以近似由泊松分布。我们在这里用到了Poisson回归,其解释变量为年龄x,年t和暴露量为偏移变量。唯一的问题是它不是线性回归。我们这里有非线性模型,因为E [ Dx,t] =(exp[log(Ex,t)+ Ax + Bx⋅Kt])。
2. gnm( DH ~ offset(log(EH) + as.factor(age) +
3. Multas.factor(age,as.factor(annee),
4. family = poisson(link="log")我们有估计系数A ^,B ^和K ^。
2. Ax=reg$coefficients[2:111]
3. Bx=reg$coefficients[112:222]
4. Kt=reg$coefficients[223:length(reg$coefficients)]我们可以表示三组系数。首先 A ^表示平均变化,
plot(ages[-1],Ax) 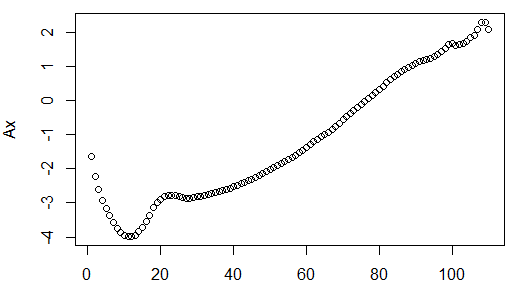
我们还可以用 K ^来绘制时间。

同样,该模型不可被识别。简而言之,改善没有任何意义。我们可以表示-K ^,它的优点是描述了生活条件的改善。最后,让我们作图-B ^
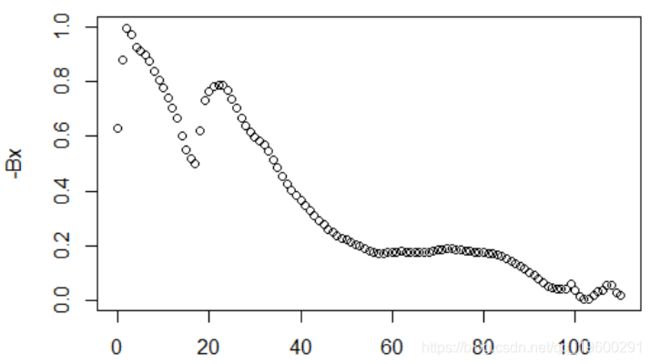
困难在于,为了预测期望寿命,我们需要针对t的大值(尚未观察到)计算qt,x。例如,某人可能想知道q50,2020(对于1970年出生的人)。我们要使用q50,2020 = exp(A ^ 50 + B ^ 50 K ^ 2020)。问题是K ^ 2020不属于估计数量K ^。
这个想法是Lee&Carter(1992)的初衷,我们可以尝试指数模型或线性模型(在1950年以后的原始K ^序列上)
2. lm(log(Kt[idx])~ann[idx])
3. futur=2016:2125
5. lm(Kt[idx]~ann[idx])
7. points(futur,pr,col="blue") 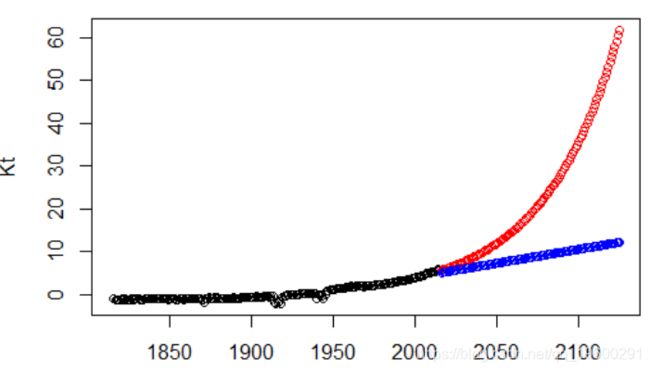
然后,我们可以根据过去的数据建立一系列预测,q ^ x,t = exp [A ^ x + B ^ x K ^ t],以及未来数据q〜x,t = exp [A ^ x + B ^ x K〜t]。
我们保留过去的数据,这里是1880年死亡的概率
2. plot(BASE$x[BASE$t==1880],BASE$pred[BASE$t==1880],
3. log="y") 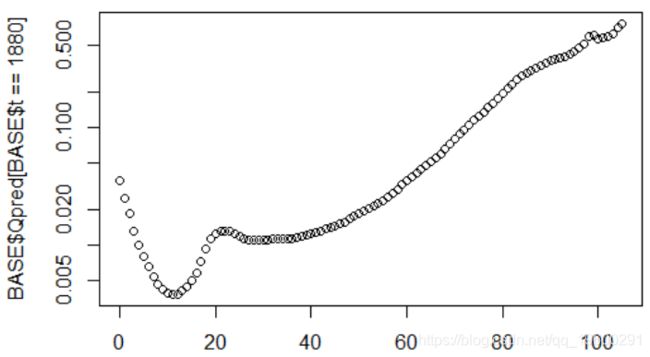
同样,我们在未来(此处为2050年)使用这两种模型
2. BASE2$Qpred1=exp(cste+BASE2$Ax+BASE2$Bx*BASE2$Kt1)
5. plot(BASE2$x[BASE2$t==2050],BASE2$Qpred1[BASE2$t==
6. 2050],log="y") 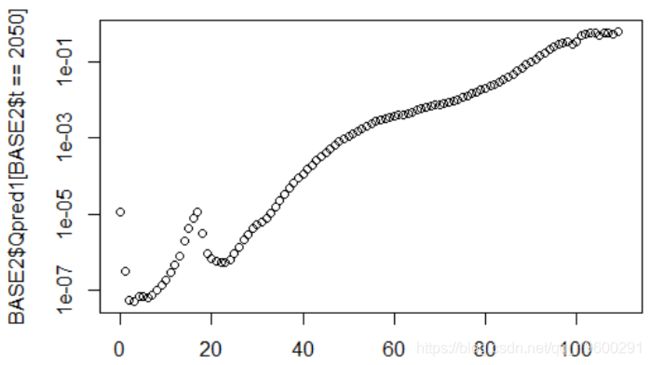
用于指数预测
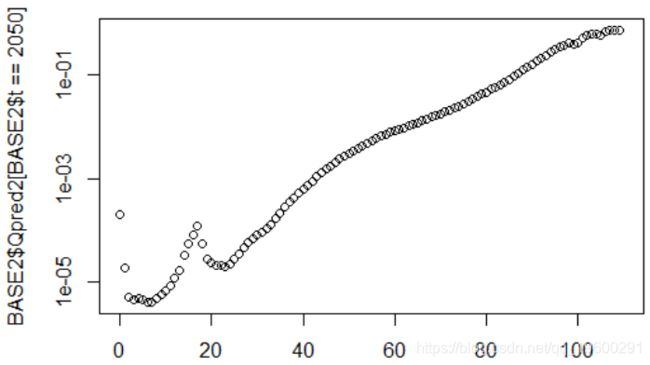
对于线性预测,对1968年出生的人,我们有第二年死亡的概率
2. if(sbase$t[i]<= 2015)
3. {vq[i]=BASE[ BASE$x==sbase$x[i]) & BASE$t==sbase$t[i]),"Qpred"]
4. if(sbase$t[i] <2015)
5. {vq[i]=BASE2[(BASE2$x==sbase$x[i]) & (BASE2$t==sbase$t[i]),"Qpred2"] 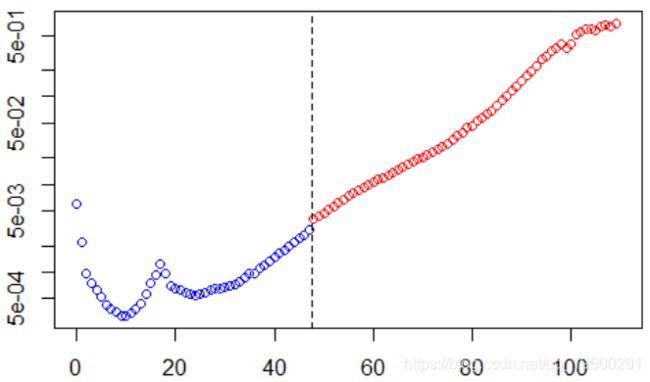
左边是我们模型估算值,右边是预测值。
要计算出生时的期望寿命,我们使用以下代码
1. sum(cumprod(exp(-vq[1:110])))
2. [1] 77.62047
然后,我们可以做函数可视化这种期望寿命的演变
2. vP = cumprod(exp(-(sbase$vq[1:110])))
3. sum(vP)} 2. ANN =1930:2010
3. plot(ANN ,E2) 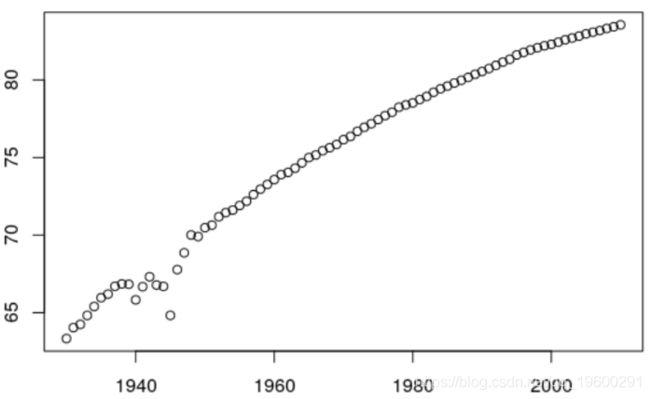
如果我们看一下变化,我们发现每年(大约)有0.25的变化
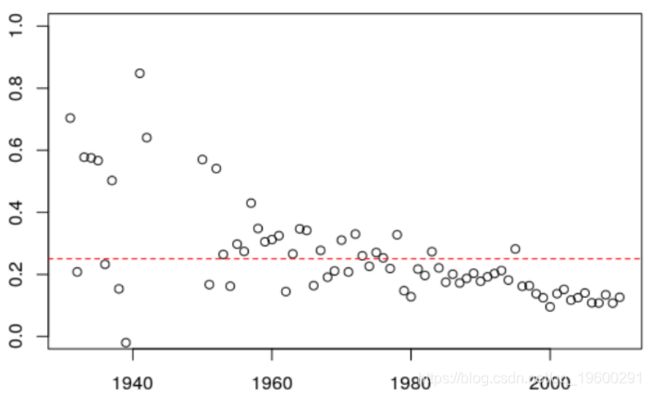
另一方面,如果我们采用保留Kt指数变化的预测,则可以得出
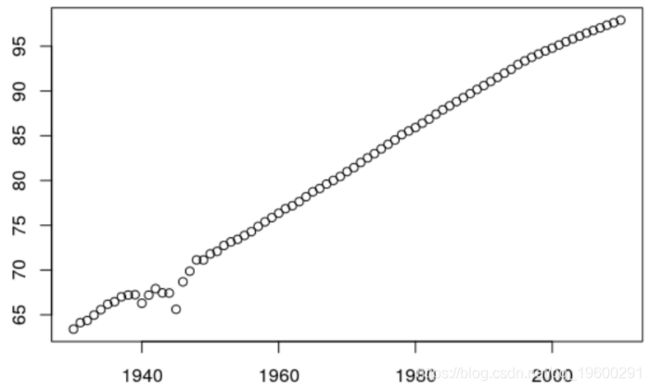
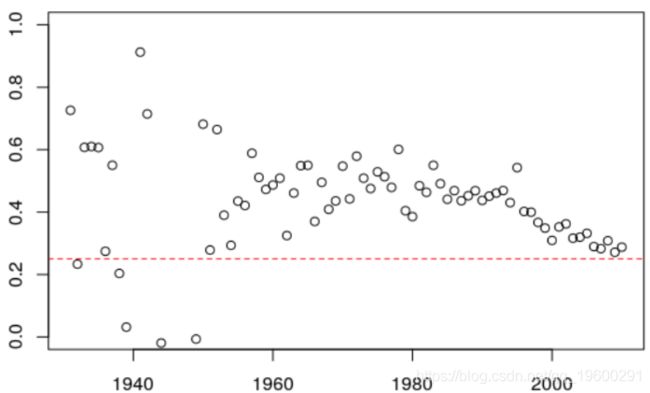
结果不符合实际,它更少地考虑曲线的变化。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验