scrapy笔记二(CrawlSpider爬取图片并存储)
前言
就是肝
实例
流程和技术点分析
- 以中国插画网为目标网站新建CHAHUA项目,chahua爬虫名,start.py文件为执行文件
- settings.py(协议False、请求头、pipeline、imageastore)
- chahua.py
- pipeline.py
- items.py
重点理论
1.Rule , Link Extractors多用于全站的爬取
Rule是在定义抽取链接的规则
follow是一个布尔值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback 为None,follow 默认设置为True,否则默认为False。
当follow为True时,爬虫会从获取的response中取出符合规则的url,再次进行爬取,如果这次爬取的response中还存在符合规则的url,则再次爬取,无限循环,直到不存在符合规则的url。
当follow为False是,爬虫只从start_urls 的response中取出符合规则的url,并请求。
2.LinkExtractor单独使用
可用来提取完整url
代码实例
chahua.py
1.导入
from scrapy.spiders.crawl import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
2.ruel制定
start_urls = ['http://chahua.org/']
rules = {
# Rule(LinkExtractor(allow=r"http://www.chahua.org/"), follow=False,),
Rule(LinkExtractor(allow=r"http://www.chahua.org/drawn/detail.php?id=554887&hid=3"), follow=False,callback="parse_detail")
}
在这里遇到问题,制定具体页面规则也有回调解析函数,但是无法返回想要结果
如图
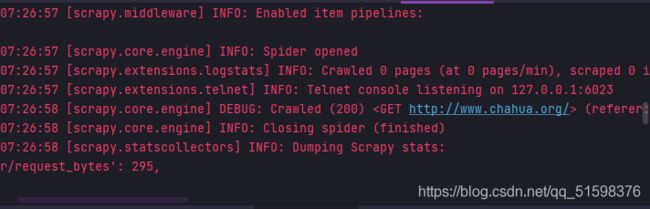
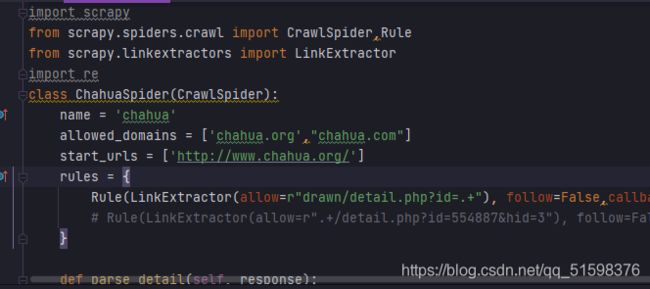
折腾许久未能解决插画网用crawlspider找到制定内容,只好转过头以站酷网为目标网站新建ZCOOL项目,zcool爬虫名以进行下一步图片下载学习,不能再插画网上吊死
3.zcool.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders.crawl import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
from ..items import ImagedownloadItem
class ZcoolSpider(CrawlSpider):
name = 'zcool'
allowed_domains = ['zcool.com.cn']
# start_urls = ['http://zcool.com.cn/']
start_urls = ['https://www.zcool.com.cn/discover/0!0!0!0!0!!!!2!0!1']
rules = {
# 翻页的url
Rule(LinkExtractor(allow=r'.+0!0!0!0!0!!!!2!0!\d+'),follow=True),
# 详情页面的url
Rule(LinkExtractor(allow=r".+/work/.+html"),follow=False,callback="parse_detail")}
def parse_detail(self, response):
image_urls = response.xpath("//div[@class='work-show-box']//img/@src").getall()
title_list = response.xpath("//div[@class='details-contitle-box']/h2/text()").getall()
title = "".join(title_list).strip()
print(title)
item = ImagedownloadItem(title=title,image_urls=image_urls)
yield item
保存的字段必须有imge_urls和images
导入from …items import ImagedownloadItem之前编写items.py
import scrapy
class ImagedownloadItem(scrapy.Item):
title = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
注意,这里是 ImagedownloadItem
4.完成zcool.py编写后进入下一个难点ITEM_PIPELINES
在settings.py中开启所需的pipeline作保存数据
ITEM_PIPELINES = {
#'imagedownload.pipelines.ImagedownloadPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
专用于图片下载的管道
接着制定图片下载路径,images_store
下一个问题是拿到本项目的images文件夹路径
通过os模块,先找到自己即settings.py的路径再找到imagedownload文件夹路径,最后再找到images路径
os.path.dirname(file)指获取当前文件的目录
os.path.dirname(os.path.dirname(file))指获取当前文件的目录的上级目录
然后再与images拼接,用os.path,join
os.path.join(os.path.dirname(os.path.dirname(file)),‘images’)
pipeline.py是这样的
class ImagedownloadPipeline(object):
def process_item(self,item,spider):
return item
最终结果



问题与总结
1.加domain域名
2.安装pillow库
3.Overridden settings报错,铁是settings文件或是爬虫写错了,错了就是错了,这个锅自己背o(╥﹏╥)o
4.折腾这个图片下载花费时间差不多五六天,浪费了很多时间没能达到效果也没有理解pipeline,重写函数,到现在能看的见得成果知识成功修正示例代码成功下载了而已,重写函数具体定义命名文件的操作还没有掌握o(╥﹏╥)o
这个问题有需求再去解决
下面研究scrapy的selenium