爬虫(19)pipline补充+item的讲解+古诗文案例
文章目录
- 第十九章 pipline补充与item的讲解和古诗文案例
-
- 1. pipline的补充
- 3. item的使用
- 4. 古诗文案例
-
- 4.1 思路
- 4.2 爬取
-
- 4.2.1 爬取标题
- 4.2.2 爬取作者和朝代
- 4.2.3 爬取内容
- 4.3 使用items
- 4.4 使用管道pipelines
- 4.5 保存数据
- 4.6 翻页
- 5. 垃圾回收
第十九章 pipline补充与item的讲解和古诗文案例
上一章我们讲了怎样创建一个scrapy项目,怎样爬取数据,保存数据。后面讲了一个豆瓣的小案例,来熟悉一下scrapy的使用。我们遗留了一个问题,就是在项目的末尾用的是yiled而不是return。这次课我们来具体研究一下。
我们以前讲过有两种情形可以产生生成器,一个是通过列表推导式,一个是通过yield关键字。生成器可以更加节省内存的空间。由于有时候我们爬取的内容非常的多,return返回数据会占据大量的内存。yield的占用内存小,而且使用灵活。虽然yield和return都有返回数据的作用,但是return在返回之后就结束了程序的运行。而yield在返回数据后,可以继续运行下面的代码。而且yield把数据给pipline,在scrapy中有一个yield scrapy.Request对象。 如果有翻页对象,我们的scrapy框架会获取该对象,把链接给引擎,然后由引擎把链接交给调度器。 我们通过一个案例来操作一下,讲解这个知识点。
1. pipline的补充
我们打开pipline 。可以定义多个pipline,可能有多个spider,不同的pipline处理不同的item内容。另外一个spider内容也可以做不同的操作,比如存入不同的数据中。
注意:
- pipline的权重越小,优先级越高。
- pipline中的process_item方法名不能修改为其他的名称。
我们打开settings
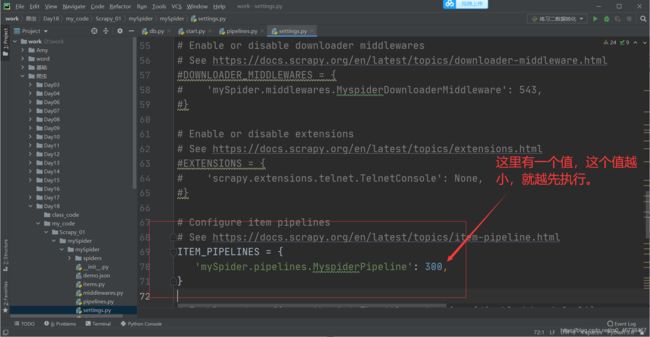
我们复制一个改一下名称和值,放在下面:

同时,我们在piplines里面把对应的类创建出来:

记得,这个方法
def process_item(self, item, spider):
return item
必须得有,不能改变。
下面我为了验证这两个pipline谁先执行,我把代码做如下改变:
import json
class MyspiderPipeline:
def process_item(self, item, spider):
item['hello'] = 'world'
return item
def close_spider(self,item): # 爬虫结束的名字不能改变
self.f.close()
print('爬虫结束了')
class MyspiderPipeline1():
def process_item(self, item, spider):
print(item)
return item
我们在豆瓣里面穿过来得item字典里面已经有了标签得名称,这里如果MyspiderPipeline先执行,那么就在前面得内容后面会跟一个新的键值对"hello":“world”。如果MyspiderPipeline1()先执行,那么打印出来得直接是只有含有标签一个键值对。我们start一下验证:

结果是有’hello’: 'world’的,就验证了我们的说法,值小的先执行。
我们看到pipline中有一个spider,那么它的作用是什么呢?

通过这个参数我们可以获取一个爬虫的名字。下面我们打印一下spider的类型和值。需要在settings和pipelines里面都把第二个pipeline注释一下:
import json
class MyspiderPipeline:
# def __init__(self):
# self.f = open('demo.json','w',encoding='utf-8')
def open_spider(self,item): # 爬虫开始的名字不能改变
print('爬虫开始了')
def process_item(self, item, spider):
# item_json = json.dumps(item,ensure_ascii=False)
# self.f.write(item_json+'\n')
# # print(item)
# item['hello'] = 'world'
print(type(spider),spider)
return item
def close_spider(self,item): # 爬虫结束的名字不能改变
# self.f.close()
print('爬虫结束了')
# class MyspiderPipeline1():
# def process_item(self, item, spider):
# print(item)
# return item

start一下:

我们看到类型是一个DbSpider对象,可以在后面加一个.name获得名字。
def process_item(self, item, spider):
# item_json = json.dumps(item,ensure_ascii=False)
# self.f.write(item_json+'\n')
# # print(item)
# item['hello'] = 'world'
print(spider.name)
return item
start一下:

我们看到得到的爬虫名字是db。所以我们可以代码改动一下,就得到包含来源信息的结果:
import json
class MyspiderPipeline:
def open_spider(self,item): # 爬虫开始的名字不能改变
print('爬虫开始了')
def process_item(self, item, spider):
item['come_from'] = spider.name
print(item)
return item
def close_spider(self,item): # 爬虫结束的名字不能改变
print('爬虫结束了')
start一下看看:
爬虫开始了
{'name': '影讯&购票', 'come_from': 'db'}
{'name': '选电影', 'come_from': 'db'}
{'name': '电视剧', 'come_from': 'db'}
{'name': '排行榜', 'come_from': 'db'}
{'name': '分类', 'come_from': 'db'}
{'name': '影评', 'come_from': 'db'}
{'name': '预告片', 'come_from': 'db'}
{'name': '问答', 'come_from': 'db'}
{'name': '精选', 'come_from': 'db'}
{'name': '文化', 'come_from': 'db'}
{'name': '行摄', 'come_from': 'db'}
{'name': '娱乐', 'come_from': 'db'}
{'name': '时尚', 'come_from': 'db'}
{'name': '生活', 'come_from': 'db'}
{'name': '科技', 'come_from': 'db'}
{'name': '分类浏览', 'come_from': 'db'}
{'name': '阅读', 'come_from': 'db'}
{'name': '作者', 'come_from': 'db'}
{'name': '书评', 'come_from': 'db'}
{'name': '购书单', 'come_from': 'db'}
{'name': '音乐人', 'come_from': 'db'}
{'name': '潮潮豆瓣音乐周', 'come_from': 'db'}
{'name': '金羊毛计划', 'come_from': 'db'}
{'name': '专题', 'come_from': 'db'}
{'name': '排行榜', 'come_from': 'db'}
{'name': '分类浏览', 'come_from': 'db'}
{'name': '乐评', 'come_from': 'db'}
{'name': '豆瓣FM', 'come_from': 'db'}
{'name': '歌单', 'come_from': 'db'}
{'name': '阿比鹿音乐奖', 'come_from': 'db'}
{'name': '近期活动', 'come_from': 'db'}
{'name': '主办方', 'come_from': 'db'}
{'name': '舞台剧', 'come_from': 'db'}
爬虫结束了
最后我们总结一下:
- 可以开启多个管道,值越小优先级越高
- 可以在管道中获取爬虫的名字: spider.name 可以在item中进行设置。
3. item的使用
前面的案例中,我们在db项目里定义了一个字典,其实在items里面可以直接定义好你所爬取的数据结构。打开items

我们把# name = scrapy.Field()的注释解锁
然后打开项目db做以下操作:

打开pipelines做以下操作:

然后我们start一下:

我们看到也打印出了结果。我们可以在item里查看一下scrapy.Field()方法。

我们看到Field类继承了字典。但是name = scrapy.Field()并不是一个字典对象。

4. 古诗文案例
学完pipelines和items之后,我们来一个案例来熟悉一下scrapy的使用方法。
我们打开古诗文网站:https://www.gushiwen.cn/

我们要爬取的内容就是标题,作者,内容。
4.1 思路
第一步:创建Scrapy项目
我在pycharm中创建了一个新的文件夹 Day19>my_code>Demo

我们copy一下这个路径,cd到这个目录里面:

然后输入:
scrapy startproject gsw
回车,然后就到了这一步:

第二步 创建爬虫项目
cd gsw # cd到古诗文这个文件夹
scrapy genspider gs gushiwen.cn # 创建项目gs
回车后出现了:
D:\work\爬虫\Day19\my_code\Demo\gsw>scrapy genspider gs gushiwen.cn
Created spider 'gs' using template 'basic' in module:
gsw.spiders.gs
项目创建成功。
第三步 在settings文件里做一些基本配置
第一个,我们打开settings文件,Robot协议,我们改成False
第二个,我们加上LOG的等级
LOG_LEVEL = 'WARNING'

第三个 加一个user-agent
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36
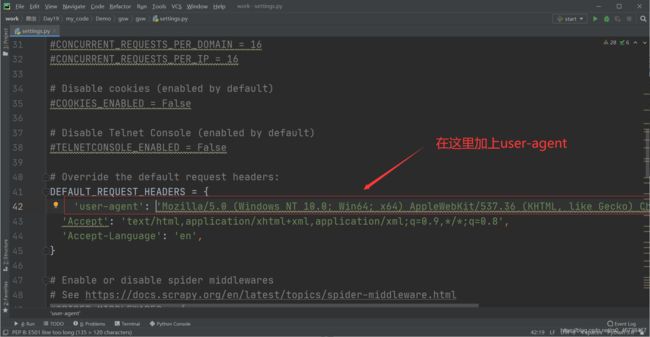
第四个 把管道也打开

第四步 页面分析
需求是:标题,朝代,作者和内容
除了这几个还需要翻页。
https://www.gushiwen.cn/ # 第一页
https://www.gushiwen.cn/default_1.aspx # 第一页
https://www.gushiwen.cn/default_2.aspx # 第二页
https://www.gushiwen.cn/default_3.aspx # 第三页
https://www.gushiwen.cn/default_4.aspx # 第四页
下面页面分析,右键,检查。
我们发现,当我们的鼠标停在class = "left"的div标签上的时候,所有的古诗都处于选中的状态。

这个就是最近的总标签了。
而鼠标停在class = "songs"的div标签上时,就有一首诗被选中:

这个就是每一首诗的标签。在这个标签里,我们依次找到了:
我们查找的数据都在class="cont"的div标签里。
标题在p标签里面的a标签里面的b标签里。

作者和朝代在一个class="source"的p标签里的a标签里。内容在class="contson"的div标签里。
4.2 爬取
下面我们操作爬取的过程。
4.2.1 爬取标题
打开spidder文件夹,打开里面的gs项目:

把start_urls里面的url改动一下,换成第一页的url,按照我们前面分析的路径我们找一下标题:
import scrapy
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.cn/default_1.aspx']
def parse(self, response):
# gsw_divs是所有古诗文数据所在的返回结果,是列表。
gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')
for gsw_div in gsw_divs:
# 因为b标签只有标题有,所以我们的路径就简略写了。
title = gsw_div.xpat('.//b/text').extract_first()
print(title)
我们定义一个start
from scrapy import cmdline
cmdline.execute('scrapy crawl gs'.split())
start一下看看

爬下来十首诗,除了这十首诗,其他两个位置有两个None。我们看看网页第一页,在《山中夜坐》和《连州阳山归路》之间是什么

我们看看在这个标签里的内容有些不一样。

我们在这个标签里没有找到b标签,所以返回了一个None。由于这些内容不是我们需要的,所以就忽略了。
4.2.2 爬取作者和朝代
下面我们爬取一下作者和朝代:
import scrapy
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.cn/default_1.aspx']
def parse(self, response):
# gsw_divs是所有古诗文数据所在的返回结果,是列表。
gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')
for gsw_div in gsw_divs:
# 因为b标签只有标题有,所以我们的路径就简略写了。
title = gsw_div.xpath('.//b/text()').extract_first() # 标题
source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract() # 作者和朝代
# print(source)
try:
author = source[0] # 作者
dynasty = source[1] # 朝代
except IndexError: # 当出现空列表时会报错,我们使用try语句跳过报错
continue
print(title,author,dynasty)
这里我们有必要声明一下几个点:
- 我们获取作者和朝代的时候,在class="source"的p标签中有两个a标签,其中一个时作者,另一个是朝代,故而这里取出所有,用extract()
- source返回的是一个列表,第0个元素是作者,第1个元素是朝代,但遇到特殊情况的时候会出现空列表,这时会报错IndexError:author = source[0] index out of range
- 为了解决上述报错,我们用try语句,当IndexError:出现时,continue跳到循环开始,重新循环。
start一下:

标题,作者,朝代都出现了。而且没有了None或者空列表。因为continue语句已经把这些跳过了。
4.2.3 爬取内容
下面我们做爬取内容的操作:
for gsw_div in gsw_divs:
# 因为b标签只有标题有,所以我们的路径就简略写了。
title = gsw_div.xpath('.//b/text()').extract_first() # 标题
source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract() # 作者和朝代
# print(source)
try:
author = source[0] # 作者
dynasty = source[1] # 朝代
except IndexError: # 当出现空列表时会报错,我们使用try语句跳过报错
continue
content_list = gsw_div.xpath('.//div[@class="contson"]//text()').extract() # 内容
# 这里//的意思是,获取满足当前节点条件下的所有后代节点,因为文本内容有换行节点,故而用双斜杠取出所有。
print(title,author,dynasty,content_list)
注意看注释:这里用到了//的知识,因为文本中每一句都有个换行标签,我们需要取出所有文本并返回一个列表,所以,用了双斜杠。我们start一下:

结果中出现了不必要的换行符还有些其他的数字符号,我们可以处理一下。
import scrapy
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.cn/default_1.aspx']
def parse(self, response):
# gsw_divs是所有古诗文数据所在的返回结果,是列表。
gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')
for gsw_div in gsw_divs:
# 因为b标签只有标题有,所以我们的路径就简略写了。
title = gsw_div.xpath('.//b/text()').extract_first() # 标题
source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract() # 作者和朝代
# print(source)
try:
author = source[0] # 作者
dynasty = source[1] # 朝代
except IndexError: # 当出现空列表时会报错,我们使用try语句跳过报错
continue
print(title,author,dynasty) # 打印出标题,作者,朝代
content_list = gsw_div.xpath('.//div[@class="contson"]//text()').extract() # 内容
# 这里//的意思是,获取满足当前节点条件下的所有后代节点,因为文本内容有换行节点,故而用双斜杠取出所有。
strs = content_list[:]
for str in strs: # 循环遍历出内容
print(str)
这里我们先打印每首诗的标题,作者,朝代,然后遍历打印出内容。注意看注释:
我们start一下:
鹦鹉曲·夷门怀古 冯子振 〔元代〕
人生只合梁园住,快活煞几个白头父。指他家五辈风流,睡足胭脂坡雨。说宣和锦片繁华,辇路看元宵去。马行街直转州桥,相国寺灯楼几处。
敬之 佚名 〔先秦〕
敬之敬之,天维显思,命不易哉。无曰高高在上,陟降厥士,日监在兹。维予小子,不聪敬止。日就月将,学有缉熙于光明。佛时仔肩,示我显德行。
咏二疏 陶渊明 〔魏晋〕
大象转四时,功成者自去。
借问衰周来,几人得其趣?
游目汉廷中,二疏复此举。
高啸返旧居,长揖储君傅。
饯送倾皇朝,华轩盈道路。
离别情所悲,余荣何足顾!
事胜感行人,贤哉岂常誉!
厌厌阎里欢,所营非近务。
促席延故老,挥觞道平素。
问金终寄心,清言晓未悟。
放意乐余年,遑恤身后虑!
谁云其人亡,久而道弥著。
庆东原·忘忧草 白朴 〔元代〕
忘忧草,含笑花,劝君闻早冠宜挂。那里也能言陆贾?那里也良谋子牙?那里也豪气张华?千古是非心,一夕渔樵话。
惜红衣·簟枕邀凉 姜夔 〔宋代〕
吴兴号水晶宫,荷花盛丽。陈简斋云:“今年何以报君恩,一路荷花相送到青墩。”亦可见矣。丁未之夏,予游千岩,数往来红香中,自度此曲,以无射宫歌之。
簟枕邀凉,琴书换日,睡余无力。细洒冰泉,并刀破甘碧。墙头唤酒,谁问讯、城南诗客。岑寂,高柳晚蝉,说西风消息。
虹梁水陌,鱼浪吹香,红衣半狼藉。维舟试望,故国渺天北。可惜渚边沙外,不共美人游历。问甚时同赋,三十六陂秋色?
少年游·算来好景只如斯 纳兰性德 〔清代〕
算来好景只如斯,惟许有情知。寻常风月,等闲谈笑,称意即相宜。
十年青鸟音尘断,往事不胜思。一钩残照,半帘飞絮,总是恼人时。
武昌九曲亭记 苏辙 〔宋代〕
子瞻迁于齐安,庐于江上。 齐安无名山,而江之南武昌诸山,陂陁蔓延,涧谷深密,中有浮图精舍,西曰西山,东曰寒溪。依山临壑,隐蔽松枥,萧然绝俗,车马之迹不至。每风止日出,江水伏息,子瞻杖策载酒,乘渔舟,乱流而南。山中有二三子,好客而喜游。闻子瞻至,幅巾迎笑,相携徜徉而上。穷山之深,力极而息,扫叶席草,酌酒相劳。意适忘反,往往留宿于山上。以此居齐安三年,不知其久也。
然将适西山,行于松柏之间,羊肠九曲,而获小平。游者至此必息,倚怪石,荫茂木,俯视大江,仰瞻陵阜,旁瞩溪谷,风云变化,林麓向背,皆效于左右。有废亭焉,其遗址甚狭,不足以席众客。其旁古木数十,其大皆百围千尺,不可加以斤斧。子瞻每至其下,辄睥睨终日。一旦大风雷雨,拔去其一,斥其所据,亭得以广。子瞻与客入山视之,笑曰:“兹欲以成吾亭邪?”遂相与营之。亭成而西山之胜始具。子瞻于是最乐。
昔余少年,从子瞻游。有山可登,有水可浮,子瞻未始不褰裳先之。有不得至,为之怅然移日。至其翩然独往,逍遥泉石之上,撷林卉,拾涧实,酌水而饮之,见者以为仙也。盖天下之乐无穷,而以适意为悦。方其得意,万物无以易之。及其既厌,未有不洒然自笑者也。譬之饮食,杂陈于前,要之一饱,而同委于臭腐。夫孰知得失之所在?惟其无愧于中,无责于外,而姑寓焉。此子瞻之所以有乐于是也。
普天乐·湖上废圃 张可久 〔元代〕
古苔苍,题痕旧。
疏花照水,老叶沉沟。
蜂黄点绣屏,蝶粉沾罗袖。
困倚东风垂杨瘦,翠眉攒似带春愁。
寻村问酒,无人倚楼,有树维舟。
赠去婢 崔郊 〔唐代〕
公子王孙逐后尘,绿珠垂泪滴罗巾。
侯门一入深如海,从此萧郎是路人。
杜司勋 李商隐 〔唐代〕
高楼风雨感斯文,短翼差池不及群。
刻意伤春复伤别,人间惟有杜司勋。
4.3 使用items
我们打开items,为items创建四个filed:
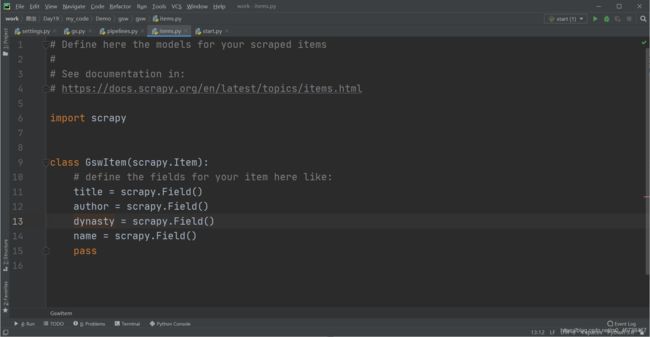
在gs项目中导入GswItem类,因为路径太长,我们可以右键gsw项目文件夹,选择mark Directory as Source Root将其定义为根目录文件夹

然后可以直接更方便的导入,语句是:
from gsw.items import GswItem
后面我们可以将数据传入item:
import scrapy
from gsw.items import GswItem
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.cn/default_1.aspx']
def parse(self, response):
# gsw_divs是所有古诗文数据所在的返回结果,是列表。
gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')
for gsw_div in gsw_divs:
# 因为b标签只有标题有,所以我们的路径就简略写了。
title = gsw_div.xpath('.//b/text()').extract_first() # 标题
source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract() # 作者和朝代
# print(source)
try:
author = source[0] # 作者
dynasty = source[1] # 朝代
content_list = gsw_div.xpath('.//div[@class="contson"]//text()').extract() # 内容
# 这里//的意思是,获取满足当前节点条件下的所有后代节点,因为文本内容有换行节点,故而用双斜杠取出所有。
content = ''.join(content_list).strip()
item = GswItem() # 实例化类
# 写法一
item['title'] = title
item['author'] = author
item['dynasty'] = dynasty
item['content'] = content
# 写法二
# item = GswItem(title=title,author=author,dynasty=dynasty,content=content)
yield item
except IndexError: # 当出现空列表时会报错,我们使用try语句跳过报错
continue
注意看注释,先实例化GswItem类,然后将爬取的数据传入item,有两种写法。
传入之后,我们在try语句的结尾写上yield item 将数据给管道pipelines
4.4 使用管道pipelines
打开pipelines,在里面写上打印语句。

我们在settings里面已经开启了管道,所以这里可以使用了。直接start一下:
{'author': '冯子振',
'content': '人生只合梁园住,快活煞几个白头父。指他家五辈风流,睡足胭脂坡雨。说宣和锦片繁华,辇路看元宵去。马行街直转州桥,相国寺灯楼几处。',
'dynasty': '〔元代〕',
'title': '鹦鹉曲·夷门怀古'}
{'author': '佚名',
'content': '敬之敬之,天维显思,命不易哉。无曰高高在上,陟降厥士,日监在兹。维予小子,不聪敬止。日就月将,学有缉熙于光明。佛时仔肩,示我显德行。',
'dynasty': '〔先秦〕',
'title': '敬之'}
{'author': '陶渊明',
'content': '大象转四时,功成者自去。借问衰周来,几人得其趣?游目汉廷中,二疏复此举。高啸返旧居,长揖储君傅。饯送倾皇朝,华轩盈道路。离别情所悲,余荣何足顾!事胜感行人,贤哉岂常誉!厌厌阎里欢,所营非近务。促席延故老,挥觞道平素。问金终寄心,清言晓未悟。放意乐余年,遑恤身后虑!谁云其人亡,久而道弥著。',
'dynasty': '〔魏晋〕',
'title': '咏二疏'}
{'author': '白朴',
'content': '忘忧草,含笑花,劝君闻早冠宜挂。那里也能言陆贾?那里也良谋子牙?那里也豪气张华?千古是非心,一夕渔樵话。',
'dynasty': '〔元代〕',
'title': '庆东原·忘忧草'}
{'author': '姜夔',
'content': '吴兴号水晶宫,荷花盛丽。陈简斋云:“今年何以报君恩,一路荷花相送到青墩。”亦可见矣。丁未之夏,予游千岩,数往来红香中,自度此曲,以无射宫歌之。 \n'
'簟枕邀凉,琴书换日,睡余无力。细洒冰泉,并刀破甘碧。墙头唤酒,谁问讯、城南诗客。岑寂,高柳晚蝉,说西风消息。虹梁水陌,鱼浪吹香,红衣半狼藉。维舟试望,故国渺天北。可惜渚边沙外,不共美人游历。问甚时同赋,三十六陂秋色?',
'dynasty': '〔宋代〕',
'title': '惜红衣·簟枕邀凉'}
{'author': '纳兰性德',
'content': '算来好景只如斯,惟许有情知。寻常风月,等闲谈笑,称意即相宜。十年青鸟音尘断,往事不胜思。一钩残照,半帘飞絮,总是恼人时。',
'dynasty': '〔清代〕',
'title': '少年游·算来好景只如斯'}
{'author': '苏辙',
'content': '子瞻迁于齐安,庐于江上。 '
'齐安无名山,而江之南武昌诸山,陂陁蔓延,涧谷深密,中有浮图精舍,西曰西山,东曰寒溪。依山临壑,隐蔽松枥,萧然绝俗,车马之迹不至。每风止日出,江水伏息,子瞻杖策载酒,乘渔舟,乱流而南。山中有二三子,好客而喜游。闻子瞻至,幅巾迎笑,相携徜徉而上。穷山之深,力极而息,扫叶席草,酌酒相劳。意适忘反,往往留宿于山上。以此居齐安三年,不知其久也。\n'
'\u3000\u3000'
'然将适西山,行于松柏之间,羊肠九曲,而获小平。游者至此必息,倚怪石,荫茂木,俯视大江,仰瞻陵阜,旁瞩溪谷,风云变化,林麓向背,皆效于左右。有废亭焉,其遗址甚狭,不足以席众客。其旁古木数十,其大皆百围千尺,不可加以斤斧。子瞻每至其下,辄睥睨终日。一旦大风雷雨,拔去其一,斥其所据,亭得以广。子瞻与客入山视之,笑曰:“兹欲以成吾亭邪?”遂相与营之。亭成而西山之胜始具。子瞻于是最乐。\n'
'\u3000\u3000'
'昔余少年,从子瞻游。有山可登,有水可浮,子瞻未始不褰裳先之。有不得至,为之怅然移日。至其翩然独往,逍遥泉石之上,撷林卉,拾涧实,酌水而饮之,见者以为仙也。盖天下之乐无穷,而以适意为悦。方其得意,万物无以易之。及其既厌,未有不洒然自笑者也。譬之饮食,杂陈于前,要之一饱,而同委于臭腐。夫孰知得失之所在?惟其无愧于中,无责于外,而姑寓焉。此子瞻之所以有乐于是也。',
'dynasty': '〔宋代〕',
'title': '武昌九曲亭记'}
{'author': '张可久',
'content': '古苔苍,题痕旧。疏花照水,老叶沉沟。蜂黄点绣屏,蝶粉沾罗袖。困倚东风垂杨瘦,翠眉攒似带春愁。寻村问酒,无人倚楼,有树维舟。',
'dynasty': '〔元代〕',
'title': '普天乐·湖上废圃'}
{'author': '崔郊',
'content': '公子王孙逐后尘,绿珠垂泪滴罗巾。侯门一入深如海,从此萧郎是路人。',
'dynasty': '〔唐代〕',
'title': '赠去婢'}
{'author': '李商隐',
'content': '高楼风雨感斯文,短翼差池不及群。刻意伤春复伤别,人间惟有杜司勋。',
'dynasty': '〔唐代〕',
'title': '杜司勋'}
4.5 保存数据
打开pipelines在里面写入以下代码:
import json
class GswPipeline:
def open_spider(self,spider):
self.fp = open('gsw.txt','w',encoding='utf-8')
def process_item(self, item, spider):
item_json = json.dumps(item,ensure_ascii=False)
self.fp.write(item_json+'\n')
return item
def close_spider(self,spider):
self.fp.close()
那么我start一下出现了以下报错

TypeError: Object of type GswItem is not JSON serializable
意思是GswItes类对象不可JSON序列化,这是因为item是GswItes类对象,而不是字典,不能这样简单传入 json.dumps(item,ensure_ascii=False),必须转化为字典后传入。 json.dumps(dict(item),ensure_ascii=False)
完整代码:
import json
class GswPipeline:
def open_spider(self,spider):
self.fp = open('gsw.txt','w',encoding='utf-8')
def process_item(self, item, spider):
item_json = json.dumps(dict(item),ensure_ascii=False)
self.fp.write(item_json+'\n')
return item
def close_spider(self,spider):
self.fp.close()
再start一下:
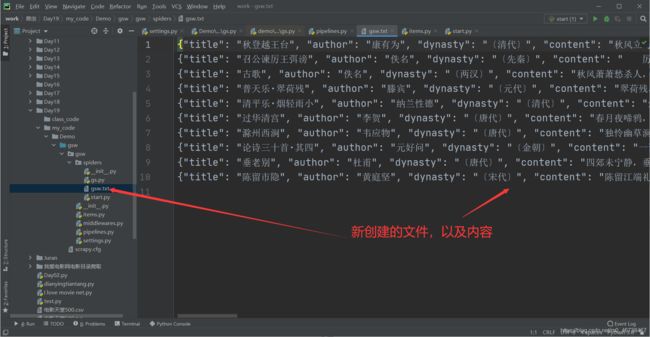
这一次成功运行了,创建了txt文件。
4.6 翻页
第一种方法直接将每页的url复制到项目文件gs的列表start_urls中。但这种方法不适合于页数多的情况。当然,如果你找到了url规律,也是可以加代码处理的,比如这个我是这样处理的:
from gsw.items import GswItem
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = []
for i in range(10):
start_urls.append('https://www.gushiwen.org/default_{}.aspx'.format(i+1))
结果也成功爬取的10页的内容:

第二种方法是这样子滴。在gs项目的代码中,前面的部分不变。只需要在后面加上一部分代码,拿到下一页的url,然后生成scrapy.Request对象,yield给引擎,引擎给调度器。然后做重复爬取和存储的操作。下面我们重点介绍这种方法。
我们通过翻页键找到下一页的url
右键最下方的翻页键,检查,我们看到了有关翻页的url部分,在id="amore"的a标签里的href的值里面。

下面的代码我们先找到翻页url:
import scrapy
from gsw.items import GswItem
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.org/default_1.aspx']
def parse(self, response):
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
print(next_href)
打印一下看看结果
https://www.gushiwen.cn/default_2.aspx
这就是第二页的url,是一个完整的url。如果不完整,我们可以使用scrapy提供的一个工具来拼接完整,下面我们介绍一下这个方法。
import scrapy
from gsw.items import GswItem
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.org/default_1.aspx']
def parse(self, response):
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
if next_href: # 做个非空判断,防止页面翻完后报错
next_url = response.urljoin(next_href) # 补全url: url如果是完整的就不管了,不是完整的就补全了
res = scrapy.Request(next_url) # 生成对象
yield res # yield给引擎
print(next_href)
需要说明的是,如果页面翻完了会报错,我们需要做一个非空判断。注意看注释。我们start一下:
https://www.gushiwen.cn/default_2.aspx
/default_3.aspx
/default_4.aspx
/default_5.aspx
/default_6.aspx
/default_7.aspx
/default_8.aspx
/default_9.aspx
/default_10.aspx
None
我们看到 print(next_href)只有第二个是完整的,其他的都不是完整的。我们再print(next_url)是用过补全工具后的url。
if next_href: # 做个非空判断,防止页面翻完后报错
next_url = response.urljoin(next_href) # 补全url: url如果是完整的就不管了,不是完整的就补全了
res = scrapy.Request(next_url) # 生成对象
yield res # yield给引擎
print(next_url)
结果:
https://www.gushiwen.cn/default_2.aspx
https://www.gushiwen.cn/default_3.aspx
https://www.gushiwen.cn/default_4.aspx
https://www.gushiwen.cn/default_5.aspx
https://www.gushiwen.cn/default_6.aspx
https://www.gushiwen.cn/default_7.aspx
https://www.gushiwen.cn/default_8.aspx
https://www.gushiwen.cn/default_9.aspx
https://www.gushiwen.cn/default_10.aspx
我们看到都被补全了。
下面要产生一个url对象yield给引擎,后面要重复操作爬取和存储的内容,所以我们加上之前的代码:
import scrapy
from gsw.items import GswItem
class GsSpider(scrapy.Spider):
name = 'gs'
allowed_domains = ['gushiwen.cn' ]
start_urls = ['https://www.gushiwen.org/default_1.aspx']
def parse(self, response):
gsw_divs是所有古诗文数据所在的返回结果,是列表。
gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')
for gsw_div in gsw_divs:
# 因为b标签只有标题有,所以我们的路径就简略写了。
title = gsw_div.xpath('.//b/text()').extract_first() # 标题
source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract() # 作者和朝代
# print(source)
try:
author = source[0] # 作者
dynasty = source[1] # 朝代
content_list = gsw_div.xpath('.//div[@class="contson"]//text()').extract() # 内容
# 这里//的意思是,获取满足当前节点条件下的所有后代节点,因为文本内容有换行节点,故而用双斜杠取出所有。
content = ''.join(content_list).strip()
item = GswItem() # 实例化类
# 写法一
item['title'] = title
item['author'] = author
item['dynasty'] = dynasty
item['content'] = content
# 写法二
# item = GswItem(title=title,author=author,dynasty=dynasty,content=content)
yield item
except IndexError: # 当出现空列表时会报错,我们使用try语句跳过报错
continue
# print(title,author,dynasty) # 打印出标题,作者,朝代
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
if next_href: # 做个非空判断,防止页面翻完后报错
next_url = response.urljoin(next_href) # 补全url: url如果是完整的就不管了,不是完整的就补全了
res = scrapy.Request(next_url) # 生成对象
yield res # yield给引擎
# print(next_url)
我们start一下,成功运行了。

一共一百个结果,说明十页古诗都被爬取了。
总结:
- 先找到下一页的url地址
- 通过yield scrapy.Request(url)
# 下面是处理翻页的代码
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
if next_href: # 做个非空判断,防止页面翻完后报错
next_url = response.urljoin(next_href) # 补全url: url如果是完整的就不管了,不是完整的就补全了
res = scrapy.Request(next_url) # 生成对象
yield res # yield给引擎
5. 垃圾回收
在程序中没有被引用的内容构成垃圾,所谓垃圾回收机制就是将没有用的对象从内存中删除。python内部自己有一个垃圾回收机制,不用我们自己动手操作,就会用不到的对象从内存中删除。当被引用的时候,会再次激活。这样可以保证程序的运行速度。