【Python数据分析与处理 实训05】--- 探索虚拟姓名数据(数据合并)
【Python数据分析与处理 实训05】— 处理分析虚拟姓名数据(数据合并)
探索虚拟姓名数据
1.声明数据
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
2.将上述的数据转为DataFrame并分别命名为data1,data2,data3
data1 = pd.DataFrame(raw_data_1)
data2 = pd.DataFrame(raw_data_2)
data3 = pd.DataFrame(raw_data_3)

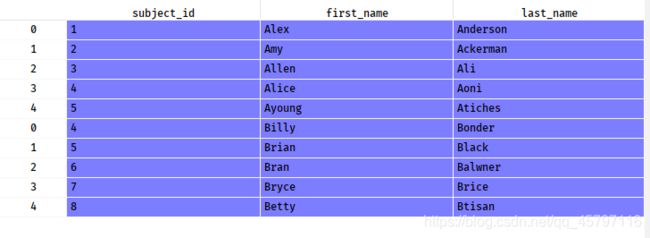
3.将data1和data2两个数据框按照行的维度进行合并,命名为all_data
all_data = pd.concat([data1,data2],axis=0)
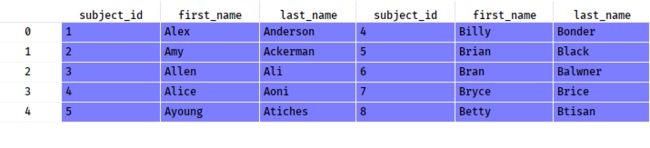
4.将data1和data2两个数据框按照列的维度进行合并,命名为all_data_col
all_data_col = pd.concat([data1,data2],axis=1)
5.打印data3
print(data3)

6.按照subject_id的值对all_data和data3进行合并
print(pd.merge(all_data,data3,on='subject_id'))

7.对data1和data2按照subject_id做连接
print(pd.merge(data1,data2,on='subject_id'))

8.找到data1和data2合并之后的所有匹配结果
print(pd.merge(data1,data2,on='subject_id',how='outer'))

这部分案例主要介绍的是pandas的DataFrame的生成以及pandas中的merge()方法合并数据集,可以将其看做是sql中的表连接,相关内容参见本人博客:Python----数据分析-pandas数据预处理.数据组合、Python----数据分析-pandas.DataFrame基础。