爬虫遇到反爬机制怎么办? 看看我是如何解决的!
01
前言
想着爬取『豆瓣』的用户和电影数据进行『挖掘』,分析用户和电影之间以及各自之间的关系,数据量起码是万级别的。
但是在爬取过程中遇到了反爬机制,因此这里给大家分享一下如何解决爬虫的反爬问题?(以豆瓣网站为例)
02
问题分析
起初代码
headers = {
'Host':'movie.douban.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'cookie':'bid=uVCOdCZRTrM; douban-fav-remind=1; __utmz=30149280.1603808051.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __gads=ID=7ca757265e2366c5-22ded2176ac40059:T=1603808052:RT=1603808052:S=ALNI_MYZsGZJ8XXb1oU4zxzpMzGdK61LFA; _pk_ses.100001.4cf6=*; __utma=30149280.1867171825.1603588354.1603808051.1612839506.3; __utmc=30149280; __utmb=223695111.0.10.1612839506; __utma=223695111.788421403.1612839506.1612839506.1612839506.1; __utmz=223695111.1612839506.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=223695111; ap_v=0,6.0; __utmt=1; dbcl2="165593539:LvLaPIrgug0"; ck=ZbYm; push_noty_num=0; push_doumail_num=0; __utmv=30149280.16559; __utmb=30149280.6.10.1612839506; _pk_id.100001.4cf6=e2e8bde436a03ad7.1612839506.1.1612842801.1612839506.',
'accept': 'image/avif,image/webp,image/apng,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'upgrade-insecure-requests': '1',
#'referer':'',
}
url = "https://movie.douban.com/subject/24733428/reviews?start=0"
r = requests.get(url, headers=headers)
上面是基本的爬虫代码,在requests里面设置headers(包含cookie),如果没有反爬机制的话,可以正常爬取数据。
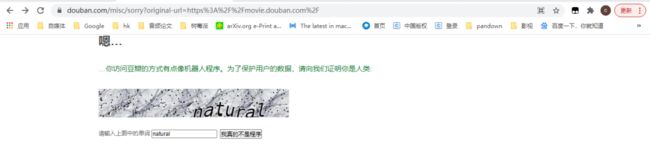
但是『豆瓣』网站有反爬机制!!

爬取就10几页之后,就出现这个验证!!
更关键的是:验证之后接着爬取,几秒后又出现这个,即使设置几秒爬取一次也无法解决!
03
解决方案
方案猜想
根据多年的爬虫经验,首先想到的是设置IP代理,这样就相当于不同用户在爬取网站,因此就通过ip代理去尝试,看看能否解决『豆瓣』的反爬机制。
获取大量IP代理
如果单纯设置一个IP代理,那样跟咱们之前在自己电脑上爬取没有什么区别,因此需要大量的IP代理,通过随机抽取的方式去使用IP代理,这样可以避免同一IP去爬取被『豆瓣』反爬机制禁爬。
IP代理正常来说,很贵,作为白嫖党,这里使用免费ip代理(亲测可用)
白嫖过程
https://h.shenlongip.com/index/index.html
白嫖的IP代理平台是:神龙Http,(这里不是广告,只是觉得可以白嫖,跟大家分享)
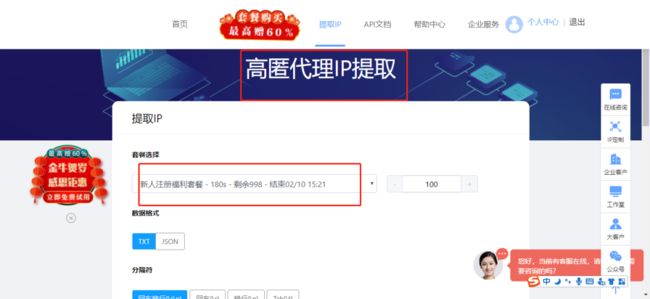
注册之后,可以免费获取1000个IP代理(详细过程就不介绍了,重点如何使用IP代理解决反爬问题~)
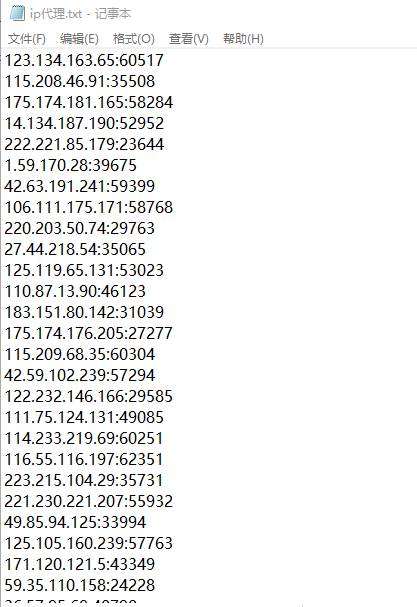
这样我们就可以将提取的IP代理放到文本文件中。
设置IP代理
读取IP代理
iplist=[]
with open("ip代理.txt") as f:
iplist = f.readlines()
刚刚已经将ip全部保存到文本文件中,现在读取出来放到iplist中
随机抽取IP代理
#获取ip代理
def getip():
proxy= iplist[random.randint(0,len(iplist)-1)]
proxy = proxy.replace("\n","")
proxies={
'http':'http://'+str(proxy),
#'https':'https://'+str(proxy),
}
return proxies
通过random函数,可以在iplist 代理集合中,随机抽取IP代理,并封装成proxies格式(requests的ip代理规定格式)
注解:这里https被注释掉了,因为我这里的ip代理是http,所以有https的话则报错!
IP代理代码
headers = {
'Host':'movie.douban.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'cookie':'bid=uVCOdCZRTrM; douban-fav-remind=1; __utmz=30149280.1603808051.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __gads=ID=7ca757265e2366c5-22ded2176ac40059:T=1603808052:RT=1603808052:S=ALNI_MYZsGZJ8XXb1oU4zxzpMzGdK61LFA; _pk_ses.100001.4cf6=*; __utma=30149280.1867171825.1603588354.1603808051.1612839506.3; __utmc=30149280; __utmb=223695111.0.10.1612839506; __utma=223695111.788421403.1612839506.1612839506.1612839506.1; __utmz=223695111.1612839506.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=223695111; ap_v=0,6.0; __utmt=1; dbcl2="165593539:LvLaPIrgug0"; ck=ZbYm; push_noty_num=0; push_doumail_num=0; __utmv=30149280.16559; __utmb=30149280.6.10.1612839506; _pk_id.100001.4cf6=e2e8bde436a03ad7.1612839506.1.1612842801.1612839506.',
'accept': 'image/avif,image/webp,image/apng,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'upgrade-insecure-requests': '1',
#'referer':'',
}
url = "https://movie.douban.com/subject/24733428/reviews?start=0"
r = requests.get(url, proxies=getip(), headers=headers, verify=False)
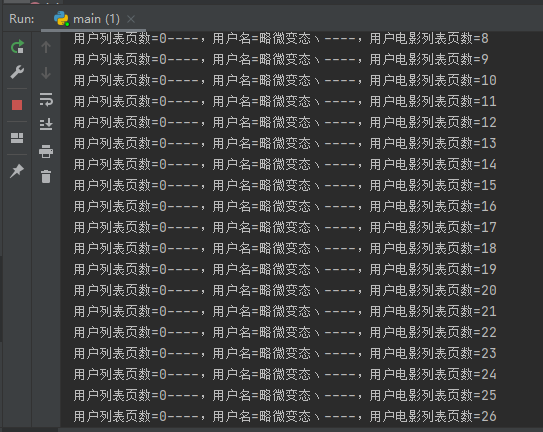
加了IP代理之后,爬取了几百页也没有遇到过验证问题。轻松爬取万级别的数据没问题。
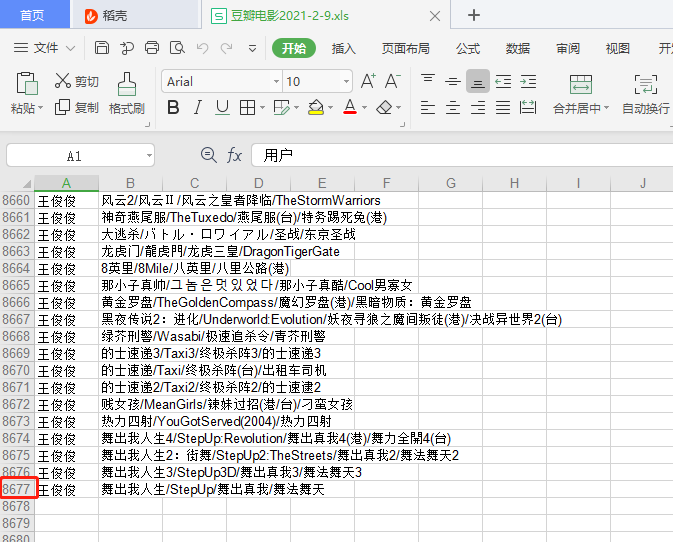
已经爬取了8677条数据,一直没有验证出现,程序还在继续运行~~~
时间间隔
如果还是遇到验证机制,可以添加时间间隔,在爬取每一页的时候,先让程序暂停几秒(自定义)
time.sleep(random.randint(3,5))
random.randint(3,5)是随机生成3~5之间的数字,因此程序在爬取一次后就随机暂停3~5秒。这样也是一个有效防止触发反爬机制。
04
总结
讲解了通过IP代理和时间间隔去解决反爬验证问题
白嫖可用的IP代理
爬取好的数据将会进一步分析和挖掘,本文就讲解如何解决爬虫的反爬问题(毕竟大家时间宝贵,都是碎片化阅读,一下子太多内容难易消化)。
如果你觉得文章还不错,请大家点赞、分享、留言,因为这将是我持续输出更多优质文章的最强动力!
【各种开源源码获取方式】
识别文末二维码,回复:开源源码
------------- 推荐文章 -------------
1.python爬取淘宝全部『螺蛳粉』数据,看看你真的了解螺蛳粉吗?
2.爬取淘宝热卖商品并可视化分析,看看大家都喜欢买什么!
3.python窃取摄像头照片(摄像头拍照+邮箱发送+打包exe)
4.王者荣耀白晶晶皮肤1小时销量突破千万!分析网友评论我发现了原因
