咖啡汪日志——遇见数仓,理想与现实的碰撞,前景与难点的对接
嗷呜!
作为不是在戏精,就是在戏精的路上的二哈
本汪最近又搞到了新玩意儿
做数仓,主要用于支撑大数据分析和架构层决策
前言
通过这篇文章,我们能学到什么:
1、了解数仓的前景。
2、了解到数仓前期ETL 所面临的问题。
3、了解到当下市面上常见的金融管理软件,用友、金蝶等进行移库时,数据类型的转换情况。及其软件本身存在的问题所带出的挑战。
4、经济实用的工具软件推荐。
这篇博客为本汪“数仓系列”博客的开篇,后期本汪会随着项目的推进,为大家带来更多实际研发过程中碰到的问题及解决方案。
一、前景
城市数字化转型,首当其冲的,便是要实现数据富足
2020.12.26 日,在江苏南京举办的,第二届全国中台战略大会暨第四届互联网构架峰会,本汪当时也是有幸参会,收获了不少前沿信息,嗷呜嗷呜!
另外有需要当时会议内部资料的,可以留言哦!
珍贵的历史照片,如下:


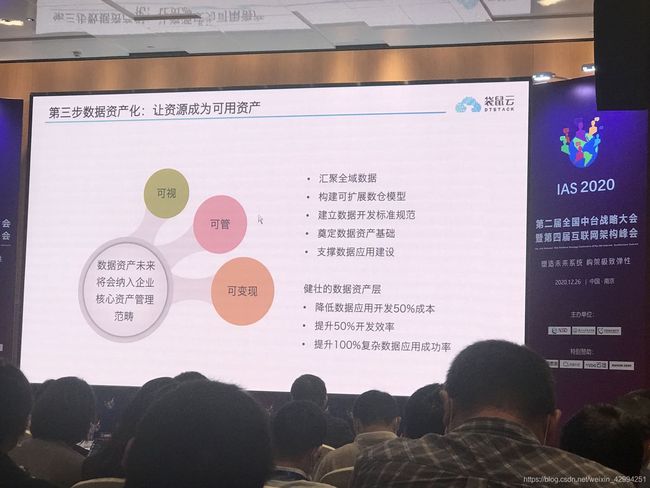

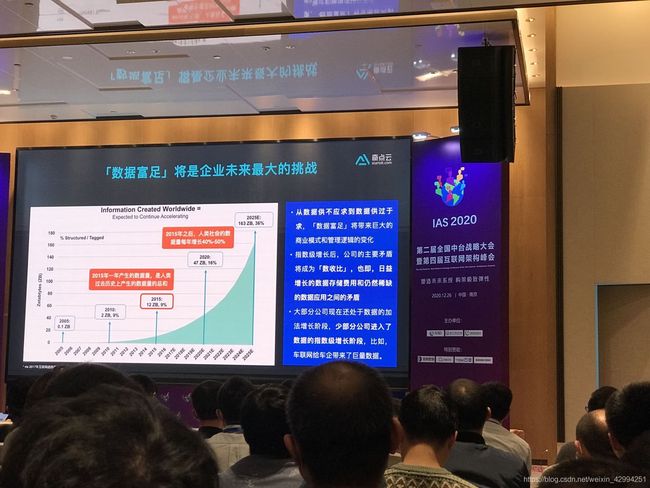
会议中,提到的数仓的使用场景:
1、边境缉毒:利用监控设备对毒贩常开车辆进行数据采集,之后根据地区、团伙大小进行数据模型的建立。结合算法,对符合条件的车辆进行预警标识,从而提醒边防武警进行重点检查,大大提高了云南等边境地区的贩毒打击效率。
2、智慧城市:按网格划分,对城市的各个区域,各项数据进行多维度展示和监控,从而提前预警,实时反馈,为城市的宏观调控提供数据支撑。
3、促进企业的数字化转型:大多数企业可能已经拥有了大量的业务数据,但是有数据并不代表已经实现了数据富足。数据富足,是指按照业务逻辑,将有效数据按不同维度进行整合,从而有效为企业的数字化转型提供数据依据。
—————————————————————————————
二、开篇有益:
1、OLTP 和 OLAP 的区别
这两种其实我们平时工作中,都是有处理过的。业务通常由 OLTP 支撑,而现下最火的大屏展示,则大多由 OLAP 支撑。
OLTP:On-Line Transaction Processing,联机事务处理,主要是业务数据,需要考虑高并发和事务
OLAP:On-Line Analytical Processing,联机分析处理,重点主要是面向分析,通常都是大量的多维度查询,很少涉及增删改。
OLAP 通常是以多维数据模型为实现基础,为了满足用户从多角度多层次进行数据查询和分析,而建立起的基于事实和维度的,数据库模型事务处理机制。而数仓通常以 OLAP 为主。
本汪手上这个活儿,就是根据业务情况,构建合适的数据模型,自然也包括实现底层数据的 ETL 和迭代整合。
2、常见的传统数据库
关系型以 Mysql 、 Oracle 、Sql Server、ACCESS、Sybase为主,非关系型以 MongoDB 为主。
有什么说什么,到目前为止,这几个是本汪用的最多的,其他的没怎么用过。
二、 理想是美好的,现实是残酷的,仅前期 ETL 就已经难点重重
1、前期基础数据 ETL
1.1 、目标:
数据拉取与整合,以 Mysql 、 Oracle 、Sql Server、ACCESS、Sybase等 为数据源,目标数据库为 Mysql, 实现 5k 张表以上的金融数据,倒库入 Mysql。
1.2 、主要难点:
(1)财务软件种类多:需要对95家企业的财务系统数据进行分析,对接的财务软件不统一、数据结构不明确且涉及表量大,需要结合实际项目需求不断整理。
(2)数据量大:各家财务系统数据存储量大,为达到数据快速存取,数据表需分区分表,合理设计表结构及表关系。
(3)数据表结构不同:各企业财务系统数据库表结构、表关系不同,需要大量时间整理不同系统之间关系。
(4)更新频繁:进行常量表的全量抽取,为保证数据及时更新,需频繁抽取更新数据,涉及数据表种类繁多,任务量大。
(5)数据类型转换:需整理不同数据库之间的数据类型,将不同数据类型转换为同一数据类型,存储到中间数据库,为其他平台存取数据提供基础。
(6)历史数据更新:数据表内没有明显的数据更新标识,需要长期与各企业财务人员保持联系,当企业修改历史数据时,及时进行系统数据更新维护。
1.3、经济实用的工具软件:
(1)ETL 使用开源的 kettle8.3 加以二次开发 (具体执行策略和实际操作,会在后续博客中推出。),kettle 的中文官网。
(2)数据库管理工具: Navicat
(3)数据库表结构倒库工具:SQLyog 8.32破解版(百度云盘:链接:https://pan.baidu.com/s/1N4rvYCP_xLCMwIUqzHsHAw
提取码:8668
复制这段内容后打开百度网盘手机App,操作更方便哦)
SQLyog 8.32 的使用教程
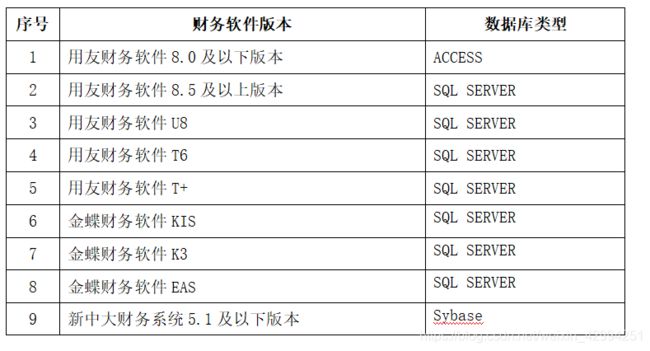
1.4、常见的财务软件及数据库类型如下
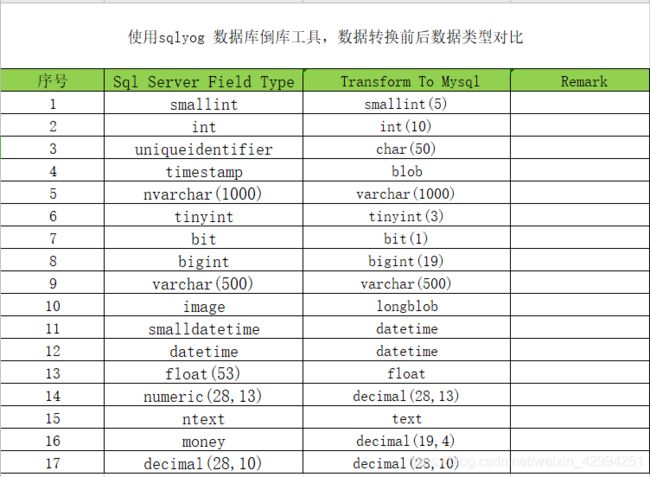
1.5、以金蝶为例,SQL SERVER中数据类型与 Mysql 中数据类型的对应关系:
1.6、当下预计会采取的抽取策略:
以最难处理的表为例:
由于数据量过大,类似 balance 这样的收支平衡记录表,基本数据量都在百万以上,并且只有年区间 year 和会计区间 period 作为标识,并没有任何自增字段,抽取难度极大。实际案例数据高度机密,无法为大家展示。
实际执行步骤:
-
按照业务需求,进行展示维度的划分
-
根据业务需求建立数据模型
-
重新构建全新的数据库表结构
-
按照年份和会计区间进行分库分表
(按年份进行垂直分表,因为历史数据的更新概率远低于近3年的数据,所以将2009 - 2018年的数据单独存放,2019 - 2021年的数据单独存放,另外可根据需求,按照会计区间进行二次拆分。 ) -
根据需求,合理选取抽取策略。
1、近3年数据,每日一次增量抽取(只处理新增数据,不处理更新数据),每星期统一处理一次全部数据(包括新增和更新)。
2、对于陈年数据,每次增量都压力山大。我们知道从机械磁盘顺序读取1M数据理论上用时2毫秒,分时段更新后,每次更新至少也得64G的数据,理论用时(64 * 1024)* 2 /1000 = 131.072s ,但是实际去操作的时候,就直接呵呵呵了,kettle的配置,kettle 进行ETL 转换的效率,服务器 配置等影响巨大,可能会使得一次更新的时间在10分钟开外,这是不被允许的。所以只能联系软件方进行报备,按月定点更新。
由于项目进度的限制,目前仅仅碰到了上面的这些问题,大家有好的执行策略,或对数仓有独到的见解,也欢迎在评论区留言讨论哦!