pointnet++ pointnet2代码运行 保姆级教程
文章目录
- 前言
- 服务器环境
- 项目文件和数据集准备
-
- 下载项目文件
- 下载数据集
-
- 方式一
- 方式二
- 修改项目文件
-
- 解压数据集
- 修改多显卡训练文件train_multi_gpu.py
- 修改编译文件
- 运行
-
- 上传到服务器
- 编译
- 运行
前言
应导师的要求, 去下载了pointconv的代码准备跑一遍, 结果发现需要先按照pointnet++的代码去编译几个自定义的运算tf_op,而且pointconv需要用到的scannet数据高达1.3TB, 直接劝退, 改跑pointnet2(即pointnet++)
几个注意点:
- 我选择的是
tensorflow版的pointnet2代码 - 建议在
tensorflow1.4以上版本中运行, 但是不能选择tensorflow2版本 - 建议
g++5.4.0版本 - 建议
python2.7版本 - 我是在
modelnet40_normal_resampled数据集上训练的 - 建议在多显卡或者高显存(24G以上)的显卡上训练, 不然一直OOM爆显存
服务器环境
这里我选择的是tensorflow版本的pointnet2代码, 听我同学说有torch版的.
- anaconda3
- python虚拟环境python2.7
- cuda10.1
- g++ 5.4.0
- Tensorflow-gpu 1.11.0
- 3 x GTX TITAN X
项目文件和数据集准备
这里我推荐各位先将项目文件和数据集下载到自己电脑本地, 修改完之后再通过scp命令上传到服务器, 因为本地修改起来会比较方便, 像我这种纯靠终端ssh去控制服务器的…那么多文件一个一个vim来修改也太折磨人了
下载项目文件
这里首先需要git环境, 进入桌面后运行git clone https://github.com/charlesq34/pointnet2.git
下载完了之后桌面会多出来pointnet2这么个文件夹. 里面的文件我就不一一展示了, 实在太多, 所有的文件夹如下:
pointnet2/
├── data
├── doc
├── models
├── part_seg
├── scannet
│ └── preprocessing
├── tf_ops
│ ├── 3d_interpolation
│ ├── grouping
│ │ └── test
│ └── sampling
└── utils
下载数据集
方式一
点击这个url链接https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip
方式二
终端运行wget https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip --no-check-certificate 后面的--no-check-certificate不可少, 不然会报下面的错误:

修改项目文件
解压数据集
将下载好的modelnet40_normal_resampled.zip文件解压到pointnet2/data/路径下
解压完之后, 整个pointnet2/data文件夹的路径树如下:
data
├── modelnet40_normal_resampled // 这里面存放的完整的数据集, 这里就不展示了
├── modelnet40_normal_resampled.zip
└── README.md
修改多显卡训练文件train_multi_gpu.py
如果你在单显卡上训练, 请修改train.py,修改内容是一样的, 只是具体所在行数可能不一样. 但是请保证你的显卡显存足够(最好在24G以上), 因为我这里即便是3张TITAN X, 33G的显存, 当我batch_size给到18就开始爆显存了.
在pointnet2/根目录找到这个文件, 然后打开, 修改下面几个地方(具体在第几行可能不同, 因为我这里被我改了好几次…)
- 注释掉第25行的
import modelnet_ht_dataset. 由于python是脚本语言, 是从上到下一行一行运行的, 如果不注释掉的话, 会去一个指定的url链接下载modelnet_h5_dataset这个h5格式的数据集. 事实上我们已经下载好数据集了, 再下载也是多余的. - 将76行的
if FLAGS.normal:改为if True:这里是为了保证不会进else分支, 因为else分支是读取h5格式的数据集.
修改编译文件
进入pointnet2/tf_ops/路径, 里面有3个文件夹3d_interpolation,grouping,sampling.
这时候我们需要先连接自己的服务器, 查看这么几个路径
- cuda路径, 默认是在
/usr/local/cuda-${__VERSION__}/,其中${__VERSION__}是你的cuda版本 - tensorflow路径. 这一步细说
先选择装了tensorflow1.X的python解释器(其实Ubuntu自带一个python2.7环境, 可以在这里配置tensorflow1.X环境), 如果是conda配置的虚拟环境, 那么conda acitvate来进入这个虚拟环境
然后运行:
import tensorflow as tf
print(tf.__file__)
输出来的就是你的tensorflow路径
有了这两个路径, 我们分别进入3d_interpolation,grouping,sampling三个文件夹, 分别进行编译, 操作是一样的, 我就拿sampling来举例子.
进入pointnet2/tf_ops/sampling/,发现有一个sh文件tf_sampling_compile.sh,这个脚本就是用来编译的.
为了能够显示全部的内容, 我这里用vim打开:
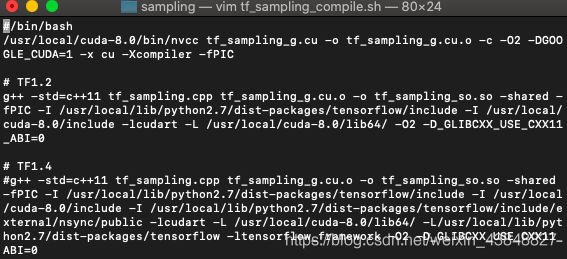
你可以通过sublime, gedit等其他工具打开编辑.
修改这么几个地方
- 如果你的
tensorflow版本在1.2和1.4之间, 那么用#注释掉下面的编译命令, 反过来如果你的tensorflow版本在1.4及以上, 那么注释掉上面的编译命令. 如果你的版本不到1.2, 那么请升级 - 将所有的
/usr/local/cuda-8.0/, 更改为你的/usr/local/cuda-${__VERSION__}/ - 将所有的
/usr/local/lib/python2.7/dist-packages/tensorflow/改为刚刚print(tf.__file__)输出的路径, 注意这是目录, 最后需要加一个/, - 将最后的
-D_GLIBCXX_USE_CXX11_ABI=0的0改为1.不然虽然能通过编译, 但是训练的时候会报错undefined symbol: _ZN10tensorflow8internal21CheckOpMessageBuilder9NewStringEv
我这里修改完是这样的:
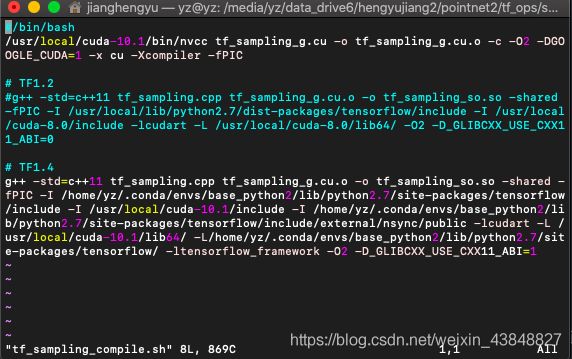
这里改完不要急着编译, 因为我们还没有上传到服务器. 需要在服务器上编译
同理, 修改剩下两个文件夹中的sh文件, 然后保存.
至此, 所有准备工作完成, 下一步就是上传到服务器上然后编译运行了.
运行
上传到服务器
进入pointnet2文件夹所在的根目录, 我这里是Desktop/, 然后通过scp -r pointnet2/ ${__USER__}@${__IP__}:${__PATH__}命令上传到你的服务器.其中:
${__USER__}是用户名${__IP__}是你服务器的公网IP${__PATH__}是你要存放的路径
编译
ssh连接服务器,进入pointnet2/tf_ops/下面的三个文件夹, 分别sh运行那三个sh文件, 如果终端没有任何报错信息, 同时多了一个.o和一个.so.so文件, 那么恭喜你编译成功.
运行
在一张显卡上运行, 请保证显存足够, 并且batch_size尽量给小,如果是conda的虚拟环境, 一样需要先conda activate , 然后在pointnet2/目录下python train.py.
这里我建议在多卡上运行, 但是需要注意, 训练时给的batch_size需要能够被显卡数整除, 不然train_multi_gpus.py里面的一个断言会终止程序.
我这里是在终端运行了CUDA_VISIBLE_DEVICES=0,1,2 python train_multi_gpu.py --num_gpus 3 --batch_size 12 --max_epoch 200, 注意一定要保证batch_size能够被num_gpus整除.
如果在训练过程中报错OOM,说明显存不够用了, 请调小batch_size再试.
最后会在pointnet2/log/里面保存checkpoint.