DataX在数据迁移中的应用
简介: DataX在数据迁移中的应用

1. DataX定义
首先简单介绍下datax是什么。
DataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
2. DataX 商业版本
阿里云DataWorks数据集成是DataX团队在阿里云上的商业化产品,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动能力,以及繁杂业务背景下的数据同步解决方案。目前已经支持云上近3000家客户,单日同步数据超过3万亿条。DataWorks数据集成目前支持离线50+种数据源,可以进行整库迁移、批量上云、增量同步、分库分表等各类同步解决方案。2020年更新实时同步能力,支持10+种数据源的读写任意组合。提供MySQL,Oracle等多种数据源到阿里云MaxCompute,Hologres等大数据引擎的一键全增量同步解决方案。
关于datax的git地址,可参考文后资料了解详情[1]。
2.1 应用案例
接下来介绍下我们在两个项目上的应用案例。
2.1.1 案例一 通过datax协助分析数据同步链路
客户某oracle数据库在迁移上云过程中,使用了某封装好的产品,但是传输效率一直很低,只有6M/s。客户一直怀疑是云内vpc网络瓶颈或rds数据库瓶颈导致,但是实际上,云内网络以及数据库整体处于非常低的负载状态。
由于客户侧的传输工具我们不方便直接拿来测试,所以在ecs上临时部署了datax,来做分析和对照测试;
测试结果如下图所示。

图1:测试结果
常用的优化参数介绍如下:
1.通道(channel)--并发
- 通过测试可知,channel的设置对传输效率的影响较为明显,上述实验中,所有设置为1的,即没有并发的情况下,同步速度均为8.9M/s;将该设置调高之后,速率明显倍增,但增大到一定程度后,瓶颈点就转到其他配置了;
2.切片(splitpk)
Git官方介绍如下:
- 描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,Datax因此会启动并发任务进行数据同步,这样可以大大提高数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错。
如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。 - 必选:否
- 默认值:空
实际上,由测试结果可知,切片是要配合channel来使用的,如果只开了splitpk,但是channel的配置为1,同样不会有并发的效果;
3.Batchsize
Git官方介绍如下:
- 描述:一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
- 必选:否
- 默认值:1024
现场的实际测试效果不明显,主要原因是数据量较小,1c1g配置时,适当提高batch可以提升同步速度。
其他还有很多参数,有待小伙伴们去逐一发掘,或者下次我们用到再给大家分享;
由测试结果可知,项目使用的工具只能同步6m的速率,肯定是远远不足的,性能瓶颈既不在网络上,也不在数据库上,我们只做了部分测试,就发现4c16g的数据库轻轻松松就能达到27M的同步速率。
2.1.2 案例二 datax在数据同步实战中的应用
该案例是客户两朵云之间的数据迁移,客户新建了一朵云,需要把前一朵云上的数据迁移过去;
方案如下:
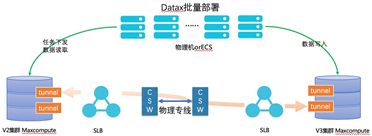
图2:方案
2.2 部署方式
Datax本身无自动集群化部署,需要逐台手工部署;
15台v2的物理机,空余内存均在150G左右。(因为V2集群即将下线,上述产品无业务,所以利用了闲置的物理机,在物理条件不具备时,可以采用ecs或其他虚拟机。)
机器要求:同步任务启动会占用较多内存,测试平均1个任务占用10G内存(大表);
单台150G内存可以支持15个并发任务;
2.3 同步方式
2.3.1 数据特点
| 分类 | 项目数 | 总数据量 |
|---|---|---|
| 1T以上project | 7个 | 97T |
| 1T以下project | 77个 | 15T |
- 历史记录表:历史数据,项目数不多,但占用了80%以上的空间;
- 维表+临时表:项目数多,表较小,占用空间占比小;
- 数据特点:客户几十个部门分析报表,小表分区比较多,大表相对少一些;
2.3.2 同步顺序
先同步大表,然后再同步小表;
业务没有同步顺序要求,小表易变,大表稳定,因此优先同步大表;
大表同步需要的手动配置少,也适合前期做好调试;(正式启动同步前的测试不要选太大的表,建议10G-50G,可以测出效率和压力。)
- 优点:机器多,并发高,可以快速压到瓶颈,提升整体同步效率;
- 缺点:Datax为原生的迁移工具,不具备自动化能力,需要人工大量的配置同步任务;
注:建议预留几台机器专门用于多分区小表的同步,剩余其他机器同步大表。
2.4 总结
综上所述,Datax的优势非常明显:
- 首先,部署非常简单,无论是在物理机上或者虚拟机上,只要网络通畅,便可进行数据同步,给实施人员带来了极大的便利,不受标准数据同步产品部署的条框限制;
- 再者,它是开源产品,几乎没有成本;
但是,它的缺点也是显而易见的:
- 开源工具更多的是提供基础能力,并不具备任务管理,进度跟踪、校验等等一系列的功能,只能使用者自己通过脚本或者表格记录,目前暂无白屏;因此注定了它只能作为临时性质的数据同步工具去使用;
所以,业务上有一些规范化管理或者标准化运维的需求时,或者有频繁的、持续的使用数据同步调度的需求时,安全生产是非常重要的,还是推荐大家使用阿里云官方的产品。z
3. 写在最后
本期给大家介绍了Datax的相关概念,分享了两个案例供大家参考,但是在实际的数据同步过程中仍有非常多的困难和问题,需要对整个数据传输的链路做分析和优化,操作较为繁杂。后续会给大家介绍案例二中的性能瓶颈分析和优化。
作者:陈树昌
原文链接
本文为阿里云原创内容,未经允许不得转载