SIPAKMED数据集论文翻译
SIPAKMED: A NEW DATASET FOR FEATURE AND IMAGE BASED CLASSIFICATION OFNORMAL AND PATHOLOGICAL CERVICAL CELLS IN PAP SMEAR IMAGES
SIPAKMED:基于特征和图像的子宫颈抹片正常和病理宫颈细胞分类的新数据集
目录
- 摘要
- 1.引言
- 2.SIPAKMED数据库
-
- 2.1 正常细胞
-
- 2.1.1 uperficial-Intermediate cells
- 2.1.2 Parabasal cells
- 2.2异常细胞
-
- 2.2.1 巨噬细胞
- 2.2.2 Dyskeratotic cells
- 2.3良性细胞
-
- 2.3.1 Metaplastic cells
- 3.SIPAKMED的评估
-
- 3.1 细胞特征
-
- 3.1.1 支持向量机
- 3.1.2 多层感知器(MLP)
- 3.2 图像特征
-
- 3.2.1 卷积神经网络
- 3.3深度特征
- 4.实验结果
- 5.结论
摘要
巴氏涂片图像中子宫颈细胞的分类是一个具有挑战性的任务,因为这些图像的展现具有局限性以及细胞结构部分形态变化具有复杂性。此过程非常重要,因为它为检测癌变或癌前病变提供了基本信息。为此,已经提出了几种算法,以对这种图像中的正常和异常细胞进行分类。但是,每个研究小组通常都会创建自己的图像数据集,这是一种普遍现象,因为构建良好的数据集未公开。为了克服这一障碍并协助该领域的研究进展,我们提供了带标记的巴氏涂片图像数据库,其中根据细胞的形态特征将细胞分为五类。专家手动定义每个图像中的细胞质和细胞核面积,并针对每个感兴趣区域计算强度,纹理和形状的显着特征。已经对这些图像的分类进行了一些实验,其中包括基于特征和基于图像的分类方案。在这个方向上,测试了基于支持向量机和深度神经网络的方法,并提出了每个分类器的性能,以构成评估未来分类技术的参考点。
关键词——巴氏涂片图像,子宫颈类细胞分类,细胞图像数据库,细胞特征,卷积神经网络
1.引言
巴氏涂片图像的自动解释是细胞学图像分析中最有趣的领域之一。这是一个至关重要的问题,它结合了数字图像处理的多个方面,例如图像增强,伪影限制,对象分割,重叠单元格的描绘等。为了自动检测这些图像中的感兴趣区域,已经做出了很多努力,并且它们包括几种技术[1,2,3]。
另外,集成的巴氏涂片图像分析包括基于图像特征的图像分类。巴氏涂片图像中宫颈鳞状细胞的细胞形态学分类对于准确诊断和检测癌性或癌前病变非常重要。通常,为这些图像的自动分类建议的方法需要单个细胞的图像,这些图像是从细胞簇中裁剪出来并进行进一步分析的[4,5]。据我们所知,包含单个细胞图像的唯一可用数据集是Harlev数据集[6],该数据集由有限数量(917)的图像组成。因此,一些研究人员创建了自己的带标记的图像数据集,以评估其方法的性能。但是,这些存在的、非公共的特定数据集的主要缺点是:它们是在单个数据集中进行评估的,难以比较不同分类技术的效率。
在本文中,我们介绍了新颖的公开可用的图像数据集SIPaKMeD,它由4049个带标注的细胞图像组成。根据细胞的细胞外观和形态,专家细胞病理学家将细胞分为五类。更具体地说,正常细胞分为两类(superficial-intermediate, parabasal)),异常但非恶性细胞分为两类(ilocytes and dyskeratotic),还有一类良性(间质性)细胞。我们数据库的每个图像,细胞质区域和细胞核都是手动标记的。在每个感兴趣的区域中,都会计算26个特征,以表征感兴趣区域的强度,纹理和形状。最后,我们使用基于特征和图像的分类方案提供评估结果,并对每个分类器的判别能力进行了一些说明。
2.SIPAKMED数据库
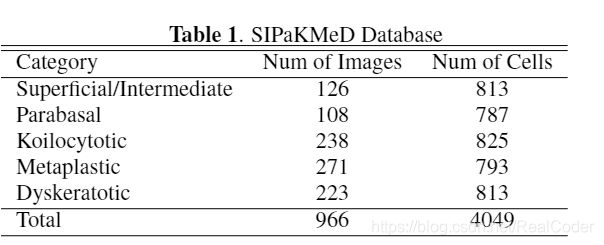
SIPaKMeD数据库由4049个分离的细胞图像(图1)组成,这些图像是从966个巴氏涂片的簇细胞图像中手动裁剪的,当然这些图像也包括在内。这些图像是通过适用于光学显微镜(OLYMPUS BX53F)的CCD相机(Infinity 1 Lumenera)获得的。表1中描述了类中各个单元的分配。在以下段落中,提供了每个类的简要说明。
2.1 正常细胞
这些是鳞状上皮细胞,其类型根据其在上皮层的位置及其成熟程度来定义。
2.1.1 uperficial-Intermediate cells
它们构成了巴氏试验中发现的大多数细胞。通常它们是扁平的,具有圆形,椭圆形或多边形形状(图1(a))。
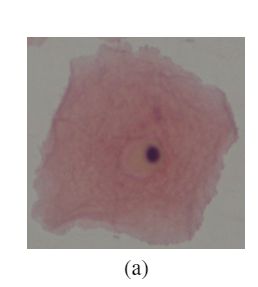
细胞质染色多为嗜酸性或嗜氰。它们包含一个中央的脓性核。它们具有定义明确的大型多边形细胞质,并且易于识别的核限制(浅表小囊泡和中间细胞的囊泡核)。这些类型的细胞由于更严重的脱落而表现出特征性的形态变化(koilocytic atypia))。
2.1.2 Parabasal cells
Parabasal cells是不成熟的鳞状细胞,是典型的阴道涂片中观察到的最小的上皮细胞(图1(b))。

细胞质通常是嗜蓝的,它们通常包含一个大的囊泡核。必须注意的是,Parabasal cells具有与被鉴定为化生细胞的细胞相似的形态学特征,并且很难与它们区分开。
2.2异常细胞
异常细胞的特征在于其结构部分的形态变化,并表明存在病理情况。人乳头瘤病毒(HPV)是几乎所有宫颈癌病例的病因,其特征在于鳞状细胞的特征性变化,其中两种是致病性的:白细胞增多和角化不全。
2.2.1 巨噬细胞
在成熟的鳞状细胞(中层和浅层)中,最常见的是巨噬细胞,在化生型的巨噬细胞中有时也相对应(图1(c))。
它们最常表现出嗜蓝的,非常浅的染色,特征在于大的核周腔。细胞质的外围染色非常浓密。巨噬细胞的细胞核通常是扩大的,偏心的,彩色的,并显示出核膜轮廓的不规则性。在许多情况下,存在双核和/或多核细胞。巨噬细胞是HPV感染的致病原细胞,并且根据感染的不同阶段以及不同病毒类型的感染,巨吞细胞的核通常显示出不同程度的变性。
2.2.2 Dyskeratotic cells
Dyskeratotic cells是鳞状细胞,在单个细胞内或更常在三维簇中经历过早的异常角质化(图1(d))。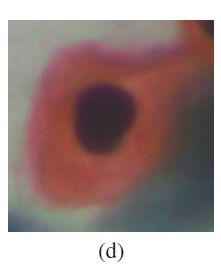
它们有灿烂的嗜橘细胞质。它们的特征是存在囊泡核,与巨噬细胞核相同。它们构成了HPV感染的显着特征,有时甚至在完全不存在红细胞的情况下,也可以作为病理诊断的证据。它们通常是浓密的三维簇,很难区分细胞核或细胞质边缘。
2.3良性细胞
这些细胞代表转化区,几乎所有子宫颈癌前病变和癌性病变都会在该区域发生。
2.3.1 Metaplastic cells
Metaplastic cells本质上是具有明显细胞边界的小型或大型旁基底型细胞,通常表现出偏心核,有时还包含较大的细胞内液泡(图1(e))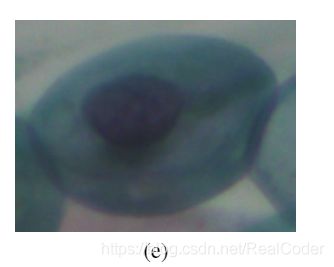
中心部分的染色通常是浅棕色,通常与边缘部分不同。而且,本质上存在深色的细胞质,与Parabasal cells相比,它们的大小和形状均具有很大的一致性,因为它们的特征是细胞质定义明确,几乎呈圆形。它们在巴氏检测中的存在与癌前病变(HSIL)的更高检出率相关。
3.SIPAKMED的评估
我们已经在SIPaKMeD数据库上测试了几种分类方案,以便评估它们在区分各种细胞类型方面的性能。此外,我们使用了三种不同的特征集,即细胞特征,图像像素特征和深层特征。我们遵循5倍交叉验证方案,并且在所有实验中使用相同的训练和测试集以确保结果的一致性。在以下段落中,提供了每个分类方案的详细描述。
3.1 细胞特征
在我们数据库的每个图像中,目标区域的边界(即细胞质和细胞核的面积)由专家观察员手动标注。为孤立的细胞图像和细胞团簇图像提供了每个区域轮廓的坐标(图2)。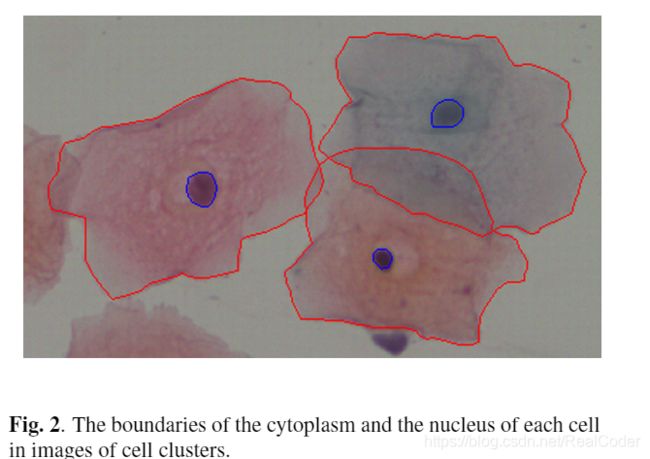
在每个感兴趣的区域中,我们计算所有三个颜色通道中的强度(平均强度,平均对比度)和纹理(平滑度,均匀性,三次矩,熵)的26个特征。此外,还计算了每个区域的一些形状特征(区域,长轴和短轴长度,偏心距,方向,等效直径,坚固性和范围)。计算每个细胞核区域和细胞质的这些特征,并将它们存储在28列的5张表(每类一个)中(两个添加的字段分别表示图像和细胞的数量)。这些功能用于通过支持向量机(SVM)和标准多层感知器(MLP)对细胞进行分类,如以下各段所述。
3.1.1 支持向量机
在我们的实验中,使用了带有径向基函数(RBF)核的SVM分类器。我们测试了参数C(0:05,0:1,0:5,1,2,5,10,15,20,40)和(1,2,4,8,10,15, 20,30,40,50),我们使用了5倍交叉验证方案来选择最佳参数。此外,我们进行了两个实验,使用从细胞核中提取的特征和从细胞质中提取的特征作为输入。由于SVM最初将两类分开,因此我们采用了一对一的方法,并将5类问题分解为10个成对问题。将每个分类器应用于测试模式将对获胜的类别投票一次,然后将测试模式标记给得票最多的类别。
3.1.2 多层感知器(MLP)
使用与上述相同的训练和测试集配置来使用多层感知器。就层可变性而言,MLP是最简单的神经网络类,仅包括完全连接的隐藏层。我们已经测试了几种不同的网络体系结构,并通过对体系结构参数进行交叉验证来选择最佳的网络体系结构。特别是,我们测试了不同数量的隐藏层(1-10)和几个隐藏神经元(10,20,30,40,50)。在所有情况下,我们都将所有隐藏层设置为相同数量的神经元。选择双曲线正切S型函数作为所有层的激活函数,最后一层使用5类softmax函数。最后的softmax激活层的大小为5,以适合5种可能的细胞病理学/类型的当前问题要求。(softmax)输出是一个概率向量,表示输入单元格具有给定单元格类型的概率。关于我们的体系结构交叉验证设置,我们已将训练集的10%用于验证集的构建。使用比例共轭梯度法对模型进行训练,但存在交叉熵分类损失。验证错误增加30个周期后,训练将终止。
3.2 图像特征
3.2.1 卷积神经网络
我们使用卷积神经网络(CNN)进行了分类测试。网络的输入是裁剪后的细胞图像,将其调整为固定大小(在我们的示例中为每个80×80像素)。因此,不需要特征提取步骤-CNN将在给定原始输入RGB值的情况下自动学习合适的内部表示。我们针对当前问题采用了Krizhevsky等[7]的“非常深”架构(VGG-19)。在所采用的体系结构中,输入由一系列卷积层的堆栈进行转换,这些卷积层的顶部是最大池化层。所有卷积滤波器的大小均为3×3,所有最大池化层的大小均为2×2。共有5个卷积堆栈。前两个卷积堆栈分别由2个卷积层组成,其他3个堆栈分别由4个卷积层组成。每个堆栈中的卷积层的深度(即,过滤器的数量)分别为64,128,256,512,512。卷积堆栈之后是一系列完全连接的层,总共3个。全连接层的大小分别为4096、4096、5。为了提高网络的通用性,在前两个完全连接的层上使用了dropout,保持概率为50%。除最后一层外,所有层均使用ReLU激活。就像标准MLP体系结构(第3.1.2节)一样,最后一层使用5级softmax激活。同样遵循标准实践,我们使用交叉熵损失训练模型。
由于训练集的大小相对较小,尤其是对于深度神经网络的需求,我们采用数据增强技术人为地创建了较大的训练集。因此,我们通过为每个现有的训练细胞图像创建3个其他细胞图像来扩充训练集。为此,我们可以水平,垂直或双向翻转输入图像。通过这种方式,我们有效地将训练集的大小增加了三倍。
随机梯度下降(SGD)优化器用于训练模型(批量大小为50,学习率为10 4)。从训练集中随机选择每个训练批次。 200000次迭代后终止训练。
3.3深度特征
我们还使用卷积网络作为其作为softmax分类器的标准替代方式来使用。遵循最近的工作趋势,我们将网络用作特征提取器[8、9、10、11、12、13]。通过向神经网络提供输入图像并使用中间层激活或预激活来构建特征向量,可以将其用作特征提取器。以这种方式产生的特征通常被称为深度特征。这项技术的基本原理是可以看到神经网络是一台自动学习最合适的数据表示的机器[14]。此外,众所周知,深层特征具有更抽象的特征,可赋予更多可转移特征。对于基于更接近输入的图层的深层特征尤其如此[13]。在给定标准的全连接层[8]或卷积层[10、13]的情况下,已经产生了深层特征。在完全连接的层的情况下,特征是M大小的向量,其中M是指定层中神经元的数量。关于卷积层,特征构建是一个两步过程[10,11]。层激活通常是H×W×D张量,其中H,W,D是当前卷积层的高度,宽度和深度。通常,H和W与原始图像的高度和宽度不同,因为最大池化或跨步卷积层(或等效于此效果的层)可能位于输入层和当前层之间,从而生成原始采样的经过滤波的子版本输入。H×W×D层输出可以看作是大小D的H×W个向量的集合。然后可以将这些向量聚合以形成单个向量。通过简单的总池聚合已显示出非常有用的功能[10]。
在当前情况下,我们使用训练的模型通过使用最后一个卷积层(层conv5)的预激活来产生深度特征,如[10]中所建议。然后通过求和池将它们汇总,以形成大小为512的特征向量,以描述每个细胞图像。我们还使用了第一个完全连接的层(fc 6层)的预激活,像[8]那样。这些特征的大小等于相应层中神经元的数量,即4096。在这两种情况下,我们都使用PCA将提取的深度特征压缩为256。然后将特征输入到SVM中,并使用前面描述的投票方案(3.1.1节)计算类别估计。
4.实验结果
我们已经在数据库上测试了提出的分类方法,分类结果包含在表2中。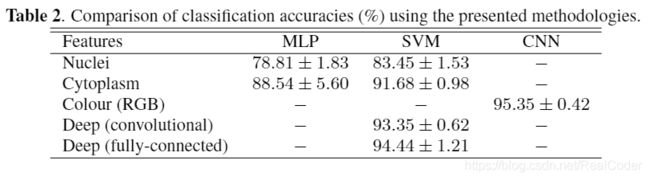
给出了5次训练测试的平均/标准偏差准确度值。同样,在图3、4、5中,我们给出了所有采用的分类器的混淆矩阵。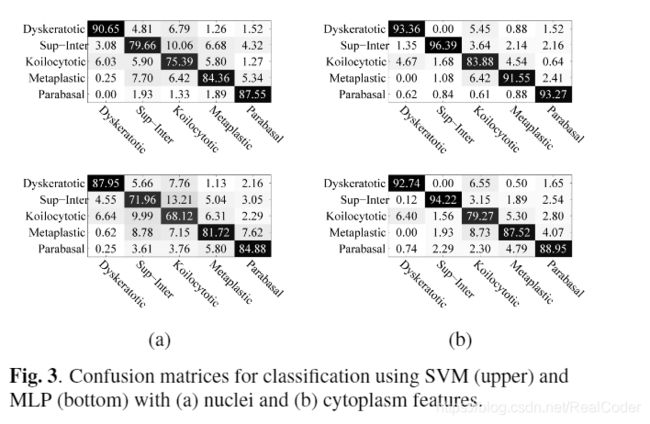
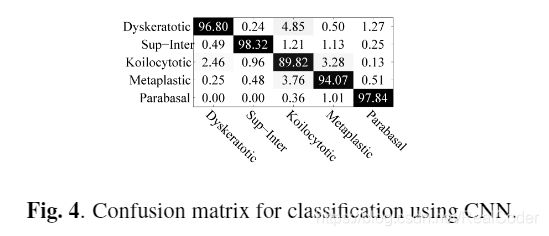
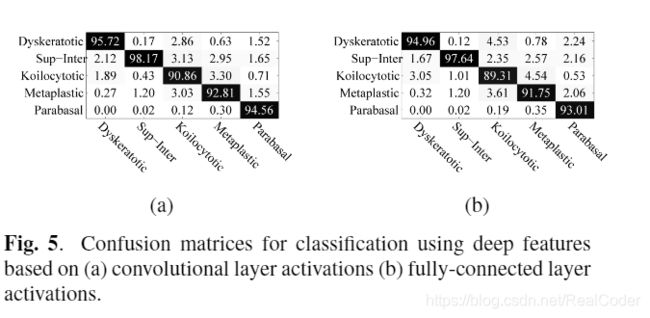
正如我们所看到的,在所有情况下,巨噬细胞都是最具挑战性的细胞,需要正确区分。关于采用手工标记的细胞质和细胞核特征的方法,可以观察到,SVM分类器通常比MLP分类器更有效。我们还可以观察到,胞质特征比核特征具有更高的判别能力。但是,基于卷积神经网络的方法优于基于手工特征的方法。标准的CNN设置可提供最佳的平均性能,并使用紧随其后的深层功能计算性能。
5.结论
本文介绍了公开可用的SIPaKMeD细胞图像数据库。它包含从巴氏涂片中获取的分离细胞图像和细胞团图像。图像分为五类:sup
erficial-intermediate,parabasal,koilocytotic, 巨噬,metaplastic 细胞。每个带标记的细胞的细胞质和细胞核面积由专家观察员手动识别,并且还包括其边界的坐标。我们的数据库的每种模式提供了三种不同类型的特征:人工制作的细胞特征,图像特征,深度特征。在我们的实验中使用的分类方案的结果为评估将来的细胞图像分类技术提供了参考。该数据库不仅可用于分类目的,而且还可用于评估孤立细胞(裁剪图像)或重叠细胞(细胞簇图像)的图像分割技术,因为每个图像中最感兴趣区域已被标记。因此,SIPaKMeD数据库提出了新的挑战,它为细胞图像分析界的竞争性评估奠定了坚实的基础。