EM最大期望算法(Expectation Maximization)
译者按:本文来自于吴恩达的斯坦福经典课程CS229 的课程笔记,也是国内大部分EM算法文章的参考源,本文详细介绍了EM的推导过程,要深入了解EM算法不可不读。期望最大化(Expectation Maximization) 算法被称为机器学习十大算法之一,最初是由Ceppellini等人1950 年在讨论基因频率的估计的时候提出的。后来又被Hartley 和Baum 等人发展的更加广泛。目前引用的较多的是1977 年Dempster等人的工作。它主要用于从不完整的数据中计算最大似然估计。 这个算法是目前隐马尔科夫(HMM)、聚类方面的基础,广泛应用于自然语言处理等方面。
EM算法
在前面的一组笔记中,我们讨论了适用的EM算法混合着高斯分布。 在这套笔记中,我们给出了更广泛的观点的EM算法,并展示它如何应用于一个大的估计潜在变量的问题系列。 我们从一个称为Jensen不等式的非常有用的结果开始讨论。
1、Jensen不等式
设f是一个函数,其域是实数集合。 回想一下,f是一个凸函数,如果f ''(x)>= 0(x ∈ R)。 在f服用的情况下
矢量值输入,这被推广到它的黑森州H的条件是半正定的(H≥0)。 如果所有x的f ‘’(x)> 0,那么我们说f是严格凸(在向量值情况下,相应的语句是H必须是严格半正定的,写成H> 0)。Jensen不等式可以说明如下:
定理: 令f是一个凸函数,并且令X是一个随机变量。

而且,如果f是严格凸的,那么如果和,E [f(X)] = f(EX)成立 仅当X = E [X]具有概率1时(即,如果X是常数)。回想一下在编写期望时偶尔放弃括号的惯例,所以在上面的定理中,f(EX)= f(E [X])。有关该定理的解释,请考虑下图。

这里,f是实线所示的凸函数。 另外,X是一个随机数变量,有0.5的机会取值a和0.5的机会取值b(在x轴上指示)。
因此,X的期望值由a和b之间的中点给出。
我们还可以看到在y轴上显示的值f(a),f(b)和f(E [X])。此外,值E [f(X)]现在是f(a)之间的y轴上的中点,
和f(b)。 从我们的例子中,我们看到,因为f是凸的,所以它必须是E [f(X)] >= F(EX)。
顺便提一句,很多人都无法记住哪种方式不等式就会发生,记住这样的一张图片是一个迅速找出答案的好方法
备注。 回想一下,当且仅当f 严格凸(即,f''(x)≥0或H≥0)。 詹森的不平等也适用于凹函数f,但所有不等式的
方向相反(E [f(X)]≤ f(EX)等)。
2 The EM 算法
假设我们有一个估计问题,我们有一个训练集 {X(1).....x(m)} 由m个独立的例子组成。 我们希望这个
数据模型p(x; z)的参数,其中的可能性是由

但是,明确地确定参数的最大似然估计值θ可能很难。 这里,z(i)是潜在的随机变量; 而且经常这样:
如果z(i)被观察到,那么最大似然估计会很容易。
在这样的设置中,EM算法给出了一个有效的方法,最小似然估计。 明确地最大化 ι(θ)可能会很困难,
而我们的策略将是反复地在ι上建立一个下界(E-步骤),然后优化该下限(M步骤)。
对于每个i,让Qi在z上有一些分布(Pz Qi(z)= 1,Qi(z)≥0)。 考虑以下几点:

这个推导的最后一步使用了Jensen的不等式。 具体而言,f(x)=log x是一个凹函数,因为其域x ∈ R +上的f''(x)=1= x2 <0。另外,这个词
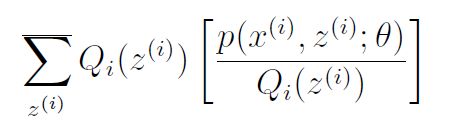
(x(i); z(i);?)= Qi(z(i))?????????? 关于z(i)根据Qi给出的分布绘制。 通过Jensen的不等式,我们有

\ z(i)? 上面的“齐”下标表示期望值关于z(i)取自齐。 这使我们可以从方程(2)到公式(3)。现在,对于任何一组分布Qi,公式(3)给出了一个下界在'(?)上。 齐的有许多可能的选择。 我们应该怎样选择? 那么,如果我们有一些目前的猜测? 的参数,试图在低于这个价值的情况下使下限紧张是很自然的。 即,我们会的使以上的不平等符合我们特定的价值。(我们稍后会看到这是如何使我们证明 ι(θ)单调增加的与EM的成功迭代。)
为了使边界对于某个特定的值更紧密,我们需要这个步骤涉及Jensen的不平等在我们上面的推导中要保持平等。
为了实现这一点,我们知道期望值是足够的在一个\常数“ - 值得随机变量上,即我们需要这个

对于一些不依赖于z(i)的常数c。 这很容易完成通过选择
实际上,因为我们知道Pz Qi(z(i))= 1(因为它是一个分布),所以进一步告诉我们

因此,我们简单地将Qi设置为z(i)的后验分布给定x(i)和参数?的设置。现在,对于Qi的这个选择,方程(3)给出了一个下界我们试图最大化的对数似然性。 这是E步骤。 在里面算法的M步,然后我们最大化公式(3)中的公式尊重参数以获得?的新设置。 反复执行这两个步骤给了我们EM算法,如下所示:

我们如何知道这个算法是否会收敛? 那么,假设?(t)和Δ(t + 1)是来自EM的两次连续迭代的参数。 我们会
现在证明`(?(t))? `(?(t + 1)),它表示EM总是单调的提高了对数似然。 展示这一结果的关键在于我们的选择
齐的。 具体而言,在参数所具有的EM的迭代中开始为?(t),我们将选择Q(t)i(z(i)):= p(z(i)jx(i);?(t))。 我们之前看到,这种选择确保了Jensen的不平等,就像应用于获得等式(3)持有平等,因此
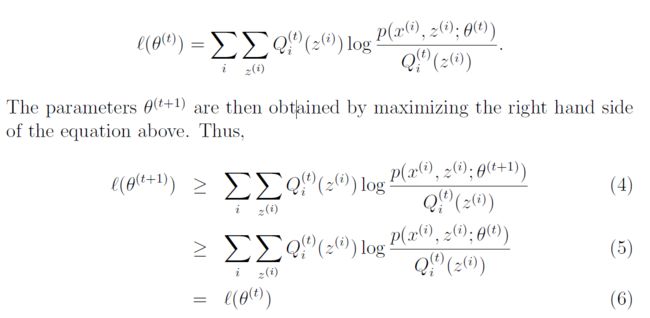
这第一个不平等来自于这个事实
适用于任何Qi和?的值,特别适用于Qi = Q(t)一世 ,? =?(t + 1)。 为了得到方程(5),我们使用了选择?(t + 1)的事实明确地是之前看到,这种选择确保了Jensen的不平等