判别器loss为0_线性回归的numpy、tf2.0、keras实现

本文首先介绍线性回归的数学原理,然后用numpy、TensorFlow2.0、keras等多种方式实现一元线性回归。
线性回归的数学原理
机器学习问题可以分为回归问题和分类问题,而线性回归是最基础的回归问题。线性回归就是要用如下公式拟合训练数据:
其中a和b是待解的参数。如果a是一个标量则叫做一元线性回归,如果a是一个向量则叫多元线性回归,为方便解释本文以一元线性回归为例。
假设我们有一组关于
这不就是一元二次方程么,公式中有a, b两个变量用两个方程组合就能求解,上面写四个公式还有些多余了,很容易算出a=6,b=1。
对于这种有精确解的数据直接求解线性方程即可,但真实的数据往往会有一些误差无法用线性方程求求解,只能通过其他方式求“近似解”,也就是找到一个误差最小的解。比如下图的这些点近似的分布在一条直线周围,但有没有精确的在这条直线上。
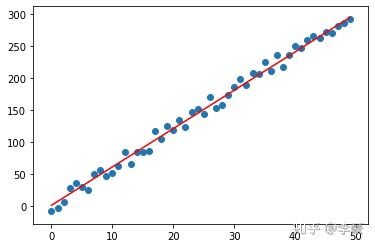
求解线性回归的近似解的关键就在于如何定义”近似“?通常采用均方误差MSE(Mean squared error)来表示误差程度,误差越小越“近似”。
其中
如何通过可迭代的方式找到这个近似解呢?梯度下降算法登场!
高中数学我们知道要求函数的极值,只需找到函数一阶导数为0的地方就行了。所以我们只需要对MSE分别对a和b求偏导并且令倒数为0,求解出a和b即可。但前面已经说过了,对于有误差的数据是无法求精确解的。所以我们采用“梯度下降”算法来求近似解。梯度下降的思路是:不断沿着一阶导数值增加的反方向——就是让梯度下降的方向——就能找到函数的极值点。
上述MSE的定义对参数a求偏导:
同样求出MSE对b的偏导:
则权重a和b的迭代更新方式为:
其中
numpy线性回归
为加深理解,先使用numpy从零实现梯度下降算法来求解线性回归。这里需要用到“自动微分”中的手动求解法,
李豪:Python实现自动微分(Automatic Differentiation)zhuanlan.zhihu.com
既首先在纸上手动算出求导公式,然后将公式编写成计算机代码完成计算,求导公式上一小节已经给出,根据公式编程如下:
import numpy as np
import matplotlib.pyplot as plt
def predict(x, a, b):
return a * x + b
def loss(y, y_):
v = y - y_
return np.sum(v * v) / len(y)
# 手动对a求偏导
def partial_a(x, y, y_):
return 2 / len(y) * np.sum((y-y_)*x)
# 手动对b求偏导
def partial_b(x, y, y_):
return 2 / len(y) * np.sum(y-y_)
# 学习率
learning_rate = 0.0001
# 初始化参数a, b
a, b = np.random.normal(size=2)
x = np.arange(30)
# 这些数据大致在 y = 6x + 1 附近
y_ = [7.1, 4.3, 6.5, 28.2, 11.8, 40.2, 24.8, 56.1,
36.9, 53.0, 52.2, 57.1, 62.5, 79.7, 95.8, 83.6,
103.0, 104.7, 108.2, 116.5, 115.1, 121.2, 129.8,
148.1, 142.1, 151.5, 165.8, 174.7, 154.5, 189.9]
loss_list = []
plt.scatter(x, y_, color="green")
for i in range(60):
y = predict(x, a, b)
lss = loss(y, y_)
loss_list.append(lss)
if i % 10 == 0:
print("%03d weight a=%.2f, b=%.2f loss=%.2f" % (i, a, b, lss))
plt.plot(x, predict(x, a, b), linestyle='--', label="epoch=%s" % i)
# 采用梯度下降算法更新权重
a = a - learning_rate * partial_a(x, y, y_)
b = b - learning_rate * partial_b(x, y, y_)
print("final weight a=%.2f, b=%.2f loss=%.2f" % (a, b, lss))
plt.plot(x, predict(x, a, b), label="final")
plt.legend()
plt.figure()
plt.plot(loss_list, color='red', label="loss")
plt.legend()输出如下:

左图中可以看出随着训练次数增加损失函数在逐渐降低,右图则更直观的看出拟合曲线随训练轮数的变化关系,最终给出了一条最“近似”的拟合线。
注意:1. 示例训练数据非常少只有30组,实际问题中样例数远大于这个数量。2. 这个小例子要把learning_rate设置的小一点,否则会因为训练数据过少导致训练抖而无法收敛。
TensorFlow2.0线性回归
上一步手动编写的线性回归函数只用于理解原理,实际生产中TensorFlow已经为我们写好了求解公式。回顾上述代码我们发现最重要的一步是梯度计算和参数更新,而梯度计算正是tf这样的计算框架的核心,tf通过自动微分帮我们屏蔽这些细节。tf线性回归代码如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def predict(x, a, b):
return x * a + b
def loss(y, y_):
len = tf.cast(tf.size(y), tf.float32)
return tf.reduce_sum(tf.square(y - y_)) / len
# 学习率
learning_rate = 0.0001
# 初始化参数a, b
a = tf.Variable(tf.random.uniform([1]))
b = tf.Variable(tf.random.uniform([1]))
loss_list = []
plt.scatter(x, y_, color="green")
x = tf.constant(tf.range(30, dtype=tf.float32))
y_ = tf.constant([7.1, 4.3, 6.5, 28.2, 11.8, 40.2, 24.8, 56.1,
36.9, 53.0, 52.2, 57.1, 62.5, 79.7, 95.8, 83.6,
103.0, 104.7, 108.2, 116.5, 115.1, 121.2, 129.8,
148.1, 142.1, 151.5, 165.8, 174.7, 154.5, 189.9])
for i in range(60):
# 记录要求导的目标公式
with tf.GradientTape() as tape:
lss = loss(predict(x, a, b), y_)
loss_list.append(lss.numpy())
if i % 10 == 0:
print("%03d a=%.2f, b=%.2f loss=%.2f" % (i, a.numpy(), b.numpy(), lss.numpy()))
plt.plot(x, predict(x, a, b), linestyle='--', label="epoch=%s" % i)
# 自动求导,这是tf的核心功能之一
partial_a, partial_b = tape.gradient(lss, [a, b])
# optimizer
a.assign_sub(learning_rate * partial_a)
b.assign_sub(learning_rate * partial_b)
print("final weight a=%.2f, b=%.2f loss=%.2f" % (a.numpy(), b.numpy(), lss.numpy()))
plt.plot(x, predict(x, a, b), label="final")
plt.legend()
plt.figure()
plt.plot(loss_list, color='red', label="loss")
plt.legend()输出:

上面的程序看起来明没有比用numpy手写简单多少,这是因为我们的目标公式很简单,当模型复杂之后采用手动编写求导公式会力不从心,tf自动求导功能的强大之处就体现出来了。训练一个线性公式步骤总结如下:
- 定义要拟合的公式
- 定义loss函数
- 自动微分:计算loss,并采用自动求导求出loss对于训练变量的偏导
- 优化器:使用梯度更新对应的训练变量
- 终止条件:重复步骤3~4,直到误差满足需求。
这5步中我们要做的只是第1~2步,其余都由tf框架自动完成,是不是很省心?
keras线性回归
keras是TensorFlow面向网络模型的高层API,使用keras可以写出更简洁的线性回归代码:
import tensorflow as tf
from tensorflow import keras
import tensorflow.keras.layers as layers
import matplotlib.pyplot as plt
x = tf.constant(tf.range(30, dtype=tf.float32))
y_ = tf.constant([7.1, 4.3, 6.5, 28.2, 11.8, 40.2, 24.8, 56.1,
36.9, 53.0, 52.2, 57.1, 62.5, 79.7, 95.8, 83.6,
103.0, 104.7, 108.2, 116.5, 115.1, 121.2, 129.8,
148.1, 142.1, 151.5, 165.8, 174.7, 154.5, 189.9])
plt.scatter(x, y_, color="green")
# y = a * x + b, 参数都隐藏在model中了
model = keras.Sequential([layers.Dense(1)])
optimizer = keras.optimizers.SGD(0.001)
model.compile(loss='mse', optimizer=optimizer)
for i in range(6):
plt.plot(x, model.predict(x), linestyle='--', label="epoch=%s" % i)
# 所有的训练逻辑都在fit()函数里头了。
model.fit(x, y_, epochs=1)
plt.plot(x, model.predict(x), label="final")
plt.legend()输出:

训练效果和前集中方法类似,但代码却大大简化了,所有的逻辑都隐藏在model.fit()函数中,包括前向的loss计算、后向的权重更新。这是keras的威力。
多元线性回归
前面讲的
用向量形式表示为:
对这样的数据做回归叫做多元线性回归,多元线性回归的算法跟一元线性回归类似,训练原理是一样的。高维数据用坐标不太好表示,这里不再演示。
总结
本文介绍了线性回归的数学原理,然后用numpy、TensorFlow2.0、keras等多种方式实现了一元线性回归。通过本文我们对损失函数、梯度下降有了基本的认识。感兴趣的话可以进一步了解“还有哪些损失函数?”,”优化器是什么?“,”多元线性回归和神经网络是什么关系?“,“什么是自动微分?”。