【Python实例第1讲】交叉验证预测曲线的画法
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
本例显示如何使用cross_val_predict函数可视化模型预测误差。这里要用到scikit-learn自带数据集——“波士顿房价数据集”。
数据集介绍
“波士顿房价数据集”位于datasets里,包括13个特征。首先,我们来看一看这个数据集的属性的详细信息。
from sklearn import datasets
boston = datasets.load_boston()
print(boston.DESCR)
打印结果显示:该数据集共有13个属性(特征)、506个实例(样本)。MEDV是目标变量,表示自住房屋房价的中位数(以千美元计)。下面列出所有14个属性的详细信息。
-
CRIM:城镇人均犯罪率。
-
ZN:住宅用地超过 25000 sq.ft. 的比例。
-
INDUS:城镇非零售商用土地的比例。
-
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。
-
NOX:一氧化氮浓度。
-
RM:住宅平均房间数。
-
AGE:1940 年之前建成的自用房屋比例。
-
DIS:到波士顿五个中心区域的加权距离。
-
RAD:辐射性公路的接近指数。
-
TAX:每 10000 美元的全值财产税率。
-
PTRATIO:城镇师生比例。
-
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
-
LSTAT:人口中地位低下者的比例。
-
MEDV:自住房的平均房价,以千美元计。
重要参数: return_X_y逻辑参数,表示是否返回target变量(即MEDV), 默认值是FALSE,只返回data(即预测属性)。
print(boston.data.shape)
我们将return_X_y的值改为True,再看一下
data,target = datasets.load_boston(return_X_y = True)
print(data.shape)
print(target.shape)
下面展示该数据集的一部分数据:
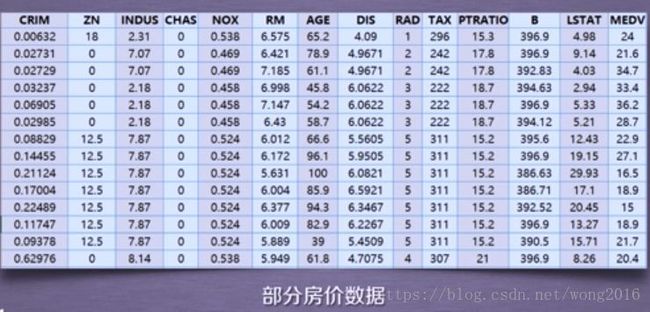
实例详解
第一步
首先,从sklearn库里导入必需的数据集和函数库。
from sklearn import datasets
from sklearn.model_selection import cross_val_predict
from sklearn import linear_model
import matplotlib.pyplot as plt
这里的matplotlib.pyplot是一个命令式的函数集,与matlab很像。每一个pyplot函数都会改变图形的某些属性,例如创建图形、在图里创建绘图区域、在绘图区画线、用标签装饰图形等。由于名字比较长,使用别名plt简化,在后面的程序里,可以使用它代表。
第二步
然后,使用类linear_model里的函数LinearRegression建立一个线性回归对象lr。导入波士顿房价数据,取目标变量。
lr = linear_model.LinearRegression()
boston = datasets.load_boston()
y = boston.target
第三步
调用函数cross_val_predict, 返回一个与y维数相同的数组predicted。在predicted的每一项里,保存一个由10倍交叉验证获得的预测。
predicted = cross_val_predict(lr, boston.data, y, cv=10)
第四步
Matplotlib能够把很多张图画到一个显示界面,这通过把绘图面板分割成若干个子图来实现。
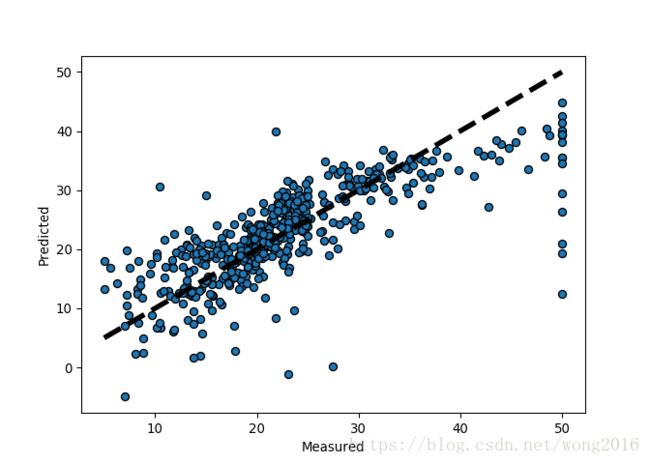
使用Matplotlib的函数subplot, 返回一个Figure对象,它包含多个子图(Axes).使用函数as.scatter, 以目标值为横轴、预测值为纵轴,绘成散点图。
fig, ax = plt.subplots()
ax.scatter(y, predicted, edgecolors=(0, 0, 0))
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
plt.show()
阅读更多精彩内容,请关注微信公众号:统计学习与大数据