辅助分类器遇上Domain Adaptation:连续性与不确定性
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
在领域迁移(Domain Adaptation)问题上,我们往往缺少对于无标注的目标领域数据(unlabled target-domain data)的有效约束。在我们的两篇文章中分别从不同角度,尝试利用了辅助分类器和主分类器的差异来正则模型的学习传统上,辅助分类器只是用来防止梯度消失问题,但我们考虑到,辅助分类器本质上提供了一个不同的预测,可以用来建模当前模型对于输入数据的不确定性。我们提出了两种方法来利用这种不确定性,都十分简单。现有方法不需要引入额外的参数,就能在几个benchmark上,如 GTA5->Cityscapes 等数据集上获得进一步的提升。

郑哲东:悉尼科技大学四年级博士生,研究方向为计算机视觉和智慧城市。2016年本科毕业于复旦大学,2017年~至今于悉尼科技大学直博(师从杨易教授)。博士四年中以第一作者发表 CCF-A类会议和ACM/IEEE期刊 9篇。Google Scholar引用次数3100+,H指数13,单篇一作论文最高被引970+次,在 Github代码开源网站上得到5200+stars。在2020年CVPR 智慧城市挑战(AI City Challenge)车辆重识别赛道获得冠军

一、背景

本文的领域迁移的任务主要是将游戏中获取的有标签的图片应用于现实世界。具体来说就是从游戏侠盗猎车5(GTA-5)中获得数据,其往往会有ground truth,其表明图中哪一部分是车辆,哪一部分是行人,哪一部分是车灯等等。对于游戏数据而言这是比较容易获取的,同时也会获取现实世界中收集到的数据,这些数据往往没有标签。所以Domain Adaptation解决问题是如何利用游戏的数据,去学一些knowledge,并且应用在实际的生活中,即将从游戏中学到的知识迁移到没有标注的真实场景下。然后其中最主要的核心是segmentation,语义分割。图中的ground truth是pixel level标注的。对于语义分割来说这个标注也是非常困难的,对于真实世界数据不可能完全由人工进行标注。

因此,对于Domain Adaptation来说,一方面获得了大量的游戏采集数据,另一方面获得了加州一个高速公路中的无标签的真实数据。理想情况是经过这两种数据的训练,当测试时可以直接进行公路测试。所以问题的本质更趋向于半监督学习问题,因为训练集中包含了有标签的游戏数据和无标签的真实数据。
对于测试集,其更接近于inductive learning,即测试集数据不会出现在训练集中。但是在测试集中同一个环境下采集的数据还会出现在训练集中。因此在接下来第一篇paper中,处理问题的角度主要从半监督学习展开。
二、Unsupervised Scene Adaptation with Memory Regularization in vivo
这篇文章名字叫Unsupervised Scene Adaptation with Memory Regularization in vivo。In vivo这个词,意味着在网络内部去做进行操作。

这篇paper实现的动机主要来源于,因为训练时的游戏数据包含有标签,即Source domain data,也就是GTA-5 data,它往往能保持主分类器和副分类器预测出来的结果是一样的。副分类器来源于语义分割网络,它往往会用辅助分类器来辅助梯度的传播。但是对于加州数据,即目标环境数据,它预测结果比较不一致,因为模型中没有一个强力的label去监督。
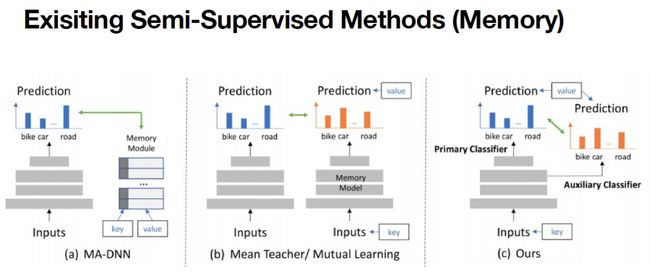
从很多传统的半监督学习的方法来看,有很多方法处理训练一致性的问题,包括像MA-DNN采用额外的memory,其中所存的是目标的prototype,即这些环境或者物体等类别的原型,在训练的时候,通过将类向原型靠近。
进一步像B图,Mean teacher或者Mutual Learning,它不需要额外的module去存。所以在该类型的方法中往往是有两个模型,然后进行互相学习。其中一个模型可以当做一个训练模型,另外一个模型当做一个memory 模型。这个memory模型每次都会提供一个检测目标应该是什么样的答案,然后让一个student模型去学习。
而在C图中,本文的in vivo就体现在只需要让主分类器和副分类器互相学习,而不需要两个模型,也不需要额外的memory module去预存prototype,而是在训练过程中自我学习,就可以达到比较好的效果。
可能会有人有疑问,为什么需要一个memory?为什么需要类的原型?本质上是为了提供一个teacher model,因为实际数据没有标签,所以可以通过一个模型先预测一个标签,虽然结果不一定正确,但是它可以提供一个正确的方向,去让student模型学得更好。此外in vivo的方法可以节省更多的计算消耗,而对于up to data,因为只需要经过一个模型,所以不需要inference两次,就可以得到比较好的结果。同时实验结果也显示,辅助分类器和主分类器并不会产生相互的干扰,因为一般来说主分类器得到结果会更高一点,辅助分类器因为它接的层比较浅,所以它的结果会比较低。但是结果显示主分类器并没有因为副分类器的效果而受到很大的影响。
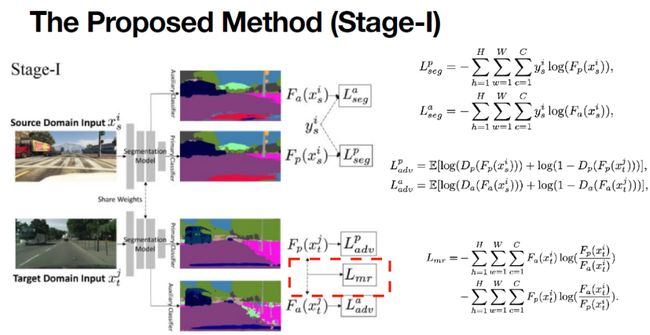
本文的方法包含有两个阶段。第一阶段包含label,对于这类数据,直接使用其label去supervise。第二阶段,数据不包含label,使用上面提到的memory机制,在上图中表现在红框中的Lmr,即主分类器与副分类器之间有相对熵,而训练的目的是使得相对熵尽可能的小。

主要分析一下第二阶段,其训练过程使用了第一阶段的模型,生成一个pseudo labor用于监督学习。使用第二阶段有两个原因:
第一个原因是模型可以只在target domain上学习,并且模型包含有Batch Normalization,结果更符合target domain。
第二个原因是在第二阶段学习的时候,从龙明盛老师或者说其他老师的minimize entropy的方法可以知道,其实pseudo label也可以提供一些信息,相当于原来模型预测0.9,然后将把0.9 push到1的这个过程当中,其含有一些 confidence的信息,这个过程会被第二阶段学习到。

上图的表格证实了两个分类器互相学习的时候,它们不会互相扯后腿,而是互相帮助。在左图中,之前的辅助分类器只有40,但互相学习以后可以达到44。主分类器之前只有43,但互相学习以后有45,然后把主副分类器结合以后,可以达到更高的结果,45.46。
右图中,研究了两个阶段的loss,第一阶段可以达到45.46,第二阶段可以达到48。即采用了pseudo label可以进一步获得提升。而且相比于State of the art,也有一个比较明显的提升。
三、Rectifying Pseudo Label Learning via Uncertainty Estimation for Domain Adaptive Semantic Segmentation

第二篇文章与第一篇文章的处理角度有着不同。这篇文章主要讨论,在第二阶段生成的伪标签并不是非常准确的。从上图中可以看出,生成出来的pseudo label和ground truth还是有一些差异的,虽然它大部分比如说路面预测是对的,但是很多细节是丢失的,同时很多地方给的是一个错误的标签。

有些比较直接的方法是设一个threshold,比如说预测出来这个标签的置信度不是很高,那模型就不会去学习。但是实验表明,如果人为设计一个threshold,对网络学习并没有很好的提升,因为threshold往往会把一些比较少的类别,比如说人出现比例比较小,特别语意分割中,如果一个物体比较小的话,它分到的loss就比较小,那很容易就被大的类别,比如说像路,天空所覆盖。所以threshold如果设的比较高,很多信息都被过滤掉了,最后得到结果会有误差。如果threshold设的比较低,所有的label都进行了学习,那模型中会包含noise label。自然而然的就会提出产生一个问题,能不能学一个自动的threshold,对于不同的地方或者不同置信度,会有一个自动的threshold。

这几篇paper,包括ICCV 2019的一篇做Re-identification的Paper,周志华老师的深度学习中,特别是贝叶斯网络部分也提到了如何去学习不确定性,然后还有ICML的workshop,以及另外一篇paper,都包含有然后去学习不确定性的内容。

在这篇文章中依然使用了主分类器和副分类器,因为实验结果表明主分类器和副分类器预测结果不一样的地方,往往是预测错误的地方。在上图的C中就是主分类器和副分类器预测结果有意见分歧的地方。而预测出来label和ground truth label,这之间的差距参考图像F,可以发现图C和图F有很高的一致性或者说是相关性,即主分类器和副分类器预测出来结果不一样的时候,这些地方往往是存在noise的地方,也是 label不是非常确定的地方。一个很直接想法,就是直接用主分类器和副分类器的相对熵作为不确定性。

不确定性一个最直接的用法是融入pseudo label learning时的一个公式。这个公式的第一项表示当主分类器和副分类器预测结果不一样的时候,它们之间的相对熵差异比较大,这是pseudo label就不会被重点学习。这里采用了1/Var,当Var非常小的时候,即主分类器和副分类器预测的非常接近,因为相对熵divergence经过了正则化处理,所以其最大值为一。与传统的pseudo label learning一样,当不确定性很小的时候,模型正常学习。当不确定性较大的时候,尽量减小bias的学习。这一部分放到第二项中,即不确定性的部分去学习。这就像是一个trade off,自动阈值去决定哪些label去学,哪些pseudo labor不去学。

这篇paper中也做了很多的operating study。关于这个pseudo label质量,如果pseudo label初始较差,有42,那经过模型学习后比较明显的提升,从46.8~47.4。如果pseudo label相对来说好一点,有45.5,那它的提升就会从上一篇paper的48.3提升到50.3。
此外还在模型中融入了一下dropout,去更好的预测不确定性。用dropout的话,主分类及和副分类器之间差异有时候会更大,然后更能表现它的不确定性。

上图是结论的可视化结果,可以看到预测后的主分类器和副分类器的意见有矛盾时,往往是预测错误点。
四、总结
最后是一些经验总结:
•有时候old school的理论,也可以辅助我们做很多事情。包括何凯明提出的contrastive learning。他的idea就很像semisupervised learning里面很多方法,比如ladder network。所以我觉得传统的理论,都可以帮助我们很好的去理解问题,同时让我们去想这个问题的时候会有更多理论的support。
•另外一方面是大家现在就是做深度学习,会有一个同质化的问题,就是结果可能也不是那么重要。所以如何就把我们人的先验知识去融入到神经网络里面,或者说像memory module之类的一些比较常见的先验知识融入到网络里面,我觉得这是我们值得去思考的一个问题。
相关资料
论文链接:
https://arxiv.org/abs/1912.11164
https://arxiv.org/abs/2003.03773
代码链接:
https://github.com/layumi/Seg-Uncertainty
整理:闫 昊
审稿:郑哲东
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://www.bilibili.com/video/BV14p4y1s77p)
(点击“阅读原文”下载本次报告ppt)