51job爬虫项目
文章目录
- 引言
- 数据爬取与解析
-
- 详情页链接的获取:selenium
- 数据爬取与解析:xpath
- 数据存储
-
- Excel本地保存
- Excel数据保存结果展示
- sqlite数据库保存
- sqlite数据库保存结果展示
- 数据可视化
引言
紧接着豆瓣爬虫的项目,该项目作为其后的练习和扩展,算是一个较为不错的上手练习。本文所涉及的是对于51job数据的爬取、解析和保存。对于数据可视化操作,在后续会持续更新,请关注!
在下面代码中有些函数内部调用了其他函数,需要补全各个部分的函数。如果需要源码请私信或者评论。
具体关于库的操作我选择了一些官方文档和较好理解的解读文章做链接,知识点比较全面请参考下列表。
-
详情页URL获取模块:selenium
-
URL处理第三方模块:requests
-
数据提取etree模块:lxml
-
数据库保存模块:sqlite3
-
本地文件保存模块:xlwt
数据爬取与解析
详情页链接的获取:selenium
selenium作为web自动化测试工具,目前在python爬虫中应用也越来越广泛。其主要应用原理是:通过完全模拟浏览器的操作,比如输入框输入、点击超链接元素、下拉滚动条等等来拿到js渲染之后的代码。
必要性:之前用的requests是对一个页面发送请求,只能获得当前加载出来的部分页面即最初的源代码,动态加载的数据是获取不到的,比如js渲染后的代码、下拉滚轮得到的数据和一些框内隐藏元素等等。
对于selenium的解读,请点击click!
#获得所有网页详情页链接
def get_link():
linklist = []
#创建驱动器对象
wd = webdriver.Chrome(r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
wd.implicitly_wait(5)
#访问51job网站
for i in range(1,21):
wd.get(f"https://search.51job.com/list/010000,000000,0000,00,9,99,keyword,2,{i}.html?")
#查找每每一条信息链接进入详情页
joblists = wd.find_elements_by_xpath('//div[@class="j_joblist"]/div/a')
for joblist in joblists:
con_link = joblist.get_attribute("href")
linklist.append(con_link)
wd.quit()
return linklist
注释:
- 代码中的 webdriver.Chrome,后面是自己所用的驱动器的本地地址。
- webdriver对象wd,调用 get方法,后面括号内为自己所要访问的网页链接地址。
数据爬取与解析:xpath
由于自己习惯于使用xpath方法解析,在此只做xpath解析的方法,如果需要re正则表达式或者BeautifulSoup解析,评论后续会更新。
def get_data():
job_information = []
url_lists = get_link()
for i,url in enumerate(url_lists):
datalist=[]
header = {
"User-Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.150Safari/537.36"
}
response = requests.get(url, headers=header)
try:
html = response.content.decode("gbk")
data = etree.HTML(html)
link = url
datalist.append(link) #存入岗位链接
title = data.xpath(r'//div[@class="cn"]/h1/@title')[0]
datalist.append(title) #存入岗位名称
salary = data.xpath(r'//div[@class="cn"]/strong/text()')[0]
datalist.append(salary)
information = data.xpath(r'//p[@class="msg ltype"]/@title')[0]
information = re.sub(r"\s+", "", information) # 去除空白格
experience = information.split("|")[1]
datalist.append(experience)
education = information.split("|")[2]
datalist.append(education)
num = information.split("|")[3]
datalist.append(num)
place = data.xpath(r'//p[@class="fp"]/text()')[0]
datalist.append(place)
treatment = data.xpath(r'//span[@class="sp4"]/text()')
treatment = " ".join(treatment)
datalist.append(treatment)
print("-----第{}条------".format(i))
job_information.append(datalist)
except Exception as e:
print("-----第{}条出错,原因是{}------".format(i,e))
continue
#print(job_information) #测试
return job_information
数据存储
Excel本地保存
def save_data_excel(datalist):
workbook = xlwt.Workbook(encoding="gbk", style_compression=0)
worksheet = workbook.add_sheet("python")
col = ["链接", "岗位名称", "薪资", "工作经验", "学历", "招聘人数", "工作地点", "福利"]
for i in range(0, 8):
worksheet.write(0, i, col[i])
for i in range(len(datalist)):
for j in range(0, 8):
worksheet.write(i+1,j,datalist[i][j])
workbook.save("北京-python工作.xls")
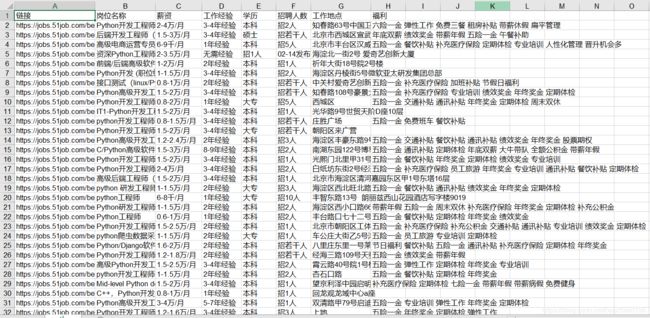
Excel数据保存结果展示
sqlite数据库保存
在此部分只写了数据库保存的工作,数据库的初始化创建需函数sql_init需要添加即可使用。
def save_data_sql(datalist,dbpath):
sql_init(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + data[index] + '"'
sql = '''
insert into job_information(
link,title,salary,experience,education,num,place,treatment)
values(%s)'''%",".join(data)
#print(sql) #测试sql语句是否正确
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
sqlite数据库保存结果展示

数据可视化
null,期待后续!