google bert模型详解 源码解析
Table of Contents
模型简介
1. A High-Level Look
2. Encoder(http://jalammar.github.io/illustrated-transformer/)
3. Self-Attention(http://jalammar.github.io/illustrated-transformer/)
4. Matrix Calculation of Self-Attention(http://jalammar.github.io/illustrated-transformer/)
5. Multi-headed Self-Attention(http://jalammar.github.io/illustrated-transformer/)
一、模块一之生成预训练数据
1. tokenizer
2. create_training_instances
3. create_instances_from_document
4. create_masked_lm_predictions
5. write_instance_to_example_files
二、模块二之构建模型
1. embedding_postprocessor
2. transformer_model
2.1 attention_layer
三、模块三之预训练过程
1. model_fn_builder
1.1 构建遮蔽词预测的损失函数
1.2 构建Next Sentence Prediction的损失函数
Reference
ps:本文略长,坚持看完,相信对深入理解bert模型的原理及实现会有较大帮助。如有错误,恳请批评指正。
模型简介
2018年10月11号,Google团队发表了BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,引起了NLP领域的轰动,为什么如此之火?第一,效果好,bert在11项NLP任务中取得了state-of-the-art的结果,包括NER、问答等任务;第二,在nlp领域更加成熟的运用“预训练+fine-tuning”方法(同图像处理领域,更加成熟是指前面已经有了word2vec、glove、fasttext等前辈及GPT、ELMo等兄弟),算得上是nlp领域的里程碑。张俊林博士在博客中也说,“客观的说,把Bert当做最近两年NLP重大进展的集大成者更符合事实。”
关于模型,网上有很多介绍,这里仅列出我认为最核心的几个点:
1. A High-Level Look

bert的名称已经反映了模型本身,即:
1) Deep: base model: 12层,110M parameters,large model:24层,340M parameters;
2) Bidirectional: 双向,可以看到上下文;
3) Transformer: 作者抛弃了rnn,lstm等经典rnn结构,而是采用transformer作为基本单元,即采用self-attention,自己跟自己做attention,不仅可以获取长距离依赖关系,还可以显著提升并行计算能力(对比传统attention)。
bert模型本身创新不是太大,核心的transformer引用自2017年12月6号发表的Attention Is All You Need(也是谷歌团队),但在预训练中采用了一些tricks,这些tricks显著提升了模型的表达能力。
1) 输入表征(Input Representation): bert不再仅仅使用WordPiece embeddings,还增加了segment embeddings和position embeddings,如下图(https://arxiv.org/pdf/1810.04805.pdf),

在代码解析部分会对三个向量进行详细解释。
2) 随机遮蔽(Masked LM): 对输入token进行随机遮蔽,然后对对应位置的输出进行预测,具体会在代码部分进行详细解释,作者说灵感来源于Cloze task,本质是CBOW(大家都这么说);
3) Next Sentence Prediction: 即将句子A,B拼在一起作为输入,在输出时预测B是否是A的下一句。因此bert的预训练是多任务训练,不仅预测masked tokens,还需预测是否是下一句,这使得模型在一定程度上学习到了句子间的关系知识。
2. Encoder(http://jalammar.github.io/illustrated-transformer/)



每个Encoder包含两层——self-attention、ffnn(feed forward neural network),每层后面跟了residual connection及layer normalization。
3. Self-Attention(http://jalammar.github.io/illustrated-transformer/)
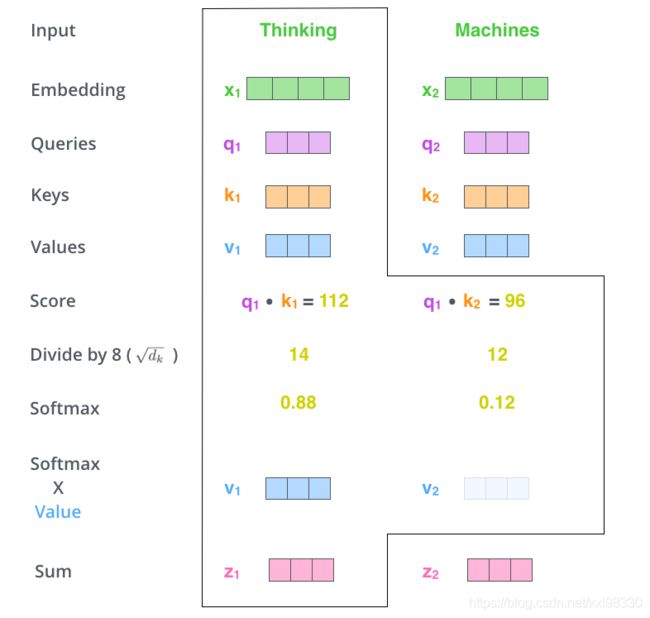
上图描述了self-attention的具体过程,其中q(Query)、k(Key)、v(Value)见下文,Jay Alammar在The Illustrated Transformer一文中对transformer的encoder进行了详细介绍。
4. Matrix Calculation of Self-Attention(http://jalammar.github.io/illustrated-transformer/)


上图公式即transformer的self-attention的前向计算过程。
5. Multi-headed Self-Attention(http://jalammar.github.io/illustrated-transformer/)

上图描述了Multi-headed Self-Attention的具体过程,每个head生成一个Zi,所有的Zi拼接,然后与矩阵 相乘,得到Z。Multi-headed的主要作用是增加了representation subspaces(表征子空间),因为每个head对应一套
相乘,得到Z。Multi-headed的主要作用是增加了representation subspaces(表征子空间),因为每个head对应一套 、
、 、
、 ,因此上图中的Zi对应了不同的表征子空间,从而增加了模型的表征能力。
,因此上图中的Zi对应了不同的表征子空间,从而增加了模型的表征能力。
至此,模型简介完毕,下面会通过代码解析对其实现细节进行全面剖析。
一、模块一之生成预训练数据
先来个感观认识:
INFO:tensorflow:*** Example ***
INFO:tensorflow:tokens: [CLS] this was nearly opposite . [SEP] at last dunes reached the quay at [MASK] opposite end of [MASK] street [MASK] and there burst on [MASK] ##am ##mon [MASK] s [MASK] eyes a vast semi [MASK] ##rcle of blue sea , ring ##ed with palaces and towers . [MASK] stopped in ##vo ##lun ##tar [MASK] ; and his little guide [MASK] also , and looked ask ##ance at the young monk , [MASK] watch the effect which that [MASK] panorama should produce on him . [SEP]
INFO:tensorflow:input_ids: 101 2023 2001 3053 4500 1012 102 2012 2197 17746 2584 1996 21048 2012 103 4500 2203 1997 103 2395 103 1998 2045 6532 2006 103 3286 8202 103 1055 103 2159 1037 6565 4100 103 21769 1997 2630 2712 1010 3614 2098 2007 22763 1998 7626 1012 103 3030 1999 6767 26896 7559 103 1025 1998 2010 2210 5009 103 2036 1010 1998 2246 3198 6651 2012 1996 2402 8284 1010 103 3422 1996 3466 2029 2008 103 23652 2323 3965 2006 2032 1012 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:masked_lm_positions: 9 14 18 20 25 28 30 35 48 54 60 72 78 0 0 0 0 0 0 0
INFO:tensorflow:masked_lm_ids: 2027 1996 1996 1025 6316 1005 22741 6895 2002 6588 3030 2000 2882 0 0 0 0 0 0 0
INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
INFO:tensorflow:next_sentence_labels: 1bert模型的预训练数据生成主要在create_pretraining_data.py及tokenization.py中。
先看下官方给出的生成预训练数据命令行:
python create_pretraining_data.py \
--input_file=./sample_text.txt \ # 输入文件,以逗号分隔的文件名称,示例见下图
--output_file=/tmp/tf_examples.tfrecord \ # 输出文件,以逗号分隔的文件名称
--vocab_file=$BERT_BASE_DIR/vocab.txt \ # 词典文件,Google提供
--do_lower_case=True \ # 是否忽略大小写,为True时,忽略
--max_seq_length=128 \ # 每条训练数据的最大长度,过长的会截取,不够的会进行padding
--max_predictions_per_seq=20 \ # 每条样本遮蔽token的最大数量
--masked_lm_prob=0.15 \ # 每条样本以15%的概率遮蔽token(不够准确, 详见代码)
--random_seed=12345 \ # 随机数
--dupe_factor=5 # 命令行中的dupe_factor, 最外层循环, 直观理解是同一句话生成了
dupe_factor条样本(不过每条样本的next sentence和masks不同)将从create_pretraining_data.py的main开始讲起。。。
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
# 1.设置tokenizer为FullTokenizer,负责对文本进行预处理。详见下文(1. tokenizer)
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
# 将以空格分隔的文件名转为文件列表
input_files = []
for input_pattern in FLAGS.input_file.split(","):
input_files.extend(tf.gfile.Glob(input_pattern))
tf.logging.info("*** Reading from input files ***")
for input_file in input_files:
tf.logging.info(" %s", input_file)
rng = random.Random(FLAGS.random_seed)
# 2. 构造数据集,详见下文(2. create_training_instances)
instances = create_training_instances(
input_files, tokenizer, FLAGS.max_seq_length, FLAGS.dupe_factor,
FLAGS.short_seq_prob, FLAGS.masked_lm_prob, FLAGS.max_predictions_per_seq,
rng)
output_files = FLAGS.output_file.split(",")
tf.logging.info("*** Writing to output files ***")
for output_file in output_files:
tf.logging.info(" %s", output_file)
write_instance_to_example_files(instances, tokenizer, FLAGS.max_seq_length,
FLAGS.max_predictions_per_seq, output_files)1. tokenizer
tokenizer定义在tokenization.py模块中,该模块主要定义了三种tokenizer: BasicTokenizer, WordpieceTokenizer, FullTokenizer。每个tokenizer中都对应一个tokenize函数,用以对文本进行预处理。其中FullTokenizer综合了BasicTokenizer和WordpieceTokenizer,所以叫Full...
1)BasicTokenizer
功能:对原始文本进行预处理,包括删除无效字符、转换空白字符为空格、将中文及部分韩文日文字符前后加空格、去除accent字符等,最后按空格分隔,返回tokens列表。
仅有一个入参do_lower_case,是否忽略大小写
def tokenize(self, text):
"""Tokenizes a piece of text."""
text = convert_to_unicode(text)
text = self._clean_text(text) # 1.1 删除无效字符,将所有空白字符转为空格
# This was added on November 1st, 2018 for the multilingual and Chinese
# models. This is also applied to the English models now, but it doesn't
# matter since the English models were not trained on any Chinese data
# and generally don't have any Chinese data in them (there are Chinese
# characters in the vocabulary because Wikipedia does have some Chinese
# words in the English Wikipedia.).
text = self._tokenize_chinese_chars(text) # 1.2 将中文及部分韩文日文字符前后加空格,部分以空格分隔的日文韩文不作处理
orig_tokens = whitespace_tokenize(text) # 2 将经过上述处理后的文本按空格切分,生成列表
split_tokens = []
# 3 针对每个token,根据unicodedata去除accent字符,对于含标点的token进行进一步分词(包含标点)
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
# 返回basic预处理后的词/字列表
return output_tokens2) WordpieceTokenizer
功能:对经过BasicTokenizer处理后的tokens列表进行“分词”(根据Google提供的bert模型中的词典),返回合法tokens列表。
有三个参数: a) vocab: 词典(dict);
b) unk_token(str, default '[UNK]'): unknown string替换为[UNK],单个词长超过max_input_chars_per_word的token也替换为[UNK];
c) max_input_chars_per_word(default 200): 每个词(token)的最大长度。
def tokenize(self, text):
"""Tokenizes a piece of text into its word pieces.
运用最长匹配优先的贪婪算法将一段文本解析成词列表
This uses a greedy longest-match-first algorithm to perform tokenization
using the given vocabulary.
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
Args:
text: A single token or whitespace separated tokens. This should have
already been passed through `BasicTokenizer.
输入text:单个词或以空格分隔的词字符串
Returns:
A list of wordpiece tokens.
"""
text = convert_to_unicode(text)
output_tokens = [] # 输出tokens列表
for token in whitespace_tokenize(text):
chars = list(token)
# 对于词长大于max_input_chars_per_word的替换为[UNK]
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = [] # 子词列表
while start < len(chars):
end = len(chars)
cur_substr = None # 当前子词
while start < end: # start从前向后(以子词为单位),end从后向前(以一个字符为单位)
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr # 待加入子词
if substr in self.vocab: # 满足条件:待加入子词应在词典中
cur_substr = substr
break
end -= 1 # end从后向前(以一个字符为单位)
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end # start从前向后(以子词为单位)
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens3) FullTokenizer
功能:主要是封装了BasicTokenizer和WordpieceTokenizer,通过tokenize函数,返回经过预处理后的tokens列表。
该类较简单,此处不作介绍。
预处理说完了,值得我们借鉴的是它整个的预处理流程,并没有正则去除ip、电话号码、网址等复杂的规则操作,只是简单粗暴的去除无效字符、空白字符、accent,然后运用贪婪算法依据vocab进行分词,效果却不错,值得思考借鉴!
2. create_training_instances
功能:从输入文档的raw text构造data set
def create_training_instances(input_files, tokenizer, max_seq_length,
dupe_factor, short_seq_prob, masked_lm_prob,
max_predictions_per_seq, rng):
"""Create `TrainingInstance`s from raw text.
输入:
input_files: 输入文档列表
tokenizer: 上文提到的文档预处理类(FullTokenizer)
max_seq_length: 命令行中的参数, 单个输入样本的序列最大长度
dupe_factor: 命令行中的参数, 每篇文章重复生成训练集的次数(即每句话重复
dupe_factor次, 因为mask是随机产生的)
short_seq_prob: 命令行中参数, 默认0.1, 以10%的概率生成短训练样本, 以增加鲁棒性
masked_lm_prob: 命令行参数, 默认0.15, 以15%的概率遮蔽token(不够准确, 详见代码)
max_predictions_per_seq: 命令行参数, 默认20, 与masked_lm_prob共同决定遮蔽token数量,
详见代码
rng: random实例
输出:
instances: TrainingInstance列表, 每个TrainingInstance对应一条训练样本, 包括
mask好的tokens, segmented_ids(句子id), is_random_next,
masked_lm_positions(mask的index), masked_lm_labels(对应原始文本)
"""
# all_documents是个三维列表, 第一维度代表一篇文章,
# 每篇文章是一个二维列表, 其中每个元素代表one line
all_documents = [[]]
# 输入文件内容格式(样例见Google提供的sample_text.txt文本):
# (1) 每行一句
# (2) 不同文章以空行间隔(方便构造"next sentence prediction"任务的训练样本)
# 读取输入文件列表文本内容, 保存在all_documents中
for input_file in input_files:
with tf.gfile.GFile(input_file, "r") as reader:
while True:
line = tokenization.convert_to_unicode(reader.readline())
if not line:
break
line = line.strip()
# Empty lines are used as document delimiters
if not line:
all_documents.append([])
# 调用FullTokenizer类的tokenize接口(内部分别调用了BasicTokenizer、
# WordPieceTokenizer的tokenize接口)
tokens = tokenizer.tokenize(line)
if tokens:
all_documents[-1].append(tokens)
# Remove empty documents 去除空文章
all_documents = [x for x in all_documents if x]
# 对第一维度(文章)进行随机排列
rng.shuffle(all_documents)
vocab_words = list(tokenizer.vocab.keys()) # 字典中的所有词
instances = []
# 命令行中的dupe_factor, 最外层循环, 直观理解是同一句话生成了dupe_factor条样本
# (不过每条样本的next sentence和masks不同)
for _ in range(dupe_factor):
for document_index in range(len(all_documents)):
# 因为有"next sentence prediction"任务, 所以实际是通过
# create_instances_from_document生成样本(以all_documents第一维度---文章为单位)
instances.extend(
create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng))
rng.shuffle(instances)
return instances3. create_instances_from_document
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
"""以单篇文章为单位生成样本数据.
输入:
all_documents: 预处理后的文档数据列表
document_index: 当前文档在all_documents的索引
输出:
instances: TrainingInstance列表, 每个TrainingInstance对应一条训练样本, 包括
mask好的tokens, segmented_ids(句子id), is_random_next,
masked_lm_positions(mask的index), masked_lm_labels(对应原始文本)
"""
document = all_documents[document_index] # 当前生成样本所用文章
# Account for [CLS], [SEP], [SEP]
# 每条样本由两句话A,B组成, 样本数据以'[CLS]'开头,每句话以'[SEP]'结尾,
# 即[CLS]A[SEP]B[SEP], 所以实际最大的tokens数量需减去3
max_num_tokens = max_seq_length - 3
# We *usually* want to fill up the entire sequence since we are padding
# to `max_seq_length` anyways, so short sequences are generally wasted
# computation. However, we *sometimes*
# (i.e., short_seq_prob == 0.1 == 10% of the time) want to use shorter
# sequences to minimize the mismatch between pre-training and fine-tuning.
# The `target_seq_length` is just a rough target however, whereas
# `max_seq_length` is a hard limit.
# 为增加模型鲁棒性, 使其泛化到其他nlp任务, 会以10%概率生成短训练数据,
# 最终实际结果40%左右(sample_text.txt作为输入), 原因是
# 1) 构造sentence A 时到达文章末尾;
# 2) 构造sentence B 时, 候选sentences过少等
target_seq_length = max_num_tokens
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
instances = []
current_chunk = [] # 生成样本的候选sentences
current_length = 0 # 候选sentences总tokens长度
i = 0
while i < len(document):
segment = document[i]
current_chunk.append(segment) # 生成样本的候选sentences
current_length += len(segment)
# 只有当文章最后一句或候选sentences总tokens长度大于待生成样本长度时才进入代码,
# 否则一直append sentence
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
# `a_end` is how many segments from `current_chunk` go into the `A`
# (first) sentence.
a_end = 1 # 代表有几句sentences作为A
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
# 构造sentence A
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# Random next
is_random_next = False
# sentence B 是随机的
# 条件1是到达当前文章末尾了, 那只能随机了; 条件2是50%概率
if len(current_chunk) == 1 or rng.random() < 0.5:
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
# 10次随机生成不同的文章索引, 如果10次还生成不了, 那还不赶紧买彩票去?!
for _ in range(10):
random_document_index = rng.randint(0, len(all_documents) - 1)
if random_document_index != document_index:
break
# 构造sentence B, 此时样本A+B的长度>=target_seq_length, 后面会修剪
random_document = all_documents[random_document_index]
random_start = rng.randint(0, len(random_document) - 1)
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# 为避免浪费raw text, 需要将倒退到a_end
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# sentence B非随机
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
# 对样本数据进行修剪至max_num_tokens, A, B谁长修剪谁,
# 并以等概率从A/B开头或结尾开始修剪
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
assert len(tokens_a) >= 1
assert len(tokens_b) >= 1
tokens = [] # 用以转为上文'模型简介---输入表征'中的tokens embeddings
segment_ids = [] # 用以转为上文'模型简介---输入表征'中的segment_ids embeddings
tokens.append("[CLS]")
segment_ids.append(0) # sentence A 对应 0
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
for token in tokens_b:
tokens.append(token)
segment_ids.append(1) # sentence B 对应 1
tokens.append("[SEP]")
segment_ids.append(1)
# 至此, 原始训练样本构造完毕, 接下来随机mask, 得到最终的训练样本.
# 详见create_masked_lm_predictions
(tokens, masked_lm_positions,
masked_lm_labels) = create_masked_lm_predictions(
tokens, masked_lm_prob, max_predictions_per_seq, vocab_words, rng)
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
instances.append(instance)
current_chunk = []
current_length = 0
i += 1
return instances4. create_masked_lm_predictions
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
"""Creates the predictions for the masked LM objective.
输入:
tokens: 一条训练样本
masked_lm_prob: 随机遮蔽概率
max_predictions_per_seq: 单条样本的最大遮蔽数
vocab_words: 词典
rng: random实例
输出:
output_tokens: mask后的训练样本
masked_lm_positions: 替换的index
masked_lm_labels: 替换的原始文本
"""
cand_indexes = [] # 待mask的候选indexs
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
cand_indexes.append(i)
rng.shuffle(cand_indexes) # 随机打乱
output_tokens = list(tokens)
# 待mask或待预测的数量(由max_predictions_per_seq和masked_lm_prob同时控制)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
for index in cand_indexes:
if len(masked_lms) >= num_to_predict: # 取前num_to_predict个进行替换
break
if index in covered_indexes:
continue
covered_indexes.add(index)
masked_token = None
# 80%替换为'[MASK]'
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10%保持不变
if rng.random() < 0.5:
masked_token = tokens[index]
# 10%随机替换为词典中其他词
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
# MaskedLmInstance为namedtuple类型('index', 'label')
masked_lms.append(MaskedLmInstance(index=index, label=tokens[index]))
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_positions = []
masked_lm_labels = []
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_labels.append(p.label)
return (output_tokens, masked_lm_positions, masked_lm_labels)
5. write_instance_to_example_files
def write_instance_to_example_files(instances, tokenizer, max_seq_length,
max_predictions_per_seq, output_files):
"""Create TF example files from `TrainingInstance`s.
将instances写入output_files
"""
writers = []
# 每个output_file对应一个TFRecordWriter
for output_file in output_files:
writers.append(tf.python_io.TFRecordWriter(output_file))
writer_index = 0
total_written = 0
for (inst_index, instance) in enumerate(instances):
# 将样本转换为id列表
input_ids = tokenizer.convert_tokens_to_ids(instance.tokens)
input_mask = [1] * len(input_ids)
segment_ids = list(instance.segment_ids)
assert len(input_ids) <= max_seq_length
# 对不足max_seq_length的样本进行pad(0对应词典中的'[PAD]')
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
masked_lm_positions = list(instance.masked_lm_positions) # mask位置
# mask对应的原始token, 转ids列表
masked_lm_ids = tokenizer.convert_tokens_to_ids(instance.masked_lm_labels)
# mask权重, 方便后续loss计算, 详见下文
masked_lm_weights = [1.0] * len(masked_lm_ids)
# 不足 max_predictions_per_seq 的补 0/0.0
while len(masked_lm_positions) < max_predictions_per_seq:
masked_lm_positions.append(0)
masked_lm_ids.append(0)
masked_lm_weights.append(0.0)
next_sentence_label = 1 if instance.is_random_next else 0
# 创建tf.train.Example实例, 并写入output_files
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writers[writer_index].write(tf_example.SerializeToString())
writer_index = (writer_index + 1) % len(writers)
total_written += 1
# 日志信息(打印前20条)
if inst_index < 20:
tf.logging.info("*** Example ***")
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in instance.tokens]))
for feature_name in features.keys():
feature = features[feature_name]
values = []
if feature.int64_list.value:
values = feature.int64_list.value
elif feature.float_list.value:
values = feature.float_list.value
tf.logging.info(
"%s: %s" % (feature_name, " ".join([str(x) for x in values])))
for writer in writers:
writer.close()
tf.logging.info("Wrote %d total instances", total_written)
再来看下生成样本:
INFO:tensorflow:*** Example ***
INFO:tensorflow:tokens: [CLS] this was nearly opposite . [SEP] at last dunes reached the quay at [MASK] opposite end of [MASK] street [MASK] and there burst on [MASK] ##am ##mon [MASK] s [MASK] eyes a vast semi [MASK] ##rcle of blue sea , ring ##ed with palaces and towers . [MASK] stopped in ##vo ##lun ##tar [MASK] ; and his little guide [MASK] also , and looked ask ##ance at the young monk , [MASK] watch the effect which that [MASK] panorama should produce on him . [SEP]
INFO:tensorflow:input_ids: 101 2023 2001 3053 4500 1012 102 2012 2197 17746 2584 1996 21048 2012 103 4500 2203 1997 103 2395 103 1998 2045 6532 2006 103 3286 8202 103 1055 103 2159 1037 6565 4100 103 21769 1997 2630 2712 1010 3614 2098 2007 22763 1998 7626 1012 103 3030 1999 6767 26896 7559 103 1025 1998 2010 2210 5009 103 2036 1010 1998 2246 3198 6651 2012 1996 2402 8284 1010 103 3422 1996 3466 2029 2008 103 23652 2323 3965 2006 2032 1012 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:masked_lm_positions: 9 14 18 20 25 28 30 35 48 54 60 72 78 0 0 0 0 0 0 0
INFO:tensorflow:masked_lm_ids: 2027 1996 1996 1025 6316 1005 22741 6895 2002 6588 3030 2000 2882 0 0 0 0 0 0 0
INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
INFO:tensorflow:next_sentence_labels: 1样本生成完了, 模型马上就来。。。
二、模块二之构建模型
bert主模型在modeling.py模块中。配置信息存储在BertConfig实例中,模型在BertModel中构建。
模型配置信息(BertConfig):
vocab_size, # 词典大小
hidden_size=768, # 隐藏层大小(向量维数)
num_hidden_layers=12, # 隐藏层数(transformer层数)
num_attention_heads=12, # transformer层的header数
intermediate_size=3072, # 中间层维度(先升维后降维,后面介绍)
hidden_act="gelu", # 激活函数
hidden_dropout_prob=0.1, # embedding层、hidden层dropout的概率值
attention_probs_dropout_prob=0.1, # attention层dropout的概率值
max_position_embeddings=512, # position embeddings shape: [max_position_embeddings, hidden_size]
# 即输入最长支持512
type_vocab_size=16, # segment embedding shape: [type_vacab_size, hidden_size]
# 即输入最长支持16句话
initializer_range=0.02 # 参数初始化时标准差stddevBertModel::__init__
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=True,
scope=None):
"""Constructor for BertModel.
Args:
config: `BertConfig` instance.
is_training: bool. true for training model, false for eval model. Controls
whether dropout will be applied.
input_ids: int32 Tensor of shape [batch_size, seq_length].
input_mask: (optional) int32 Tensor of shape [batch_size, seq_length].
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
use_one_hot_embeddings: (optional) bool. Whether to use one-hot word
embeddings or tf.embedding_lookup() for the word embeddings. On the TPU,
it is much faster if this is True, on the CPU or GPU, it is faster if
this is False.
scope: (optional) variable scope. Defaults to "bert".
Raises:
ValueError: The config is invalid or one of the input tensor shapes
is invalid.
"""
config = copy.deepcopy(config)
# 如果是预测,将drop_out去掉
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
# shape: [batch_size, seq_length]
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
# embedding层
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
# 返回embedding_output([batch_size, seq_length, embedding_size]),
# embedding_table([vacab_size, embedding_size]) --- (word vector)
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add positional embeddings and token type embeddings, then layer
# normalize and perform dropout.
# 1. embedding_postprocessor, 增加位置编码及句子编码,详见下文
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# 将input_mask由[batch_size, seq_length]转换成[batch_size, seq_length, seq_length]
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# 2. 12/24层的transformer在transformer_model中创建, 详见下文.
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
# transformer的最后输出
self.sequence_output = self.all_encoder_layers[-1]
# 后面的‘pooler’可根据实际业务需求进行调整
# 此处'pooler'是将第一个token作为input,增加一个dense layer
# 论文中说:The first token of every sequence is always the special
# classification embedding ([CLS]). The final hidden state (i.e., output of
# Transformer) corresponding to this token is used as the aggregate sequence
# representation for classification tasks. For non- classification tasks,
# this vector is ignored.
# 即 输入的第一个token为[CLS],输出对应的第一个token(论文认为该token可以代表整个输入的
# 集合)可用以对输入进行分类
# input shape:[batch_size, hidden_size], out_shape:[batch_size, hidden_size]
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
# 第一个token shape: [batch_size, hidden_size]
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))1. embedding_postprocessor
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""Performs various post-processing on a word embedding tensor.
此处主要为词向量增加位置信息(position embeddings)和句子信息(segment embeddings)。
Args:
input_tensor: float Tensor of shape [batch_size, seq_length,
embedding_size].
use_token_type: bool. Whether to add embeddings for `token_type_ids`.
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
Must be specified if `use_token_type` is True.
token_type_vocab_size: int. The vocabulary size of `token_type_ids`.
token_type_embedding_name: string. The name of the embedding table variable
for token type ids.
use_position_embeddings: bool. Whether to add position embeddings for the
position of each token in the sequence.
position_embedding_name: string. The name of the embedding table variable
for positional embeddings.
initializer_range: float. Range of the weight initialization.
max_position_embeddings: int. Maximum sequence length that might ever be
used with this model. This can be longer than the sequence length of
input_tensor, but cannot be shorter.
dropout_prob: float. Dropout probability applied to the final output tensor.
Returns:
float tensor with same shape as `input_tensor`.
Raises:
ValueError: One of the tensor shapes or input values is invalid.
"""
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
# Segment Embedding(类似于词向量表的初始化)
# shape: token_type_vocab_size * hidden_size (16 * 768), 默认最长支持16句话
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary.
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
# Position Embedding(类似于词向量表的初始化)
# shape: max_position_embeddings * hidden_size (512 * 768), 最长支持句长512
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
#
# So `full_position_embeddings` is effectively an embedding table
# for position [0, 1, 2, ..., max_position_embeddings-1], and the current
# sequence has positions [0, 1, 2, ... seq_length-1], so we can just
# perform a slice.
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
num_dims = len(output.shape.as_list())
# Only the last two dimensions are relevant (`seq_length` and `width`), so
# we broadcast among the first dimensions, which is typically just
# the batch size.
# 同一个batch中的position embeddings相同,所以直接在batch_size维进行broadcast
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
# 最后对输出进行layer normalization、dropout
output = layer_norm_and_dropout(output, dropout_prob)
return output2. transformer_model
transformer_model包含num_hidden_layers层,每层包含multi-headed self-attention(residual),FFNN(residual)
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
构建transformer
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
# 将input_tensor由3D reshape成2D(优化在tpu上的计算)
prev_output = reshape_to_matrix(input_tensor)
# 逐层构建transformer,每层包含"attention"、"intermediate"、"output"三个scope
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
# 2.1 构造multi-headed self-attention,详见attention_layer
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
# attention后加dense layer,将attention output映射到hidden_size维
# (可将该dense layer视作attention的一部分)
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# FFNN过程,对attention_output先升维后降维(激活函数仅在该层使用)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
# 降维到hidden_size
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output # 单层transformer的输出
all_layer_outputs.append(layer_output) # 所有transformer层的输出,方便取出
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
2.1 attention_layer
self_attention机制简介:self_attention字面意思是自己跟自己做attention(乘法注意力),使每个词都能“看到”整句话,即使得每个词都具有全局语义信息;然后运用multi-headed(将hidden_size平均分成多个heads),使每个head学习到不同的子空间语义,然后将multi-heads的输出进行拼接,得到当前attention_layer的最终输出。
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
# from_tensor ---> Q to_tensor ---> K, V
# (乘法注意力)
# output_multi_headed_attention = softmax((Q * K.T) / sqrt(num_heads)) * V
# shape: [batch_size, seq_len, size_per_head]
# then concatenate all heads and return [batch_size, seq_len, hidden_size]
Args:
from_tensor: float Tensor of shape [batch_size, from_seq_length,
from_width].
to_tensor: float Tensor of shape [batch_size, to_seq_length, to_width].
attention_mask: (optional) int32 Tensor of shape [batch_size,
from_seq_length, to_seq_length]. The values should be 1 or 0. The
attention scores will effectively be set to -infinity for any positions in
the mask that are 0, and will be unchanged for positions that are 1.
num_attention_heads: int. Number of attention heads.
size_per_head: int. Size of each attention head.
query_act: (optional) Activation function for the query transform.
key_act: (optional) Activation function for the key transform.
value_act: (optional) Activation function for the value transform.
attention_probs_dropout_prob: (optional) float. Dropout probability of the
attention probabilities. (对注意力矩阵进行dropout)
initializer_range: float. Range of the weight initializer.
do_return_2d_tensor: bool. If True, the output will be of shape [batch_size
* from_seq_length, num_attention_heads * size_per_head]. If False, the
output will be of shape [batch_size, from_seq_length, num_attention_heads
* size_per_head].
batch_size: (Optional) int. If the input is 2D, this might be the batch size
of the 3D version of the `from_tensor` and `to_tensor`.
from_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `from_tensor`.
to_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `to_tensor`.
Returns:
3D: [batch_size, from_seq_length, num_attention_heads * size_per_head] 或
2D: [batch_size * from_seq_length, num_attention_heads * size_per_head])
Raises:
ValueError: Any of the arguments or tensor shapes are invalid.
"""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
from_tensor_2d = reshape_to_matrix(from_tensor)
to_tensor_2d = reshape_to_matrix(to_tensor)
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# 将key、value reshape成[batch_size, num_per_head, seq_len, size_per_head]
# `query_layer` = [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Take the dot product between "query" and "key" to get the raw
# attention scores.
# `attention_scores` = [B, N, F, T]
# softmax((Q * K.T) / sqrt(num_heads)) * V (乘法注意力)
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# `attention_mask`: [B, F, T] ---> [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# mask中为1的位置置为0, 为0的地方置为-10000,然后直接加到attention_scores中,进行
# softmax,提升计算效率
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# 对V进行reshape、transpose,然后attention_probs * V ===> [B, N, F, H]
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
三、模块三之预训练过程
bert模型的预训练过程包含两个任务: 1) 下一句预测(Next Sentence Prediction); 2) 遮蔽词预测。主程序在run_pretraining.py中。由于训练过程使用高级接口(TPU)Estimator,因此整个预训练过程的逻辑基本按照Estimator的参数要求进行。
主程序:
def main(_):
tf.logging.set_verbosity(tf.logging.INFO) # 配置log日志打印级别为INFO
if not FLAGS.do_train and not FLAGS.do_eval:
raise ValueError("At least one of `do_train` or `do_eval` must be True.")
# bert网络模型结构参数定义在json文件中
bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file)
tf.gfile.MakeDirs(FLAGS.output_dir)
# 输入文件列表
input_files = []
for input_pattern in FLAGS.input_file.split(","):
input_files.extend(tf.gfile.Glob(input_pattern))
tf.logging.info("*** Input Files ***")
for input_file in input_files:
tf.logging.info(" %s" % input_file)
tpu_cluster_resolver = None
if FLAGS.use_tpu and FLAGS.tpu_name:
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(
FLAGS.tpu_name, zone=FLAGS.tpu_zone, project=FLAGS.gcp_project)
# tpu训练配置信息(没用过tpu,所以对参数没有深入研究。。。不过不影响对整个训练过程的理解)
is_per_host = tf.contrib.tpu.InputPipelineConfig.PER_HOST_V2
run_config = tf.contrib.tpu.RunConfig(
cluster=tpu_cluster_resolver,
master=FLAGS.master,
model_dir=FLAGS.output_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps,
tpu_config=tf.contrib.tpu.TPUConfig(
iterations_per_loop=FLAGS.iterations_per_loop,
num_shards=FLAGS.num_tpu_cores,
per_host_input_for_training=is_per_host))
# 1. 模型构建器,Estimator的入参之一。详见下文
model_fn = model_fn_builder(
bert_config=bert_config,
init_checkpoint=FLAGS.init_checkpoint,
learning_rate=FLAGS.learning_rate,
num_train_steps=FLAGS.num_train_steps,
num_warmup_steps=FLAGS.num_warmup_steps,
use_tpu=FLAGS.use_tpu,
use_one_hot_embeddings=FLAGS.use_tpu)
# If TPU is not available, this will fall back to normal Estimator on CPU
# or GPU.
# 构造Estimator
estimator = tf.contrib.tpu.TPUEstimator(
use_tpu=FLAGS.use_tpu,
model_fn=model_fn,
config=run_config,
train_batch_size=FLAGS.train_batch_size,
eval_batch_size=FLAGS.eval_batch_size)
if FLAGS.do_train:
tf.logging.info("***** Running training *****")
tf.logging.info(" Batch size = %d", FLAGS.train_batch_size)
# 训练数据集构建器。
train_input_fn = input_fn_builder(
input_files=input_files,
max_seq_length=FLAGS.max_seq_length,
max_predictions_per_seq=FLAGS.max_predictions_per_seq,
is_training=True)
# 开始训练
estimator.train(input_fn=train_input_fn, max_steps=FLAGS.num_train_steps)
if FLAGS.do_eval:
tf.logging.info("***** Running evaluation *****")
tf.logging.info(" Batch size = %d", FLAGS.eval_batch_size)
# 验证数据集构建器
eval_input_fn = input_fn_builder(
input_files=input_files,
max_seq_length=FLAGS.max_seq_length,
max_predictions_per_seq=FLAGS.max_predictions_per_seq,
is_training=False)
# 开始验证
result = estimator.evaluate(
input_fn=eval_input_fn, steps=FLAGS.max_eval_steps)
output_eval_file = os.path.join(FLAGS.output_dir, "eval_results.txt")
with tf.gfile.GFile(output_eval_file, "w") as writer:
tf.logging.info("***** Eval results *****")
for key in sorted(result.keys()):
tf.logging.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))1. model_fn_builder
def model_fn_builder(bert_config, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator.
根据Estimator的输入需要, 构造model_fn:
input:'features', 'labels', 'mode'(optional),
'params'(optional), 'config'(optional)
output: tf.estimator.EstimatorSpec)
"""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
masked_lm_positions = features["masked_lm_positions"]
masked_lm_ids = features["masked_lm_ids"]
masked_lm_weights = features["masked_lm_weights"]
next_sentence_labels = features["next_sentence_labels"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
# 构建神经网络
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# 1. 构建遮蔽词预测的损失函数。详见下文
(masked_lm_loss,
masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
# 2. 构建Next Sentence Prediction的损失函数。 详见下文
(next_sentence_loss, next_sentence_example_loss,
next_sentence_log_probs) = get_next_sentence_output(
bert_config, model.get_pooled_output(), next_sentence_labels)
# 两项训练任务的total loss
total_loss = masked_lm_loss + next_sentence_loss
# tvars中对应所有可训练的变量
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
# 根据tvars从init_checkpoint中初始化变量:assignment_map({scope/var: scope/var})
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN: # 训练
# 创建optimizer training op
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
# 返回TPUEstimatorSpec实例
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.EVAL: # 验证
def metric_fn(masked_lm_example_loss, masked_lm_log_probs, masked_lm_ids,
masked_lm_weights, next_sentence_example_loss,
next_sentence_log_probs, next_sentence_labels):
"""Computes the loss and accuracy of the model.
input:
masked_lm_example_loss: (batch_size * max_predictions_per_seq, )
masked_lm_log_probs: (batch_size * max_predictions_per_seq, vocab_size)
masked_lm_ids: (batch_size, max_predictions_per_seq)
masked_lm_weights: (batch_size, max_predictions_per_seq)
next_sentence_example_loss: (batch_size, )
next_sentence_log_probs: (batch_size, 2)
next_sentence_labels: (batch_size, )
"""
masked_lm_log_probs = tf.reshape(masked_lm_log_probs,
[-1, masked_lm_log_probs.shape[-1]])
# shape: (batch_size * max_predictions_per_seq, )
masked_lm_predictions = tf.argmax(
masked_lm_log_probs, axis=-1, output_type=tf.int32)
masked_lm_example_loss = tf.reshape(masked_lm_example_loss, [-1])
masked_lm_ids = tf.reshape(masked_lm_ids, [-1])
masked_lm_weights = tf.reshape(masked_lm_weights, [-1])
masked_lm_accuracy = tf.metrics.accuracy(
labels=masked_lm_ids,
predictions=masked_lm_predictions,
weights=masked_lm_weights)
masked_lm_mean_loss = tf.metrics.mean(
values=masked_lm_example_loss, weights=masked_lm_weights)
next_sentence_log_probs = tf.reshape(
next_sentence_log_probs, [-1, next_sentence_log_probs.shape[-1]])
next_sentence_predictions = tf.argmax(
next_sentence_log_probs, axis=-1, output_type=tf.int32)
next_sentence_labels = tf.reshape(next_sentence_labels, [-1])
next_sentence_accuracy = tf.metrics.accuracy(
labels=next_sentence_labels, predictions=next_sentence_predictions)
next_sentence_mean_loss = tf.metrics.mean(
values=next_sentence_example_loss)
return {
"masked_lm_accuracy": masked_lm_accuracy,
"masked_lm_loss": masked_lm_mean_loss,
"next_sentence_accuracy": next_sentence_accuracy,
"next_sentence_loss": next_sentence_mean_loss,
}
eval_metrics = (metric_fn, [
masked_lm_example_loss, masked_lm_log_probs, masked_lm_ids,
masked_lm_weights, next_sentence_example_loss,
next_sentence_log_probs, next_sentence_labels
])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
else:
raise ValueError("Only TRAIN and EVAL modes are supported: %s" % (mode))
return output_spec
return model_fn
1.1 构建遮蔽词预测的损失函数
我认为可以通过对比word2vec理解masked_lm,类似于word2vec中运用skip gram训练词向量,即先将bert模型的输入encode为该函数的输入input_tensor,再通过参数output_weights解码(针对masked输出,连接一个全连接层,将hidden_size映射到vocab_size维,并视作是vocab_size维的多分类问题,且此处的参数是bert模型输入的embedding table(真实词向量),类似skip gram的decoder层),不过损失函数区别于word2vec的负采样及层序softmax。
def get_masked_lm_output(bert_config, input_tensor, output_weights, positions,
label_ids, label_weights):
"""Get loss and log probs for the masked LM.
input:
input_tensor: (batch_size, seq_length, hidden_size)
output_weights: (vocab_size, hidden_size)
positions: (batch_size, max_predictions_per_seq)
label_ids: (batch_size, max_seq_length)
label_weights: (batch_size, max_predictions_per_seq)
return:
loss: scalar
per_example_loss: shape (batch_size * max_predictions_per_seq, )
log_probs: shape (batch_size * max_predictions_per_seq, vocab_size)
"""
# shape: (batch_size * max_predictions_per_seq, hidden_size)
# 获取被masked位置的输出向量(每个batch有batch_size * max_predictions_per_seq个位置)
input_tensor = gather_indexes(input_tensor, positions)
with tf.variable_scope("cls/predictions"):
# We apply one more non-linear transformation before the output layer.
# This matrix is not used after pre-training.
# 在预训练时会针对masked positions的向量加一层非线性映射,非预训练时不需要该层
# 输出:(batch_size * max_predictions_per_seq, hidden_size)
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
# 此处的权重即bert模型的embedding table
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
# 计算ln(softmax) shape: (batch_size*max_predictions_per_seq, vocab_size)
log_probs = tf.nn.log_softmax(logits, axis=-1)
# shape: batch_size * max_predictions_per_seq
label_ids = tf.reshape(label_ids, [-1])
# shape: batch_size * max_predictions_per_seq
label_weights = tf.reshape(label_weights, [-1])
# masked positions的真实labels
# shape: max_predictions_per_seq * vocab_size
one_hot_labels = tf.one_hot(
label_ids, depth=bert_config.vocab_size, dtype=tf.float32)
# The `positions` tensor might be zero-padded (if the sequence is too
# short to have the maximum number of predictions). The `label_weights`
# tensor has a value of 1.0 for every real prediction and 0.0 for the
# padding predictions.
# log_probs * one_hot_labels shape: (batch_size * max_predictions_per_seq,
# vocab_size) ---> 每一行仅一个维度非0
# shape: (batch_size * max_predictions_per_seq, )
# target function:最大化labels处的概率,取负号改为最小化(区别于word2vec)
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1])
# 去掉补0项(padding)的loss
numerator = tf.reduce_sum(label_weights * per_example_loss)
denominator = tf.reduce_sum(label_weights) + 1e-5 # 代表该批次需要预测的个数
loss = numerator / denominator # 平均loss
return (loss, per_example_loss, log_probs)1.2 构建Next Sentence Prediction的损失函数
def get_next_sentence_output(bert_config, input_tensor, labels):
"""Get loss and log probs for the next sentence prediction.
input:
input_tensor: (batch_size, hidden_size)
return:
loss: scalar
per_example_loss: (batch_size, )
log_probs: (batch_size, 2)
"""
# 二分类问题:对input_tensor连接两个神经元,参数为output_weights, output+bias
# Simple binary classification. Note that 0 is "next sentence" and 1 is
# "random sentence". This weight matrix is not used after pre-training.
with tf.variable_scope("cls/seq_relationship"):
output_weights = tf.get_variable(
"output_weights",
shape=[2, bert_config.hidden_size],
initializer=modeling.create_initializer(bert_config.initializer_range))
output_bias = tf.get_variable(
"output_bias", shape=[2], initializer=tf.zeros_initializer())
# shape: (batch_size, 2)
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
# log probabilities shape: (batch_size, 2)
log_probs = tf.nn.log_softmax(logits, axis=-1)
labels = tf.reshape(labels, [-1])
# shape: (batch_size, 2)
one_hot_labels = tf.one_hot(labels, depth=2, dtype=tf.float32)
# 仅取label对应的loss
# shape: (batch_size, )
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, log_probs)Reference
1. BERT model
2. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
3. Attention Is All You Need
4. The Illustrated Transformer
5. 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
注:本文可以任意转载,转载时请标明作者和出处。