疑难杂症之灾备一切换网络就中断,怎么破?
今天整好是大年三十,这里先给各位读者拜个早年,我发现之前的疑难杂症系列较为受到欢迎,因此就总结一下近些年工作中遇到的一些精典案例,总结一下并去掉涉及敏感信息分享给大家,同时我也突然发现这次生产+灾备这对欢喜冤家的话题,好像和情人节还有点关系,因此也就顺便参加情人节征文了,这里祝各位读者牛年行大运,牛气冲天,情场职场双丰收。
两地三中心-幸福的一家三口
在开展下的介绍之前这里我们先来介绍一下灾备体系的主要技术指标:
RTO(Recovery Time Objective):RTO是指灾难发生后,从IT系统崩溃导致业务停顿开始,到IT系统完全恢复,业务恢复运营为止的这段时间长度。RTO用于衡量业务从停顿到恢复的所需时间。
RPO(Recovery Point Objective):IT系统崩溃后,可以恢复到某个历史时间点,从历史时间点到灾难发生的时间点的这段时间长度就称为RPO。RPO用于衡量业务恢复所允许丢失的数据量。
简单来讲RTO就是灾难发生后业务中断的时间,RPO就是灾难发生后数据丢失的数量。比如这次微盟的删库事件业务历时8天完全恢复,而数据全部找回,那么其RTO就是8天,RPO就是0。
一般来说目前比较流行的灾备体系是至少建设三个数据中心,而这三中心的关系有点像一家三口的关系,具体说明如下:
主中心:正常情况下全面提供业务服务
同城中心:一般使用同步复制的方式来向同城灾备中心传输数据,保证同城中心数据复本为最新,随时可以接管业务,以保证RTO的指标。但是同城中心无法应对此类删库事件。
异地中心:一般使用延时异步复制(延时时间一般为30分钟左右)的方式向异地灾备中心传输数据,其中同步复制的好处是一旦主中心被人工破坏,那么不会立刻涉及异地中心。以保证RPO的指标。
总结灾备体系的最佳实践就是两地三中心,其中生产与同城中心像一对夫妻共同保证业务连续性,优先负责用户体验;异地中心则像是个宝宝,保证数据连续性,确保在爸妈都出问题的情况下,家庭还有延续的火种。
心连心vs 心贴心,这是个问题
之前DNS域名寻址技术没有推广应用的时候,很多企业的灾备中心与生产中心全部是使用二层打通的技术来搭建的,也就是说灾备中心与生产中心使用相同的网段,网关在正常情况下活在生产中心,由于这种二层延伸的方案主备中心实际分享同一网络核心,因此也常被称为心连心方案,如下图所示。
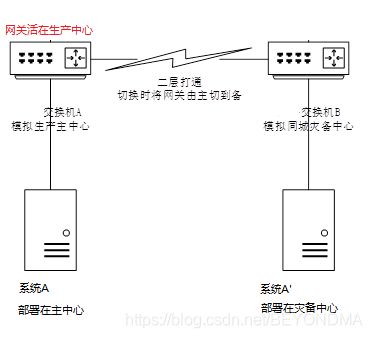
注:图示中的系统A与其灾备节点A’处于同一网段。
对于这种二层延伸的网络结构,在进行单个系统切换时只需要把系统A的服务IP迁移到灾备A’即可,也就是将A’的IP地址改为A实际上就完成了切换,这样基于IP地址的实备切换方案与主备双机切换几乎完全一样,非常的简单易行,因此在前些年容器等云原生技术未推广的时候广为流行。但是这样的方案也有一个问题就是进行灾备中心级切换时需要将网络的活动网关由主中心切换至备中心,此动作会造成网关切换涉及的网络区域服务全部中断。
与二层延伸的方案相对应,三层连接就是心贴心的方案了,在三层连接的灾备体系中主备中心分别使用不同的网段,无论是单系统还是中心级的切换,都是改为DNS的域名解析指向,由于三层连接主备中心不再共享网络核心因此得名心贴心。
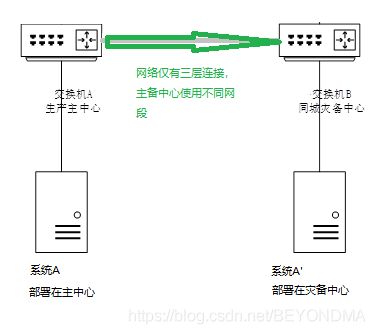
注:图示中的系统A与其灾备节点A’处于不同网段,切换时由DNS改变域名解析指向。
心连心的整体切换方案
考虑到二层延伸方案中中心级整体切换时网关迁移影响较大,而且单系统切换时IP地址飘移也需要较长的时间,这会造成灾备中的RTO指标难以保证,并且因此二层延伸的方案逐渐被网络三层连接的方案所取代。
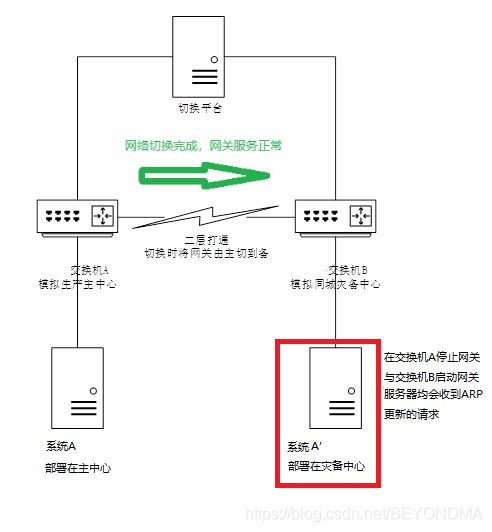
虽然二层延伸方案已经是明日黄花,但是由于存量依旧众多,因此在前一段时间我专门针对这种二层延伸的方案的中心级整体切换,模拟生产中心发生灾难而整体中断的情况进行了测试,想看看心连心方案是否还有其它的坑,结果真有惊喜,方案示意图如下:
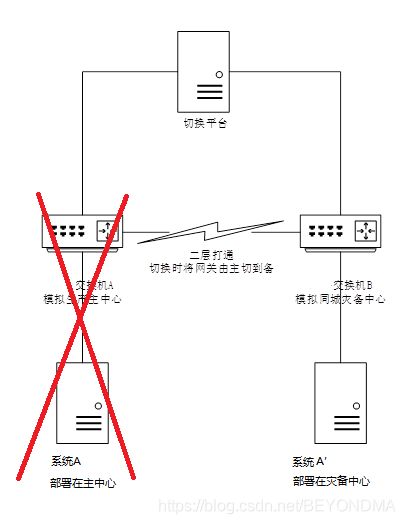
一般来讲,中心级整体的灾备切换,目前各行业都研发一个切换平台,统一调度网络设备及系统的切换,当然无此平台也没所谓,因此切换平台只是为了提升切换时间也就是RTO指标的,具体切换动作由手工执行也是一样,切换主要分为以下三个阶段:
系统A主中心服务停止,(主要包括应用服务、节点A卸载服务IP等动作)
网络同城切换(主要包括网关服务主中心停止,备中心启动)
系统A灾备中心服务启动(主要包括节点A’挂载服务IP,启动应用服务等动作)
心连心方案中网络中断的问题
这样的测试过程大多数情况下都能成功,但是在切换步骤2网络同城切换后,服务器设备有小概率出现长时间网络中断的问题。
以我的验证环境为例(具体硬件型号不便公开),切换40次约出现一次概率约为2.5%,出现系统A’长时间(5分钟左右)不能联网的问题。
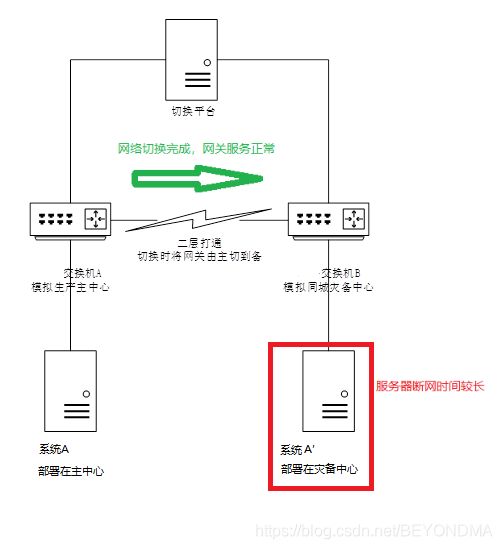
不过与之形成对比的是在正常情况下,网关切换后,服务器可在10秒之内恢复联网,那么到底是什么引起服务器A’长时间网络不能恢复呢?
断网原因分析
初步分析的此问题应该是由于网络切换造成网关MAC改变,服务器ARP表的更新超时导致的,因此在A’端进行了抓包检查,发现在交换机A停止网关与交换机B启动网关时,服务器A’均会收到ARP更新的报求。
翻阅Linux源码发现在arp_process函数中,使用了大量原子操作及操作系统同步原语,以保证arp表的更新不出现冲突。但原子锁操作的另一结果是在arp表更新的过程,其它arp表更新请求将可能被丢弃。具体关键源代码解读如下:
static void arp_process(unsigned long arg)
{
...
if (time_after(now, tbl->last_rand + 300 * HZ)) { //内核每5分钟重新进行一次配置
}
if (atomic_read(&n->refcnt) == 1 &&...){ //使用的原子读操作
(state == NUD_FAILED || time_after(now, n->used + n->parms->gc_staletime))) {
*np = n->next;
n->dead = 1;
write_unlock(&n->lock);
neigh_release(n);
continue;
}
....
}
断网问题解决方案
在确定了问题成因是由于两次arp更新请求时间间隔较近,第一次网关A发布的ARP更新请求其所包含的信息不是最新的;而第二次由网关B发出ARP更新请求又恰逢上一次请求没有完成因此被丢弃,那么ARP表就需要等到超时时间(5分钟)以后才会更新,针对此问题我们确定了两种解决方案
解决方案一:由于跨广播域发起的ping操作本身就可以对于本机的arp表进行更新,这样就可以使arp表不会在5分钟超时之后才能够更新,因此我们在服务器A与服务器B上均开启了长arpping的动作。
解决方案二:加大交换机A停止网关与交换机B启动网关之间的时间间隔,即使服务器在收到交换机B启动网关的ARP更新请增长时,已经将之前ARP更新请求处理完成,应该也可以解决此问题,此方案尚待验证。
生产到灾备的切换的过程,是不是像极了小两口在过日的时候发生的磕磕绊绊呢,希望这个破案的过程可以对各位读者有一定的启发与帮助。