amoeba高可用mysql_详解Mysql 高可用方案 之 Failover mha

在分布式系统中,我们往往会考虑系统的高可用,对于无状态程序来讲,高可用实施相对简单一些,纵向、横向扩展起来相对容易,然而对于数据密集型应用,像数据库的高可用,就不太好扩展。我们在考虑数据库高可用时,主要考虑发生系统宕机意外中断的时候,尽可能的保持数据库的可用性,保证业务不会被影响;其次是备份库,只读副本节点需要与主节点保持数据实时一致,当数据库切换后,应当保持数据的一致性,不会存在数据缺失或者数据不一致影响业务。很多分布式数据库都把这个问题解决了,也能够通过很灵活的方式去满足业务需求,如同步、半同步方式、数据副本数量、主从切换、failover 等等(下面会提到),然而我们平时使用的社区官方版 mysql5.7及以前的版本 (不包括 Mysql 其他分支像 PhxSQL,Percona XtraDB Cluster,MariaDB Galera Cluster) 都在支持分布式和系统可用性这块处理得不是很完善。针对这个系列问题,下面分析下如何解决这个问题。
在这期间发现并提交合并了一个mha在线切换master 而导致master 和slave 数据不一致的bug

何为failover
提mha之前,提前普及一下failover。何为failover,即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作,故障转移(failover)与交换转移操作基本相同,只是故障转移通常是自动完成的,没有警告提醒手动完成,而交换转移需要手动进行,对于要求高可用和高稳定性的服务器、系统或者网络,系统设计者通常会设计故障转移功能。
简单来说就是当系统某块服务不可用了,系统其它服务模块能够自动的继续提供服务,有很多设计良好的开源软件设计都会自动包含failover,像负载均衡nginx,haproxy可以支持后端检测,backup,当检测到后端upstream(endpoints)异常,会自动的无缝进行切换到正常的backup上,然后像分布式的数据密集型应用也会包含failover,包括mongdb副本集,etcd/zookeeper 节点选举,elasticsearch副本集等等,当存在部分数据节点异常,选举数据节点为master/primary/leader,甚至消息队列像rabbitmq镜像队列,kafka replicas都会包含failover。
链接:
zookeeper leader选举
etcd-raft
etcd-raft可视化
mongdb副本集
rabbitmq镜像队列
kafka ISR和同步
elasticsearch replics
数据复制
前面提到了failover,那么既然系统支持failover,那必须要保证能有 backup 或者是 replics 来作为新 "master"(这里把leader/master/primary都统称为master )继续提供服务。前面提到了很多开源软件设计过程中就自带了数据同步功能,就是数据所有的插入、删除、更新都在 master 上进行,然后数据会同步到 slave 里,简单来说需要保持 master-slave 数据一致。这里同步的方式可以像 mysql-bin log,mongdb optlog 通过日志的方式实现,将 update(),delete(),insert() 等操作记录到 log 中,然后这些语句都转发给每个从库,每个从库解析并执行该SQL语句,就像从客户端请求收到一样,在从库中重放该数据;也可以通过传输预写式日志(wal)的方式,日志优先写入到磁盘,如SSTables 和 LSM 树实现的引擎,所以日志都是包含所有数据库写入的仅追加字节序列,可以使用完全相同的日志在另一个节点上构建副本,将日志写入磁盘同时,主库可以通过网络将其发送给其它从节点,如etcd状态机同步; 还有的方式是通过集群内部的进程直接发送需要同步的数据,如rabbitmq镜像队列。
下图就是一个数据复制的应用场景:一个用户有写入操作更新到写库,然后其他用户可能从从库中读取数据,可能数据是最新的,也可能出现从库由于延时不是最新的,复制系统针对这种场景化分为了几种复制方式。
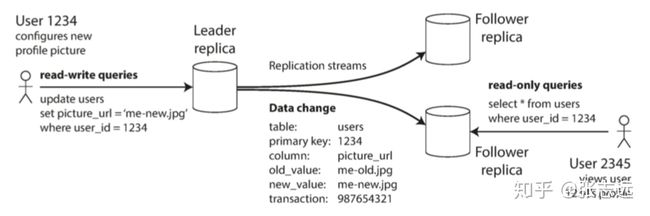
复制系统的一个重要细节是:复制是同步(synchronously)还是异步(asynchronousl)
关于复制方式:
同步复制(synchronous):
同步复制就是当有数据更新请求到 master 节点,需要保证该更新操作在 slave 节点上执行成功后才返回客户端,从库保证有与主库完全一致的最新数据副本。如果主库突然失效,我们可以确信这些数据仍能在从库上找到,但是该方式也有缺点,如果从库没有响应(比如它已经崩溃,或者出现网络故障,或其它任何原因),主库就无法处理写入操作,主库必须阻止所有写入,并等待同步副本再次可用,这个过程数据库是无法更新插入数据。
异步复制(asynchronous):
异步复制就是当有更新数据请求到 master 节点,master 操作结束直接返回客户端,不需要 slave 确认,slave 后台从 master 更新数据。该方式的缺点是,如果主库失效且不可恢复,则任何尚未复制给从库的写入都会丢失,这意味着即使已经向客户端确认成功,写入也不能保证持久(Durable)。该方式的优点是:即使所有的从库都落后了,主库也可以继续处理写入操作,服务继续运行。
半同步复制(semi-synchronous):
半同步复制是一种中间策略,当有更新数据请求到 master 节点,需要保证该操作在某个 slave 上也执行成功才最终返回客户端,如果某个同步的 slave 变得缓慢,则可以使一个异步 slave 变为同步,这样在保证一定数据一致性的前提下也能保证可靠性(这里可能会导致数据不一致,还可能产生数据延时)。
mysql的半同步复制(mysql semi-synchronous):
master在执行完更新操作后立即向 slave 复制数据,slave 接收到数据并写到 relay log (无需执行)后才向 master 返回成功信息,master 必须在接受到 slave 的成功信息后再向客户端返回响应,仅在数据复制发生异常(slave 节点不可用或者数据复制所用网络发生异常)的情况下,master 才会暂停(mysql 默认约 10 秒左右) 对客户端的响应,将复制方式降级为异步复制。当数据复制恢复正常,复制方式将恢复为半同步复制。
mysql 的数据同步和 failover
mysql 支持相对严格的 ACID,是一个性能和稳定性都非常不错的关系型数据库,但是对分布式支持不是很友好,虽然它实现了NDB,不过感觉使用不太广泛,国内使用较多的还是基础的主从复制方式。mysql支持前面提到的各种数据复制方式,所以只需要针对各种的场景选取对应的复制方式即可。像对可用性要求较高,数据一致性要求较低的可以选取异步复制;对数据一致性要求很高的场景,金融场景可以选用强同步复制;互联网场景对可用性和一致性可能都有一定要求,但要求不是特别高,可以选择半同步复制。下面简述 mysql 主从同步的逻辑
mysql的主从同步逻辑:
首先开启mysql master上的 binlog, mysql slave上通过一个 I/O 线程从 mysql master上读取binlog,然后传输到 mysql slave 的中继日志中,接着mysql slave 的 sql 线程从中继日志中读取中继日志,应用到mysql slave的 数据库中,这样就实现了主从数据同步功能。
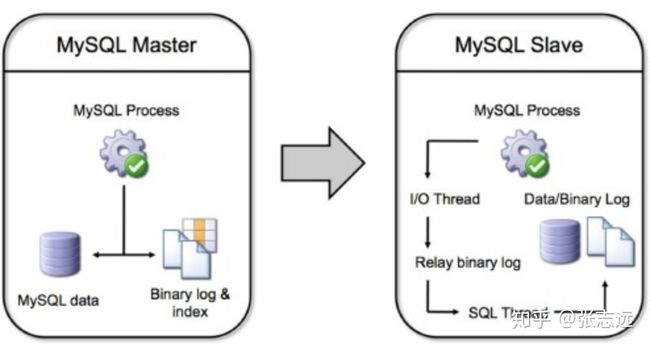
不过 mysql 自身没有实现 failover,所以当 master 异常的时候,需要制定策略去实现 failover 并处理数据库切换。failover 的逻辑是当 master 异常,slave 自动提升为主库的,然后让其他从库知道新的 master,并继续从新的 master同步数据。在这里我们就要用到 mha了,一个mysql 高可用管理工具。mha 能做到在 0~30 秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,能在最大程度上保证数据的一致性,以达到真正意义上的高可用。关于 mha 的各种细节我这里就不详细展开了,这些内容都在官方wike中(文档真的非常详细,作者考虑很多通用的场景,很多参数可配置化)。
链接:
mha安装
mha优势
mha架构
mha配置
等等等....
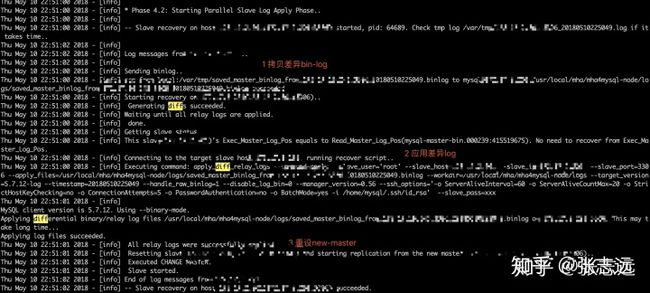
这里只分析他实现 failover 的架构与原理,结构如下(官网的图片,略模糊)
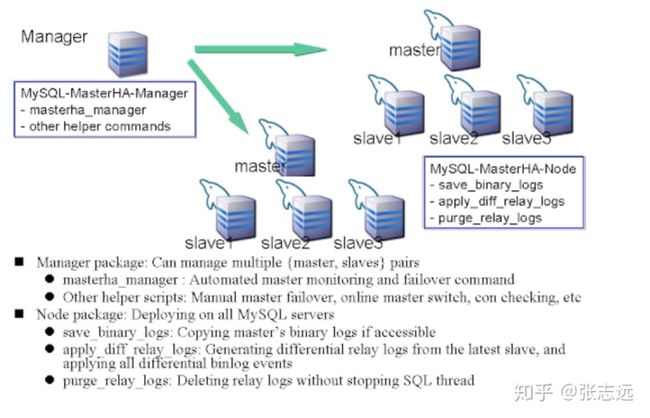
mha 由两部分组成:
mha manager(管理节点): 单独部署在一台独立的机器上管理多个 master-slave 集群(最好和mysql相关服务器管理),也可以部署在一台 slave 节点上,作用是多mysql server服务的管理,master检测,master选举,连接检查,master故障切换等工作。
mha node(数据节点): 运行在每台 mysql 服务器上,作用是拷贝 master 二进制日志;然后拥有最新数据的slave上生成差异中继日志,应用差异日志;最后在不停止SQL线程的情况下删除中继日志。
原理:
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)使其他的slave连接新的master进行复制;
(6)使其他的slave连接新的master进行复制;
mha需要解决的问题:
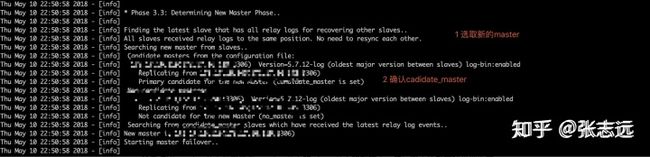
如何确定新的master:
由于 mysql 没有像 elasticsearch, etcd 这样分布式的集群决策节点,所以这里的 master 选举节点就是 mha manager节点,mha 主要参考几个因素:1 配置文件中手动配置的候选servers参数 **candidate_master=1**(如: 希望同机房,或则同机架的机器优先为 master), 2 依据各个 slave 中最新的二进制文件,最新的slave节点即可提升为master。
如何保证数据一致性:
mha 最大程度的保证数据不丢失,当 mysql master 异常时,但是机器正常提供服务,那么 mha 会去对比 master 节点与将成为 master 节点的 slave 节点的数据差,然后将差值数据拷贝到新的 slave,然后应用这部分数据差去补全数据。

如果是 mysql master 异常,机器也异常,那么系统中保存的二进制 binlog 文件也无法访问,这就没法拷贝,那么会略过拷贝流程,直接会从 salve 候选者中选取新的 master。如果使用 mysql 5.5 的半同步复制,可以大大降低数据丢失的风险。

节点之间数据如何拷贝:
由于 mysql 内部没有做这样的 bin-log 拷贝功能,所以我们有自定义的需求去实现复制。这里 mha 需要依赖 ssh 协议,就是通过 scp 协议传输文件(搭建 mha 需要保证各个主机间可以 ssh 互通)。

其他 slave 节点如何知道新的 master:
当候选 master 提升为 master 后,mha manager 会用 mysql change replication 的方式更改目前集群的所有 slave的同步源。
管理节点如何解决网络分区问题:
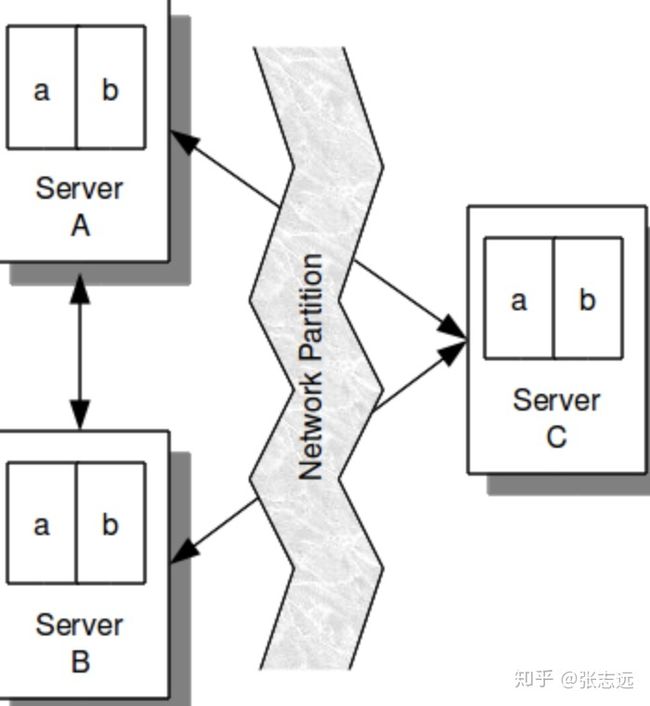
在上边的网络结构中,我们可以猜到系统可能存在一个很大问题,就是网络分区。网络分区指的是由于网络分离造成系统分裂为两个集群,各自相互不信任。对应无状态的系统,几乎没有影响,正常处理请求,比如nginx;数据系统出现分区问题时,如果系统设计或者配置存在不合理就会导致数据不一致,而这个问题修复起来会非常复杂,所以 elasticsearch , etcd, mongdb 等天生支持分布式的数据系统中,都有机制避免由于网络分区导致的数据不一致问题,解决方式是让集群大多数能正常通信的节点正常服务。比如你的集群是有 5 个节点,分区导致一个分区 2 个节点,一个分区 3 个,那么 2 个节点的分区就会被认为是异常的,不能正常提供服务,这里也会有一些特定的算法可以解决类似的问题,如raft。
比如下边这个图,3个节点,那么最少信任集群的节点数应该有2个,所以C节点会被标记为异常,不会正常提供服务
mha 的网络分区和上边提到的有点不同,由于集群只有一个 mha management(注意这里只能部署一个management,不允许部署多个,否则会出现异常),所以 mha management 不存在脑裂问题,这里指的网络分区指的 mha management 节点与 mysql master 节点出现分区,如下:
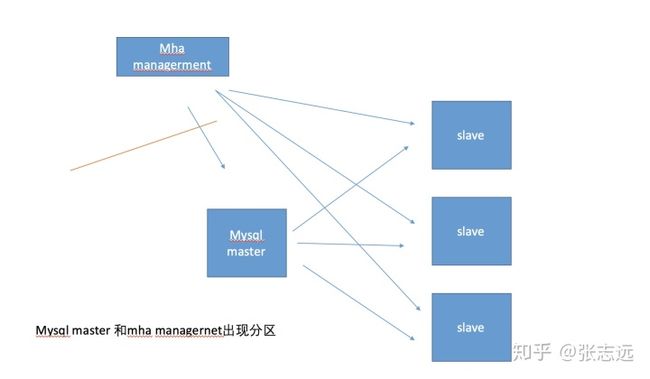
当 mha management 和 mysql master 出现在两个分区,mha 认为 mysql master 异常,但是实际 mysql master 和 mysql slave都正常工作,提供服务,但是这时候 mha 还是会切换 master,可能对应用程序来说(如果前端有负载均衡器),会出现2个master,而导致数据不一致。 面对这种情况,mha 提供了一种二次检测的方式,既多条链路检测,1 条链路是 mha management 是通过直接检测 mysql master节点, 2 其他链路是 mha managerment 通过ssh登录到其他 slave 的方式去检测 mysql master 是否正常,这样就能够解决 mha managerment 和 mysql master 的网络分区问题,防止误切换。
客户端应用自动恢复
一般来说自带 failover 的分布式系统系统都能够自己恢复服务,像elasticsearch , etcd, 他们客户端和集群都能够自动感知集群节点的变化,客户端连接的是一组集群地址,看下边示例,像 etcd 连接的服务端地址 Endpoints []string 是个数组,这就保证了当某个节点 ip 失效,或者机器不能访问,机器异常,机器负载的情况加, 都有其他节点进行处理,etcd连接如下:
cfg := client.Config {
Endpoints: []string{" http:// 127.0.0.1:2379 "},
Transport: client.DefaultTransport, // set timeout per request to fail fast when the target endpoint is unavailable
HeaderTimeoutPerRequest: time.Second,
}
然而像 mysql 默认的连接方式,应用 tomcat 或其他 client 连接数据库的默认的方式是mysql 驱动,就没法连接一个数组。所以我们的解决方案是要减少客户端感知,减少逻辑变更,让客户端和原来一样只需要连接一个 ip就好,这里的 ip是 proxy ip, 这里会有多种方式(这里不考虑分片和其他高级的路由,只考虑对应用连接,proxy的高可用方式可以通过keepalived来配合做互备)
- 七层支持mysql协议的proxy:
- mycat
- kingshard
- Atlas
- vitess
- phxsql
- MaxScale
通过代理的方式对客户端体验最好,原理上是 proxy 解析了mysql协议,然后根据不同的库,表,请求类型路由(读写分离)到后端合适的 mysql 服务器,但是因为加了这样一个 7 层的proxy解析, 所以性能会损失,一般在 20% 左右,上边的各个 proxy 会有各自的优势,和功能,详情可以去看看相关对比,我们需要做的就是在 proxy 后端配置我们的服务应用组,配置读写分离,当 master异常,能够切换。
- 4层proxy
- lvs
- haproxy
4层 proxy 就不会解析出 mysql 7层 协议,只能解析4层,所以保证 mysql 后端端口通就可以了,就是检测到后端master 不可用的时候,切换到 backup master,由于是 4层协议 所以不能配置自动读写分离,只能单独配置 master 端口,slave 端口了(如果配置keepalived可以自定义有脚本可以进行切换,自定义脚本可以配置主从同步延时)
- 直接使用vip
- 脚本配置vip
- keepalived配置vip
最后这个方式逻辑就是:
手动配置vip: 在 master 机器上配置虚拟vip,当mysql master异常,mha management 通过配置的 master_ip_online_change_script 的脚本,当 master 异常的时候,利用该脚本在新的 slave 上启动新的 ip,这样对客户端来说也是无影响的,配置vip比较容易
关于配置流程[配置流程](https://www.cnblogs.com/gomysql/p/3675429.html),这里说的很清楚了,我就不详细解析了。
我们生产环境实际上是使用maxscale,利用它来进行读写分离,他的文档特别全面,我们选用他的原因是他稳定高效,能无缝配合 mha,不需要 mha 配置任何 ip 切换之类的逻辑,当 mha 进行切换后,maxscale 会自动的进行感知系统中 servres 的角色,master切换它能感知到,对应用是完全无影响,如下图:

总结:
这里解决的是 mysql 原官方社区版的高可用问题,利用 mha + maxscale 的方式,该方案能以最小的代价对现有系统进行变更,提高系统的可用性和稳定性。前面提到以前版本(5.7以前) mysql 对集群化支持相对较弱,但是其实 mysql 也一直在发展,社区也开发出了很多方案,像PhxSQL,Percona XtraDB Cluster,MariaDB Galera Cluster,mysql 官方也开发出了使用 MySQL Group Replication的GA,来使用分布式协议来解决数据一致性问题了,非常期待未来越来越多的解决方案被提出,来更好的解决mysql高可用问题。