ResNet详解以及Tensorflow2实现(resnet_v1/v2_34/50/101)
ResNet_Tensorflow2实现
ResNet引入
在VGG-19中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。
网络层数越高包含的函数空间也就越大,理论上网络的加深会让模型更有可能找到合适的函数。
但实际上,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题
- 计算资源的消耗
- 模型容易过拟合
- 梯度消失/梯度爆炸问题的产生
根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
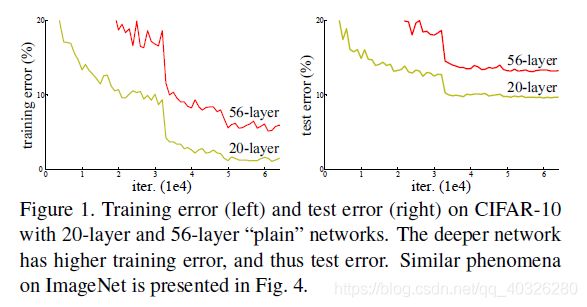
作者发现,随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
当网络退化时,浅层网络能够达到比深层网络更好的训练效果,这时如果我们把低层的特征传到高层,那么效果应该至少不比浅层的网络效果差,或者说如果一个VGG-100网络在第98层使用的是和VGG-16第14层一模一样的特征,那么VGG-100的效果应该会和VGG-16的效果相同。所以,我们可以在VGG-100的98层和14层之间添加一条直接映射(Identity Mapping)来达到此效果。
从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 l + 1 l+1 l+1 层的网络一定比 l l l 层包含更多的图像信息。
基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。

ResNet是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。

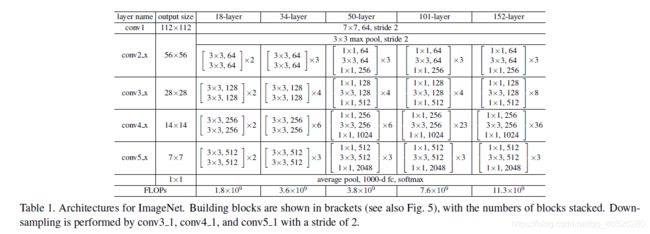
ResNet结构
import tensorflow as tf
import numpy as np
from tensorflow.keras import layers, Model, Sequential
定义BasicBlock和Bottleneck(ResNet50/101/152)
class BasicBlock(layers.Layer):
expansion = 1
def __init__(self, out_channel, strides=1, down_sample=None, **kwargs):
super(BasicBlock, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(out_channel, kernel_size=3, strides=strides, padding='SAME', use_bias=False, name='conv1')
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv1/BatchNorm')
# ------------------------------------------------------------------
self.conv2 = layers.Conv2D(out_channel, kernel_size=3, strides=1, padding='SAME', use_bias=False, name='conv2')
self.bn2 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv2/BatchNorm')
# ------------------------------------------------------------------
self.down_sample = down_sample
self.add = layers.Add()
self.relu = layers.ReLU()
def call(self, inputs, training=False):
if self.down_sample is not None:
identity = self.down_sample(inputs)
else:
identity = inputs
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x, training=training)
x = self.add([identity, x])
x = self.relu(x)
return x
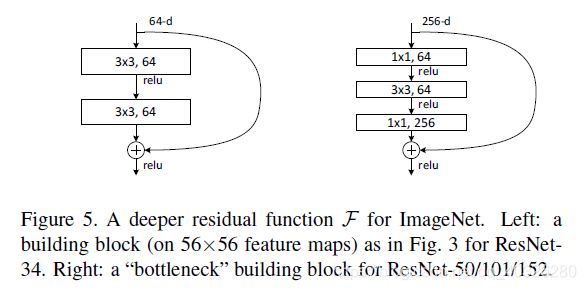
class Bottleneck(layers.Layer): # 瓶颈 两边粗中间细
expansion = 4
def __init__(self, out_channel, strides=1, down_sample=None, **kwargs):
super(Bottleneck, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(out_channel, kernel_size=1, use_bias=False, name='conv1')
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv1/BatchNorm')
# ------------------------------------------------------------------
self.conv2 = layers.Conv2D(out_channel, kernel_size=3, strides=strides, padding='SAME', use_bias=False, name='conv2')
self.bn2 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)
# ------------------------------------------------------------------
self.conv3 = layers.Conv2D(out_channel*self.expansion, kernel_size=1, use_bias=False, name='conv3')
self.bn3 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv3/BatchNorm')
# ------------------------------------------------------------------
self.down_sample = down_sample
self.add = layers.Add()
self.relu = layers.ReLU()
def call(self, inputs, training=False):
if self.down_sample is not None:
identity = self.down_sample(inputs)
else:
identity = inputs
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x, training=training)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x, training=training)
x = self.add([identity, x])
x = self.relu(x)
return x
在block之间衔接处,由于feature map的尺寸不一致,所以需要进行下采样的操作。论文中是通过 1 × 1 , s t r i d e s = 2 1\times 1 , strides=2 1×1,strides=2的卷积实现的。
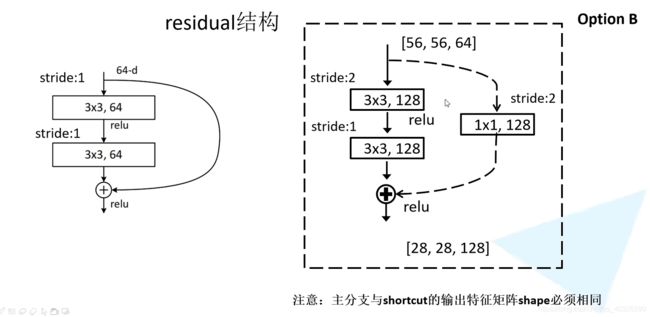
在resnet50/101/152中结构稍微有一些不同

class ResNet(Model):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True, **kwargs):
super(ResNet, self).__init__(**kwargs)
self.include_top = include_top
self.conv1 = layers.Conv2D(filters=64, kernel_size=7, strides=2, padding='SAME', use_bias=False, name='conv1')
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv1/BatchNorm')
self.relu1 = layers.ReLU(name='relu1')
# ------------------------------------------------------------------
self.maxpool1 = layers.MaxPool2D(pool_size=3, strides=2, padding='SAME', name='maxpool1')
# ------------------------------------------------------------------
self.block1 = self._make_layer(block, True, 64, blocks_num[0], name='block1')
self.block2 = self._make_layer(block, False, 128, blocks_num[1], strides=2, name='block2')
self.block3 = self._make_layer(block, False, 256, blocks_num[2], strides=2, name='block3')
self.block4 = self._make_layer(block, False, 512, blocks_num[3], strides=2, name='block4')
# ------------------------------------------------------------------
if self.include_top == True:
self.avgpool = layers.GlobalAveragePooling2D(name='avgpool1')
self.fc = layers.Dense(num_classes, name='logits')
self.softmax = layers.Softmax()
def call(self, inputs, training=False, **kwargs):
x = self.conv1(inputs)
x = self.bn1(x)
x = self.relu1(x)
x = self.maxpool1(x)
x = self.block1(x, training=training)
x = self.block2(x, training=training)
x = self.block3(x, training=training)
x = self.block4(x, training=training)
if self.include_top == True:
x = self.avgpool(x)
x = self.fc(x)
x = self.softmax(x)
return x
def _make_layer(self, block, first_block, channel, block_num, name=None, strides=1):
down_sample = None
if strides != 1 or first_block is True:
down_sample = Sequential([
layers.Conv2D(channel*block.expansion, kernel_size=1, strides=strides, use_bias=False, name='conv1'),
layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='BatchNorm')
], name='shortcut')
layers_list = []
layers_list.append(block(channel, down_sample=down_sample, strides=strides, name="unit_1"))
for index in range(1, block_num):
layers_list.append(block(channel, name='unit_' + str(index + 1)))
return Sequential(layers_list, name=name)
resnet_block_v2
最初的resnet残差块可以详细展开如Fig.4(a),即在卷积之后使用了BN做归一化,然后在和直接映射单位加之后使用了ReLU作为激活函数。
Fig.4(c)反应到网络里即将激活函数移到残差部分使用,这种在卷积之后使用激活函数的方法叫做post-activation。然后,作者通过调整ReLU和BN的使用位置得到了几个变种,即Fig.4(d)中的ReLU-only pre-activation和Fig.4(e)中的 full pre-activation。
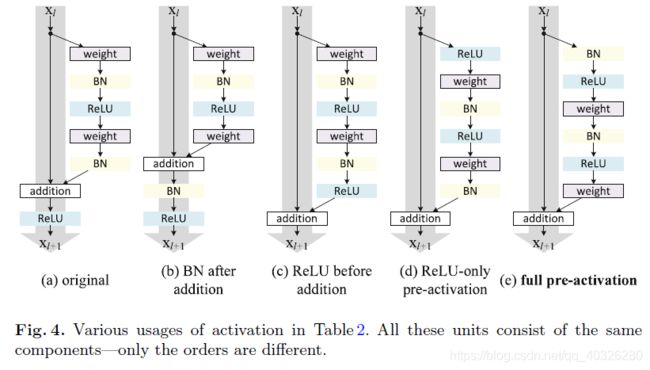
作者通过对照试验对比了这几种变异模型,结果见Tabel 2。

搭建resnet_block_v2
# (e)full pre-activation
class BasicBlock_v2(layers.Layer):
expansion = 1
def __init__(self, out_channel, strides=1, down_sample=None, **kwargs):
super(BasicBlock_v2, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(out_channel, kernel_size=3, strides=strides, padding='SAME', use_bias=False, name='conv1')
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv1/BatchNorm')
# ------------------------------------------------------------------
self.conv2 = layers.Conv2D(out_channel, kernel_size=3, strides=1, padding='SAME', use_bias=False, name='conv2')
self.bn2 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv2/BatchNorm')
# ------------------------------------------------------------------
self.down_sample = down_sample
self.add = layers.Add()
self.relu = layers.ReLU()
def call(self, inputs, training=False):
if self.down_sample is not None:
identity = self.down_sample(inputs)
else:
identity = inputs
# v2
x = self.bn1(inputs, training=training)
x = self.relu(x)
x = self.conv1(x)
x = self.bn2(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.add([identity, x])
return x
class Bottleneck_v2(layers.Layer): # 瓶颈 两边粗中间细
expansion = 4
def __init__(self, out_channel, strides=1, down_sample=None, **kwargs):
super(Bottleneck_v2, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(out_channel, kernel_size=1, use_bias=False, name='conv1')
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv1/BatchNorm')
# ------------------------------------------------------------------
self.conv2 = layers.Conv2D(out_channel, kernel_size=3, strides=strides, padding='SAME', use_bias=False, name='conv2')
self.bn2 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)
# ------------------------------------------------------------------
self.conv3 = layers.Conv2D(out_channel*self.expansion, kernel_size=1, use_bias=False, name='conv3')
self.bn3 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='conv3/BatchNorm')
# ------------------------------------------------------------------
self.down_sample = down_sample
self.add = layers.Add()
self.relu = layers.ReLU()
def call(self, inputs, training=False):
if self.down_sample is not None:
identity = self.down_sample(inputs)
else:
identity = inputs
# v2
x = self.bn1(inputs, training=training)
x = self.relu(x)
x = self.conv1(x)
x = self.bn2(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.bn3(x, training=training)
x = self.relu(x)
x = self.conv3(x)
x = self.add([identity, x])
return x
下面定义了resnet_v1版本34/50/101三种深度的网络模型:
def resnet_34(num_classes=1000, include_top=True):
block = BasicBlock
block_num = [3, 4, 6, 3]
return ResNet(block, block_num, num_classes, include_top)
def resnet_50(num_classes=1000, include_top=True):
block = Bottleneck
blocks_num = [3, 4, 6, 3]
return ResNet(block, blocks_num, num_classes, include_top)
def resnet_101(num_classes=1000, include_top=True):
block = Bottleneck
blocks_num = [3, 4, 23, 3]
return ResNet(block, blocks_num, num_classes, include_top)
下面定义了resnet_v2版本34/50/101三种深度的网络模型:
def resnet_v2_34(num_classes=1000, include_top=True):
block = BasicBlock_v2
block_num = [3, 4, 6, 3]
return ResNet(block, block_num, num_classes, include_top)
def resnet_v2_50(num_classes=1000, include_top=True):
block = Bottleneck_v2
blocks_num = [3, 4, 6, 3]
return ResNet(block, blocks_num, num_classes, include_top)
def resnet_v2_101(num_classes=1000, include_top=True):
block = Bottleneck_v2
blocks_num = [3, 4, 23, 3]
return ResNet(block, blocks_num, num_classes, include_top)
主函数模型测试部分(每个实测通过):
def main():
# model = resnet_34(num_classes=1000, include_top=True)
# model = resnet_50(num_classes=1000, include_top=True)
# model = resnet_101(num_classes=1000, include_top=True)
# model = resnet_v2_34(num_classes=1000, include_top=True)
# model = resnet_v2_50(num_classes=1000, include_top=True)
model = resnet_v2_101(num_classes=1000, include_top=True)
x_data = np.random.rand(4, 3, 224, 224).astype(np.float32)
x_label = np.random.rand(4, 1, 224, 224).astype(np.int64)
model.build((None, 3, 224, 224))
model.trainable = False
model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
model.summary()
pred = model.predict(x_data)
print("input shape:", x_data.shape)
print("output shape:", pred.shape)
if __name__ == '__main__':
main()
Model: "res_net_21"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv2D) multiple 702464
_________________________________________________________________
conv1/BatchNorm (BatchNormal multiple 256
_________________________________________________________________
relu1 (ReLU) multiple 0
_________________________________________________________________
maxpool1 (MaxPooling2D) multiple 0
_________________________________________________________________
block1 (Sequential) (None, 1, 56, 256) 217856
_________________________________________________________________
block2 (Sequential) (None, 1, 28, 512) 1225728
_________________________________________________________________
block3 (Sequential) (None, 1, 14, 1024) 26161152
_________________________________________________________________
block4 (Sequential) (None, 1, 7, 2048) 14983168
_________________________________________________________________
avgpool1 (GlobalAveragePooli multiple 0
_________________________________________________________________
logits (Dense) multiple 2049000
_________________________________________________________________
softmax_20 (Softmax) multiple 0
=================================================================
Total params: 45,339,624
Trainable params: 0
Non-trainable params: 45,339,624
_________________________________________________________________
WARNING:tensorflow:11 out of the last 11 calls to .predict_function at 0x0000024FDB34EC18> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.
input shape: (4, 3, 224, 224)
output shape: (4, 1000)