11-selenium浏览器自动化
selenium
- 概念:
- Selenium 是一个 Web 应用的自动化框架
- 自动化:通过它,我们可以写出自动化程序,像人一样在浏览器里操作web界面。 比如点击界面按钮,在文本框中输入文字 等操作,还能从web界面获取信息。 比如获取12306票务信息,招聘网站职位信息,财经网站股票价格信息 ,以及滑动模块验证码滑动等等,然后用程序进行分析处理。
- Selenium 的自动化原理
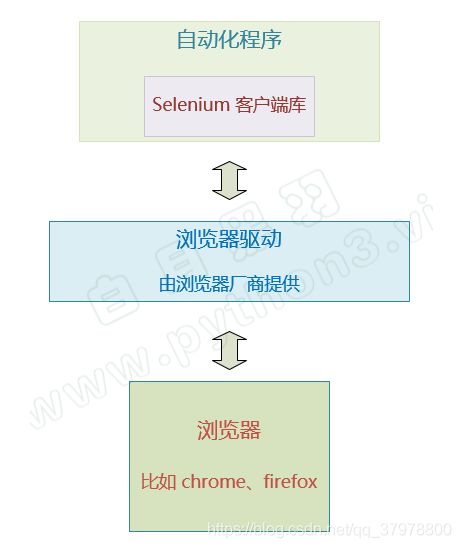
- selenium的安装
- pip install selenium
- 安装浏览器驱动
- 浏览器驱动 是和 浏览器对应的,不同的浏览器 需要选择不同的浏览器驱动目前主流的浏览器中, Chrome 浏览器对Selenium自动化的支持更加成熟一些。
我们就以Chrome浏览器为例下载url如下:
- https://chromedriver.storage.googleapis.com/index.html

- 比如:当前Chrome浏览器版本是72, 通常就需要下载72开头的目录里面的驱动程序 。- 注意:驱动和浏览器的版本号越接近越好,但是略有差别(比如72和73),通常也没有什么问题.
- 比如,解压到 d:\webdrivers 目录下面,也就是保证我们的Chrome浏览器驱动路径为 d:\webdrivers\chromedriver.exe
# -*- coding: utf-8 -*-
from selenium import webdriver
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com')
如果我们直接把驱动程序放到python安装目录下就不需要指定驱动路径了

selenium和爬虫之间的关联
1,便捷的捕获到任意形式的动态加载数据(可见即可得)
- 2,实现模拟登录jd
- 标签定位使用xpath表达式进行定位,也可使用css(根据id,class等进行定位)

- 标签定位使用xpath表达式进行定位,也可使用css(根据id,class等进行定位)
# -*- coding: utf-8 -*-
from selenium import webdriver
wd = webdriver.Chrome()# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://www.jd.com')# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
search = wd.find_element_by_xpath('//*[@id="key"]') #定位到搜索框
search.send_keys('macbook pro') # 模拟输入搜索的内容
btn = wd.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()#模拟点击搜索按钮
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
wd = webdriver.Chrome()# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://www.jd.com')# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.implicitly_wait(5) #静默等待最大5秒,保证页面加载完毕
search = wd.find_element_by_xpath('//*[@id="key"]') #定位到搜索框
search.send_keys('macbook pro') # 模拟输入搜索的内容
btn = wd.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()#模拟点击搜索按钮
time.sleep(2)#等待2秒执行下面操作
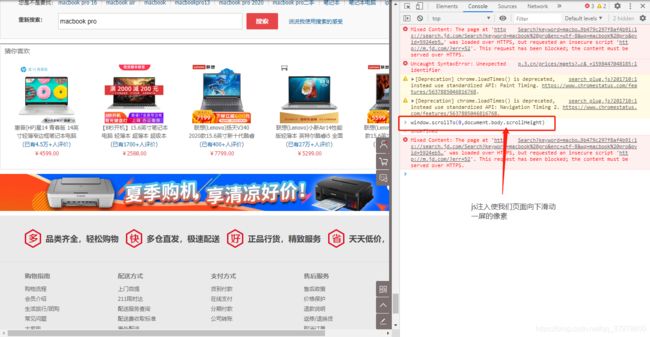
#在搜索结果页面进行滚轮向下滑动的操作(执行js操作:js注入)
wd.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2) #为了看见滑动效果我们可以等待2秒
wd.quit()#关闭浏览器
爬虫展示
3 使用selenium爬取jd商城数据(该案例翻页效果失败)
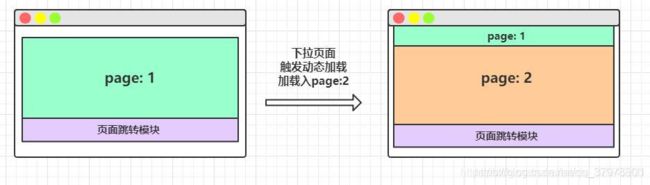
- 仔细分析京东的页面后发现,京东的页面是分两段动态生成的,先显示一半的结果,当你下拉页面后,再显示后一半的结果
- 每次下拉一半时,都会生成一个新的s_new.php?..,同时请注意请求参数中的 page 数的变化情况
- 由此可以得出,网页中的一页,实际上是 2 个 page 组成的,那么出现这样的错误就可以解释了
- 当刚刚加载出页面时,此时页面中只有 page: 1,而整个页面框架也刚刚加载出来,所以此时的页面跳转模块在page:1的下面,而当selenium选择页面跳转模块时,页面就已经滚动到下方了,于是Ajax又动态加载了page: 2,页面因此发生了改变,所以原先选择的元素就失效了
-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 键盘按键操作库
import time
# 1,模拟用户访问网址
def spider(url,keyword):
driver = webdriver.Chrome()# 定义浏览器
driver.get(url)
driver.maximize_window() # 窗口最大化
driver.implicitly_wait(5) # 隐式等待,确保所有节点完全加载出来
try:
input_tag = driver.find_element_by_id('key') # 定位搜索栏 输入口罩
input_tag.send_keys(keyword) # 模拟键盘输入
input_tag.send_keys(Keys.ENTER) # 回车键
time.sleep(5) #等待5秒时间
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')#滑动到最底部
get_goods(driver)
finally:
driver.close() # 不管有没有异常,都执行
# 2.定位商品数据抓取
def get_goods(driver):
try:
goods = driver.find_elements_by_class_name('gl-item')
for good in goods: # 商品名字 连接 价格 评论
detail_url = good.find_element_by_tag_name('a').get_attribute('href')
p_name = good.find_element_by_css_selector('.p-name em').text.replace('\n','') # 抓取名字
price = good.find_element_by_css_selector('.p-price i').text # 价格
p_commint = good.find_element_by_css_selector('.p-commit a').text # 获取评论
msg = """
商品:%s
连接:%s
价格:%s
评论:%s
"""%(p_name,detail_url,price,p_commint)
print(msg)
with open('jd.txt','a',encoding= " utf-8") as jdf:
jdf.write(msg)
print("打印完毕")
except Exception:
pass
# 3,抓取大量数据 (翻页)
try:
button = driver.find_element_by_link_text('下一页 ')
button.click()
time.sleep(5)
get_goods(driver) #调用抓取数据的函数
except Exception:
pass
if __name__=='__main__': # 标准写法,用于判断文件程序入口
spider("https://www.jd.com/",keyword='macbook pro')


号码爬取带自动翻页
import time
from selenium import webdriver # 调用实例化模块
# #创建web实例化启动浏览器
def spider(url):
try:
wd = webdriver.Chrome()
# 访问网站
wd.get(url)
wd.implicitly_wait(5) # 隐式等待
phones1(wd)
except Exception:
pass
def phones1(wd):
try:
phones = wd.find_elements_by_class_name('r-left')
for phone in phones:
yzc = phone.text
print(yzc)
with open('yzc2.txt', 'a', encoding="utf-8") as yzcf:
yzcf.write(yzc + "\n")
print("打印完毕")
except Exception:
pass
try:
wd.find_element_by_link_text('下一页').click()
time.sleep(2)
phones1(wd)
except Exception:
pass
if __name__ == '__main__':
spider('https://ketangsadas.aboatedu.com/question/comQuestionIndex')
电话号码注册判断
注意:仅供参考请不要尝试去暴力破解,爬虫学得好,牢饭管到饱
### 注意:仅供参考请不要尝试去暴力破解,爬虫学得好,牢饭管到饱 ######
import time
from selenium import webdriver # 调用实例化模块
wd = webdriver.Chrome()#创建web实例化启动浏览器
wd.get('https://ketandsadasg.aboatedu.com/login/forget?method=phone')# 访问网站
wd.implicitly_wait(5) # 隐式等待最大5秒
def a(phones1):
element = wd.find_element_by_id('mobile') # 定位到输入框
element.send_keys(phones1) #模拟输入电话号码
wd.find_element_by_id('nextStep').click() # 点击下一步判断是否注册
# time.sleep(1) #间隔时间一秒
try:
elements = wd.find_element_by_css_selector('#mobileTips')
register = elements.text
print(register)
wd.find_element_by_id('mobile').clear()#清空输入框
with open('result.txt', 'a', encoding="utf-8") as yzcf:
yzcf.write((phones1 + register).replace('\n', ' ') + "\n")
print("打印完毕")
except Exception:
pass
def b():
phone = open("phones.txt", mode="r", encoding=" utf-8") # 打开电话号码txt
for phones1 in phone: # 循环电话号码
time.sleep(1)
print( phones1)
a(phones1)
if __name__ == '__main__':
b()


动作链 Action Chains
- 动作链:一系列连续的动作(如滑动操作)

# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
url = "https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"
bro = webdriver.Chrome()
bro.get(url)
time.sleep(1)
# 如果通过find系列的函数进行标签定位,如果标签存在iframe嵌套里面,则会定位失败
# 解决方案:使用switch_to 即可
bro.switch_to.frame("iframeResult") # 进入frame嵌套
div_tag = bro.find_element_by_xpath('//*[@id="draggable"]')
# 对div_tag进行滑动操作
action = ActionChains(bro)
action.click_and_hold(div_tag) # 点击且长按不放
for i in range(6):
# perform 让动作链立即执行
action.move_by_offset(10,15).perform() #偏移x10像素,y15像素
time.sleep(0.5)
action.release()
bro.quit()

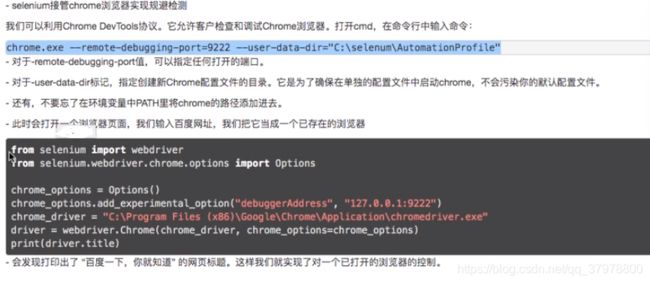

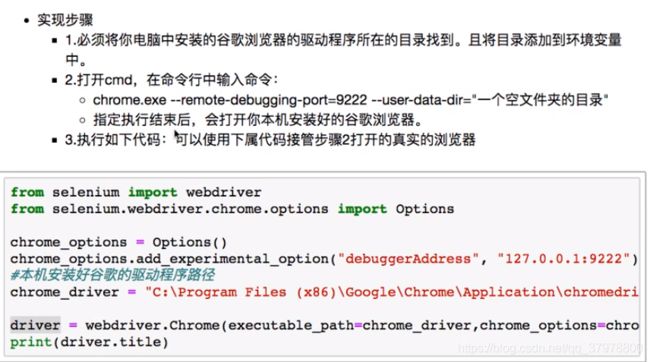
无头浏览器
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#这个是一个用来控制chrome以无界面模式打开的浏览器
#创建一个参数对象,用来控制chrome以无界面的方式打开
chrome_options = Options()
#后面的两个是固定写法 必须这么写
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#驱动路径 谷歌的驱动存放路径
path = r'C:\python\chromedriver.exe'
#创建浏览器对象
browser = webdriver.Chrome(executable_path=path,chrome_options=chrome_options)
#访问
url ='http://www.jd.com/'
gpc = browser.get(url)
time.sleep(3)
#截图
browser.save_screenshot('baid.png')
print(browser.page_source)
browser.quit()
Selenium WebDriver-网页的前进、后退、刷新、最大化、获取窗口位置、设置窗口大小、获取页面title、获取网页源码、获取Url等基本操作
通过selenium webdriver操作网页前进、后退、刷新、最大化、获取窗口位置、设置窗口大小、获取页面title、获取网页源码、获取Url等基本操作
from selenium import webdriver
driver = webdriver.Ie(executable_path = "e:\\IEDriverServer") #打开浏览器
driver.get("http://wenku.baidu.com") #输入网址
driver.back() #向后退
driver.forward() #向前进
driver.refresh() #刷新页面
driver.set_page_load_timeout(2) #设置超时等待的时间,超过不再等待
try: #捕获超时异常
driver.get("http://www.sohu.com")
... except Exception,e:
... print e
...
Message: Timed out waiting for page to load.
driver.maximize_window() #窗口最大化
driver.get_window_position() #获取坐标位置
{
'y': -8, 'x': 1672}
driver.name #判断使用的浏览器
u'internet explorer'
driver.set_window_position(y=200, x=400) #设置浏览器坐标
#y:指的上下走,屏幕最顶部y=0 ;x:指的左右走 ,最左边x=0,不再当前屏幕的会出现负数
#浏览器最大化的状态再去设置坐标就不起作用了
driver.get_window_position()['x'] #获取x轴的位置
2335
driver.get_window_position()['y'] #获取y轴的位置
98
driver.get_window_size() #获取浏览器的窗体大小
{
'width': 160, 'height': 32}
driver.get_window_size()['width'] #获取浏览器的宽度
160
driver.get_window_size()['height'] #获取浏览器的高度
32
driver.set_window_size(100,200) #设置浏览器的窗体大小
print driver.title #获取页面title,可以用于做断言看打开的页面对不对
搜狐
assert u"搜狐" == driver.title #断言标题是否正确
assert u"搜狐2" == driver.title #断言标题出错
Traceback (most recent call last):
File "" , line 1, in <module>
AssertionError
driver.page_source() #获取网页源码,返回的其实是unicode字符串
#抓取页面源码时,webdriver可以触犯页面上的js动态数据,但是它的缺点是比较慢;之前讲过的
#request抓取源码快,但只适用于静态页面,无法抓取js的动态页面内容
#抓取源码是非常重要的,可以随意操作
driver = webdriver.Ie(executable_path = "e:\\IEDriverServer")
driver.get("http://www.iciba.com")
driver.page_source[:50] #获取第50行的页面源码
u'"热门词汇" in driver.page_source #判断指定字段是不是在页面源码中存在
True
driver.page_source.encode("gbk","ignore") #将页面源码转码成中文,加ignore避免无法识别的生僻
字报错
html=driver.page_source.encode("gbk","ignore") #将页面源码转成html文件
>>> with open("e:\\1.html","w"):
... pass
...
>>> with open("e:\\1.html","w") as fp:
... fp.write(html)
...
driver.current_url #获取当前页面的url
u'http://www.iciba.com/
重点
一、 根据tag名、id、class选择元素
二、根据css选择元素
三、页面嵌套frame元素切换/窗口切换, frame 或者iframe元素内部会包含一个被嵌入的另一份html文档
四、selenium 选取选择框
五、更多操作技巧
六、Xpath 选择器等
selenium成神链接:https://download.csdn.net/download/qq_37978800/12715808