人工智能-深度学习-神经网络:CNN经典模型【LeNet5、AlexNet 、VGG、GoogleNet、ResNet、DenseNet、ResNeXt、DPN、SENet】
一、LeNet5 (1998年)
- LeNet是卷积网络做识别的开山之作,虽然LeNet5的网络结构现在已经很少使用,但是它对后续卷积网络的发展起到了奠基作用,打下了很好的理论基础。
- LeNet-5是卷积网络的开上鼻祖,它是用来识别手写邮政编码的,论文可以参考Haffner. Gradient-based learning applied to document recognition.
- LeNet5 这个网络虽然很小,但是它包含了神经网络的基本模块:卷积层,池化层,全链接层。是其他神经网络模型的基础。
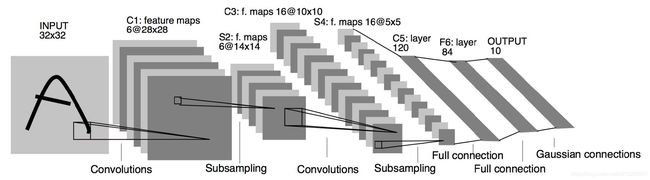
- 大名鼎鼎的LeNet5诞生于1994年,是最早的深层卷积神经网络之一,并且推动了深度学习的发展。
- 从1988年开始,在多次成功的迭代后,这项由Yann LeCun完成的开拓性成果被命名为LeNet5。
- LeCun认为,可训练参数的卷积层是一种用少量参数在图像的多个位置上提取相似特征的有效方式,这和直接把每个像素作为多层神经网络的输入不同。像素不应该被使用在输入层,因为图像具有很强的空间相关性,而使用图像中独立的像素直接作为输入则利用不到这些相关性。
- LeNet-5 共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
- LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。
- 卷积神经网络能够很好的利用图像的结构信息。
- 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
- LeNet-5的特点:
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征
- 降采样(Subsample)的平均池化层(Average Pooling)
- 双曲正切(Tanh)或S型(Sigmoid)的激活函数 MLP作为最后的分类器
- 层与层之间的稀疏连接减少计算复杂度
1、INPUT层-输入层
- 首先是数据 INPUT 层,输入图像的尺寸统一归一化为32×32。
- 注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
- 输入图片: 32 × 32 32×32 32×32
- 卷积核大小: 5 × 5 5×5 5×5
- 卷积核种类:6
- 输出featuremap大小: ( 32 − 5 + 1 ) × ( 32 − 5 + 1 ) = 28 × 28 (32-5+1)×(32-5+1) =28×28 (32−5+1)×(32−5+1)=28×28
- 神经元数量: 28 × 28 × 6 28×28×6 28×28×6
- 可训练参数: ( 5 × 5 + 1 ) × 6 (5×5+1)× 6 (5×5+1)×6(每个滤波器 5 × 5 = 25 5×5=25 5×5=25 个unit参数和一个bias参数,一共6个滤波器)
- 连接数: ( 5 × 5 + 1 ) × 6 × 28 × 28 = 122304 (5×5+1)×6×28×28=122304 (5×5+1)×6×28×28=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5 × 5 5×5 5×5 的卷积核),得到6个C1特征图(6个大小为28×28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5×5,总共就有6×(5×5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5×5个像素和1个bias有连接,所以总共有156×28×28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
- 输入:28×28
- 采样区域:2×2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:6
- 输出featureMap大小: 28 2 × 28 2 = 14 × 14 \cfrac{28}{2}×\cfrac{28}{2}=14×14 228×228=14×14
- 神经元数量:14×14×6
- 连接数:(2×2+1)×6×14×14
- S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 2×2核 进行池化,于是得到了S2,6个14×14的 特征图(28/2=14)。S2这个pooling层是对C1中的2×2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。同时有5x14x14x6=5880个连接。
4、C3层-卷积层
- 输入:S2中所有6个或者几个特征map组合
- 卷积核大小:5×5
- 卷积核种类:16
- 输出featureMap大小:10×10 (14-5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6×(3×5×5+1)+6×(4×5×5+1)+3×(4×5×5+1)+1×(6×5×5+1)=1516
连接数:10×10×1516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5×5. 我们知道S2 有6个 14×14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:

C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5×5,所以总共有6×(3×5×5+1)+6×(4×5×5+1)+3×(4×5×5+1)+1×(6×5×5+1)=1516个参数。而图像大小为10×10,所以共有151600个连接。
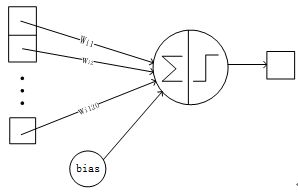
C3与S2中前3个图相连的卷积结构如下图所示:
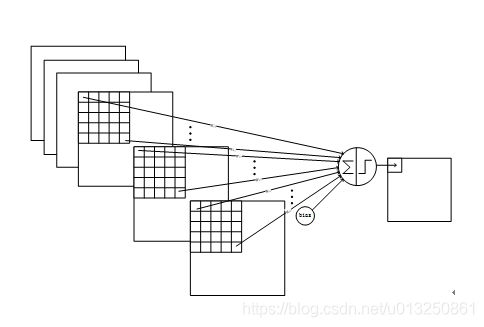
上图对应的参数为 3×5×5+1,一共进行6次卷积得到6个特征图,所以有6×(3×5×5+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(下采样层)
- 输入:10×10
- 采样区域:2×2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:16
- 输出featureMap大小:5×5(10/2)
- 神经元数量:5×5×16=400
- 连接数:16×(2×2+1)×5×5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是pooling层,窗口大小仍然是2×2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。有5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
- 输入:S4层的全部16个单元特征map(与s4全相连)
- 卷积核大小:5×5
- 卷积核种类:120
- 输出featureMap大小:1×1(5-5+1)
- 可训练参数/连接:120×(16×5×5+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:

7、F6层-全连接层
- 输入:c5 120维向量
- 计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
- 可训练参数:84×(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

F6层的连接方式如下:

8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
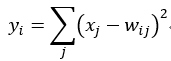
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7×12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。

上图是LeNet-5识别数字3的过程。
9、LeNet5案例-cifar10分类数据集
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
class Lenet5(nn.Module):
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] => [b, 16, *, *]
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# x: [b, 16, *, *] => [b, 32, *, *]
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
# flatten
self.fc_unit = nn.Sequential(
nn.Linear(32 * 5 * 5, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
batch_size = x.size(0) # [2000, 3, 32, 32]
x = self.conv_unit(x) # [b, 3, 32, 32] => [b, 32, 5, 5]
x = x.view(batch_size, 32 * 5 * 5) # [32, 16, 5, 5] => [b, 32*5*5]
logits = self.fc_unit(x) # [b, 16*5*5] => [b, 10]
return logits
def main():
batch_size = 5000
# 一、获取cifar10训练数据集
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
# 二、设置GPU
device = torch.device('cuda')
# 三、实例化Lenet5神经网络模型
model = Lenet5().to(device)
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 六、训练
for epoch in range(3):
# **********************************************************训练**********************************************************
print('**************************训练模式:开始**************************')
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(cifar_train):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch, batch_index, loss.item()))
print('**************************训练模式:结束**************************')
# **********************************************************模型评估**********************************************************
print('**************************验证模式:开始**************************')
model.eval() # 切换至验证模式
with torch.no_grad(): # torch.no_grad()所包裹的部分不需要参与反向传播
# test
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(cifar_test):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
acc = total_correct / total_num
print('epoch = {0}, batch_index = {1}, test acc = {2}'.format(epoch, batch_index, acc))
print('**************************验证模式:结束**************************')
if __name__ == '__main__':
main()
打印结果:
Files already downloaded and verified
Files already downloaded and verified
model = Lenet5(
(conv_unit): Sequential(
(0): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc_unit): Sequential(
(0): Linear(in_features=800, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=10, bias=True)
)
)
**************************训练模式:开始**************************
epoch = 0, batch_index = 0, loss.item() = 2.3143210411071777
epoch = 0, batch_index = 1, loss.item() = 2.287487268447876
epoch = 0, batch_index = 2, loss.item() = 2.2606987953186035
epoch = 0, batch_index = 3, loss.item() = 2.226912498474121
epoch = 0, batch_index = 4, loss.item() = 2.1867635250091553
epoch = 0, batch_index = 5, loss.item() = 2.1441078186035156
epoch = 0, batch_index = 6, loss.item() = 2.109809398651123
epoch = 0, batch_index = 7, loss.item() = 2.093820810317993
epoch = 0, batch_index = 8, loss.item() = 2.043757438659668
epoch = 0, batch_index = 9, loss.item() = 2.004603862762451
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 0, batch_index = 0, test acc = 0.2954
epoch = 0, batch_index = 1, test acc = 0.2912
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 1, batch_index = 0, loss.item() = 1.9749507904052734
epoch = 1, batch_index = 1, loss.item() = 1.9384398460388184
epoch = 1, batch_index = 2, loss.item() = 1.9332951307296753
epoch = 1, batch_index = 3, loss.item() = 1.9169594049453735
epoch = 1, batch_index = 4, loss.item() = 1.892669677734375
epoch = 1, batch_index = 5, loss.item() = 1.8858933448791504
epoch = 1, batch_index = 6, loss.item() = 1.857857584953308
epoch = 1, batch_index = 7, loss.item() = 1.8486536741256714
epoch = 1, batch_index = 8, loss.item() = 1.8345849514007568
epoch = 1, batch_index = 9, loss.item() = 1.808337688446045
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 1, batch_index = 0, test acc = 0.3732
epoch = 1, batch_index = 1, test acc = 0.3739
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 2, batch_index = 0, loss.item() = 1.7996269464492798
epoch = 2, batch_index = 1, loss.item() = 1.787319540977478
epoch = 2, batch_index = 2, loss.item() = 1.7761077880859375
epoch = 2, batch_index = 3, loss.item() = 1.7711927890777588
epoch = 2, batch_index = 4, loss.item() = 1.7415823936462402
epoch = 2, batch_index = 5, loss.item() = 1.7422986030578613
epoch = 2, batch_index = 6, loss.item() = 1.7195093631744385
epoch = 2, batch_index = 7, loss.item() = 1.7159980535507202
epoch = 2, batch_index = 8, loss.item() = 1.6884196996688843
epoch = 2, batch_index = 9, loss.item() = 1.6863059997558594
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 2, batch_index = 0, test acc = 0.408
epoch = 2, batch_index = 1, test acc = 0.4128
**************************验证模式:结束**************************
Process finished with exit code 0
二、AlexNet (2012年)
- 由于受到计算机性能的影响,虽然LeNet在图像分类中取得了较好的成绩,但是并没有引起很多的关注。直到 2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,卷积神经网络乃至深度学习重新引起了广泛的关注。
- AlexNet 结构已经过时,只学习其思想即可。
AlexNet是在LeNet的基础上加深了网络的结构,学习更丰富更高维的图像特征。AlexNet的特点:
- 更深的网络结构
- 使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
- 使用Dropout抑制过拟合
- 使用数据增强Data Augmentation抑制过拟合
- 使用Relu替换之前的sigmoid的作为激活函数
- 多GPU训练

1、Alex网络结构

上图中的输入是 224 × 224 224×224 224×224,不过经过计算(224−11)/4=54.75并不是论文中的55×55,而使用227×227作为输入,则(227−11)/4=55
网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布。
1.1 卷积层C1
该层的处理流程是: 卷积–>ReLU–>池化–>归一化。
- 卷积,输入是227×227,使用96个11×11×3的卷积核,得到的FeatureMap为55×55×96。
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
- 池化,使用3×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×96((55−3)/2+1=27)
- 局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48
1.2 卷积层C2
该层的处理流程是:卷积–>ReLU–>池化–>归一化
- 卷积,输入是2组27×27×48。使用2组,每组128个尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为27×27 times128. ((27+2∗2−5)/1+1=27)
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256
- 局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128
1.3 卷积层C3
该层的处理流程是: 卷积–>ReLU
卷积,输入是13×13×256,使用2组共384尺寸为3×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
1.4 卷积层C4
该层的处理流程是: 卷积–>ReLU
该层和C3类似。
- 卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384,分为两组,每组为13×13×192
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
1.5 卷积层C5
该层处理流程为:卷积–>ReLU–>池化
- 卷积,输入为13×13×384,分为两组,每组为13×13×192。使用2组,每组为128尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×256
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6,即池化后的输出为6×6×256
1.6 全连接层FC6
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
- 卷积->全连接: 输入为6×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。
- ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
1.7 全连接层FC7
流程为:全连接–>ReLU–>Dropout
- 全连接,输入为4096的向量
- ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
1.8 输出层
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
2、AlexNet参数数量
卷积层的参数 = 卷积核的数量 * 卷积核 + 偏置
- C1: 96个11×11×3的卷积核,96×11×11×3+96=34848
- C2: 2组,每组128个5×5×48的卷积核,(128×5×5×48+128)×2=307456
- C3: 384个3×3×256的卷积核,3×3×256×384+384=885120
- C4: 2组,每组192个3×3×192的卷积核,(3×3×192×192+192)×2=663936
- C5: 2组,每组128个3×3×192的卷积核,(3×3×192×128+128)×2=442624
- FC6: 4096个6×6×256的卷积核,6×6×256×4096+4096=37752832
- FC7: 4096∗4096+4096=16781312
- output: 4096∗1000=4096000
卷积层 C2,C4,C5中的卷积核只和位于同一GPU的上一层的FeatureMap相连。从上面可以看出,参数大多数集中在全连接层,在卷积层由于权值共享,权值参数较少。
三、VGG(2014年)
- 2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名,将 Top-5错误率降到7.3%(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。
- 它主要的贡献是展示出网络的深度(depth)是算法优良性能的关键部分。
- VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。
- 目前使用比较多的网络结构主要有ResNet(152-1000层),GooleNet(22层),VGGNet(19层),大多数模型都是基于这几个模型上改进,采用新的优化算法,多模型融合等。
- VGGNet可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
- VGG Net结构已经过时,只学习其思想即可。
- 不过,VGG Net 依然经常被用来提取图像特征。

- VGG神经网络提供了如下结论:
- 通过增加深度能有效地提升性能;
- 最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
- 卷积可代替全连接,可适应各种尺寸的图片
1、VGG的特点
1.1 结构简洁
- VGG由5层卷积层、3层全连接层、softmax输出层构成。层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
1.2 小卷积核和多卷积子层
- VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
- 小卷积核是VGG的一个重要特点,虽然VGG是在模仿AlexNet的网络结构,但没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。
- VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27),如下图所示:
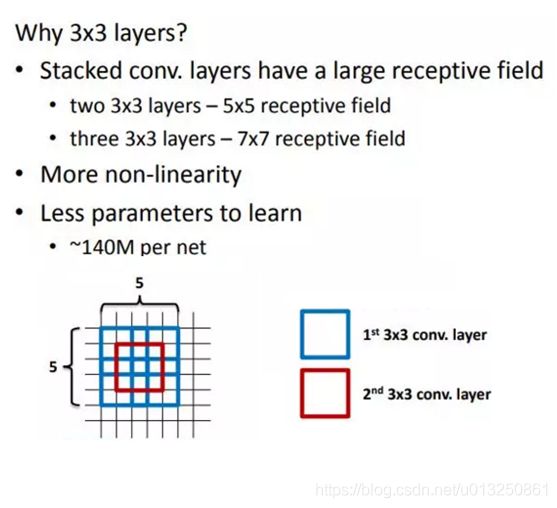
1.3 小池化核
- 相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
1.4 通道数多
- VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
1.5 层数更深、特征图更宽
- 由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
1.6 全连接转卷积(测试阶段)
- 这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
- 如本节第一个图所示,输入图像是224x224x3,如果后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。
- 而“全连接转卷积”,替换过程如下:

- 例如7x7x512的层要跟4096个神经元的层做全连接,则替换为对7x7x512的层作通道数为4096、卷积核为1x1的卷积。
- 这个“全连接转卷积”的思路是VGG作者参考了OverFeat的工作思路,例如下图是OverFeat将全连接换成卷积后,则可以来处理任意分辨率(在整张图)上计算卷积,这就是无需对原图做重新缩放处理的优势。

2、VGG的网络结构
- 下图是来自论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》(基于甚深层卷积网络的大规模图像识别)的VGG网络结构,正是在这篇论文中提出了VGG,如下图:

- 在这篇论文中分别使用了A、A-LRN、B、C、D、E这6种网络结构进行测试,这6种网络结构相似,都是由5层卷积层、3层全连接层组成,其中区别在于每个卷积层的子层数量不同,从A至E依次增加(子层数量从1到4),总的网络深度从11层到19层(添加的层以粗体显示),表格中的卷积层参数表示为“conv⟨感受野大小⟩-通道数⟩”,例如con3-128,表示使用3x3的卷积核,通道数为128。为了简洁起见,在表格中不显示ReLU激活功能。
- 其中,网络结构D就是著名的VGG16,网络结构E就是著名的VGG19。
- 以网络结构D(VGG16)为例,介绍其处理过程如下,请对比上面的表格和下方这张图,留意图中的数字变化,有助于理解VGG16的处理过程:
- 输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
- 作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
- 经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
- 作2x2的max pooling池化,尺寸变为56x56x128
- 经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
- 作2x2的max pooling池化,尺寸变为28x28x256
- 经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
- 作2x2的max pooling池化,尺寸变为14x14x512
- 经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
- 作2x2的max pooling池化,尺寸变为7x7x512
- 与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
- 通过softmax输出1000个预测结果
- 以上就是VGG16(网络结构D)各层的处理过程,A、A-LRN、B、C、E其它网络结构的处理过程也是类似,执行过程如下(以VGG16为例):

- A、A-LRN、B、C、D、E这6种网络结构的深度虽然从11层增加至19层,但参数量变化不大,这是由于基本上都是采用了小卷积核(3x3,只有9个参数),这6种结构的参数数量(百万级)并未发生太大变化,这是因为在网络中,参数主要集中在全连接层。

- 经作者对A、A-LRN、B、C、D、E这6种网络结构进行单尺度的评估,错误率结果如下:

- 从上表可以看出:
- LRN层无性能增益(A-LRN)
VGG作者通过网络A-LRN发现,AlexNet曾经用到的LRN层(local response normalization,局部响应归一化)并没有带来性能的提升,因此在其它组的网络中均没再出现LRN层。 - 随着深度增加,分类性能逐渐提高(A、B、C、D、E)
从11层的A到19层的E,网络深度增加对top1和top5的错误率下降很明显。 - 多个小卷积核比单个大卷积核性能好(B)
VGG作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5x5来代替B的两个conv3x3,结果显示多个小卷积核比单个大卷积核效果要好。
- LRN层无性能增益(A-LRN)
3、VGG案例-cifar100分类数据集
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 放在 import tensorflow as tf 之前才有效
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
# 一、获取数据集
(X_train, Y_train), (X_val, Y_val) = datasets.cifar100.load_data()
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
Y_train = tf.squeeze(Y_train)
Y_val = tf.squeeze(Y_val)
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
# 二、数据处理
# 预处理函数:将numpy数据转为tensor
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x, y
# 2.1 处理训练集
# print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
db_train = tf.data.Dataset.from_tensor_slices((X_train, Y_train)) # 此步骤自动将numpy类型的数据转为tensor
db_train = db_train.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
# 从data数据集中按顺序抽取buffer_size个样本放在buffer中,然后打乱buffer中的样本。buffer中样本个数不足buffer_size,继续从data数据集中安顺序填充至buffer_size,此时会再次打乱。
db_train = db_train.shuffle(buffer_size=1000) # 打散db_train中的样本顺序,防止图片的原始顺序对神经网络性能的干扰。
print('db_train = {0},type(db_train) = {1}'.format(db_train, type(db_train)))
batch_size_train = 2000 # 每个batch里的样本数量设置100-200之间合适。
db_batch_train = db_train.batch(batch_size_train) # 将db_batch_train中每sample_num_of_each_batch_train张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_train张图片
print('db_batch_train = {0},type(db_batch_train) = {1}'.format(db_batch_train, type(db_batch_train)))
# 2.2 处理测试集:测试数据集不需要打乱顺序
db_val = tf.data.Dataset.from_tensor_slices((X_val, Y_val)) # 此步骤自动将numpy类型的数据转为tensor
db_val = db_val.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
batch_size_val = 2000 # 每个batch里的样本数量设置100-200之间合适。
db_batch_val = db_val.batch(batch_size_val) # 将db_val中每sample_num_of_each_batch_val张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_val张图片
# 三、构建神经网络
# 1、卷积神经网络结构:Conv2D 表示卷积层,激活函数用 relu
conv_layers = [ # 5 units of conv + max pooling
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu), # 64个kernel表示输出的数据的channel为64,padding="same"表示自动padding使得输入与输出大小一致
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
# 2、全连接神经网络结构:Dense 表示全连接层,激活函数用 relu
fullcon_layers = [
layers.Dense(300, activation=tf.nn.relu), # 降维:512-->300
layers.Dense(200, activation=tf.nn.relu), # 降维:300-->200
layers.Dense(100) # 降维:200-->100,最后一层一般不需要在此处指定激活函数,在计算Loss的时候会自动运用激活函数
]
# 3、构建卷积神经网络、全连接神经网络
conv_network = Sequential(conv_layers) # [b, 32, 32, 3] => [b, 1, 1, 512]
fullcon_network = Sequential(fullcon_layers) # [b, 1, 1, 512] => [b, 1, 1, 100]
conv_network.build(input_shape=[None, 32, 32, 3]) # 原始图片维度为:[32, 32, 3],None表示样本数量,是不确定的值。
fullcon_network.build(input_shape=[None, 512]) # 从卷积网络传过来的数据维度为:[b, 512],None表示样本数量,是不确定的值。
# 4、打印神经网络信息
conv_network.summary() # 打印卷积神经网络network的简要信息
fullcon_network.summary() # 打印神经网络network的简要信息
# 四、梯度下降优化器设置
optimizer = optimizers.Adam(lr=1e-4)
# 五、整体数据集进行一次梯度下降来更新模型参数,整体数据集迭代一次,一般用epoch。每个epoch中含有batch_step_no个step,每个step中就是设置的每个batch所含有的样本数量。
def train_epoch(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_train): # 每次计算一个batch的数据,循环结束则计算完毕整体数据的一次梯度下降;每个batch的序号一般用step表示(batch_step_no)
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}------------type(X_batch) = {4},type(Y_batch) = {5}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape, type(X_batch), type(Y_batch)))
Y_batch_one_hot = tf.one_hot(Y_batch, depth=100) # One-Hot编码,共有100类 [] => [b,100]
print('\tY_train_one_hot.shpae = {0}'.format(Y_batch_one_hot.shape))
# 梯度带tf.GradientTape:连接需要计算梯度的”函数“和”变量“的上下文管理器(context manager)。将“函数”(即Loss的定义式)与“变量”(即神经网络的所有参数)都包裹在tf.GradientTape中进行追踪管理
with tf.GradientTape() as tape:
# Step1. 前向传播/前向运算-->计算当前参数下模型的预测值
out_logits_conv = conv_network(X_batch) # [b, 32, 32, 3] => [b, 1, 1, 512]
print('\tout_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_conv = tf.reshape(out_logits_conv, [-1, 512]) # [b, 1, 1, 512] => [b, 512]
print('\tReshape之后:out_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_fullcon = fullcon_network(out_logits_conv) # [b, 512] => [b, 100]
print('\tout_logits_fullcon.shape = {0}'.format(out_logits_fullcon.shape))
# Step2. 计算预测值与真实值之间的损失Loss:交叉熵损失
MSE_Loss = tf.losses.categorical_crossentropy(Y_batch_one_hot, out_logits_fullcon, from_logits=True) # categorical_crossentropy()第一个参数是真实值,第二个参数是预测值,顺序不能颠倒
print('\tMSE_Loss.shape = {0}'.format(MSE_Loss.shape))
MSE_Loss = tf.reduce_mean(MSE_Loss)
print('\t求均值后:MSE_Loss.shape = {0}'.format(MSE_Loss.shape))
print('\t第{0}个epoch-->第{1}个batch step的初始时的:MSE_Loss = {2}'.format(epoch_no, batch_step_no + 1, MSE_Loss))
# Step3. 反向传播-->损失值Loss下降一个学习率的梯度之后所对应的更新后的各个Layer的参数:W1, W2, W3, B1, B2, B3...
variables = conv_network.trainable_variables + fullcon_network.trainable_variables # list的拼接: [1, 2] + [3, 4] => [1, 2, 3, 4]
# grads为整个全连接神经网络模型中所有Layer的待优化参数trainable_variables [W1, W2, W3, B1, B2, B3...]分别对目标函数MSE_Loss 在 X_batch 处的梯度值,
grads = tape.gradient(MSE_Loss, variables) # grads为梯度值。MSE_Loss为目标函数,variables为卷积神经网络、全连接神经网络所有待优化参数,
# grads, _ = tf.clip_by_global_norm(grads, 15) # 限幅:解决gradient explosion或者gradients vanishing的问题。
# print('\t第{0}个epoch-->第{1}个batch step的初始时的参数:'.format(epoch_no, batch_step_no + 1))
if batch_step_no == 0:
index_variable = 1
for grad in grads:
print('\t\tgrad{0}:grad.shape = {1},grad.ndim = {2}'.format(index_variable, grad.shape, grad.ndim))
index_variable = index_variable + 1
# 进行一次梯度下降
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始')
optimizer.apply_gradients(zip(grads, variables)) # network的所有参数 trainable_variables [W1, W2, W3, B1, B2, B3...]下降一个梯度 w' = w - lr * grad,zip的作用是让梯度值与所属参数前后一一对应
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束\n')
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 六、模型评估 test/evluation
def evluation(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
total_correct, total_num = 0, 0
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_val):
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape))
# 根据训练模型计算测试数据的输出值out
out_logits_conv = conv_network(X_batch) # [b, 32, 32, 3] => [b, 1, 1, 512]
print('\tout_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_conv = tf.reshape(out_logits_conv, [-1, 512]) # [b, 1, 1, 512] => [b, 512]
print('\tReshape之后:out_logits_conv.shape = {0}'.format(out_logits_conv.shape))
out_logits_fullcon = fullcon_network(out_logits_conv) # [b, 512] => [b, 100]
print('\tout_logits_fullcon.shape = {0}'.format(out_logits_fullcon.shape))
# print('\tout_logits_fullcon[:1,:] = {0}'.format(out_logits_fullcon[:1, :]))
# 利用softmax()函数将network的输出值转为0~1范围的值,并且使得所有类别预测概率总和为1
out_logits_prob = tf.nn.softmax(out_logits_fullcon, axis=1) # out_logits_prob: [b, 100] ~ [0, 1]
# print('\tout_logits_prob[:1,:] = {0}'.format(out_logits_prob[:1, :]))
out_logits_prob_max_index = tf.cast(tf.argmax(out_logits_prob, axis=1), dtype=tf.int32) # [b, 100] => [b] 查找最大值所在的索引位置 int64 转为 int32
# print('\t预测值:out_logits_prob_max_index = {0},\t真实值:Y_train_one_hot = {1}'.format(out_logits_prob_max_index, Y_batch))
is_correct_boolean = tf.equal(out_logits_prob_max_index, Y_batch.numpy())
# print('\tis_correct_boolean = {0}'.format(is_correct_boolean))
is_correct_int = tf.cast(is_correct_boolean, dtype=tf.float32)
# print('\tis_correct_int = {0}'.format(is_correct_int))
is_correct_count = tf.reduce_sum(is_correct_int)
print('\tis_correct_count = {0}\n'.format(is_correct_count))
total_correct += int(is_correct_count)
total_num += X_batch.shape[0]
print('total_correct = {0}---total_num = {1}'.format(total_correct, total_num))
acc = total_correct / total_num
print('第{0}轮Epoch迭代的准确度: acc = {1}'.format(epoch_no, acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 七、整体数据迭代多次梯度下降来更新模型参数
def train():
epoch_count = 1 # epoch_count为整体数据集迭代梯度下降次数
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no)
evluation(epoch_no)
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
if __name__ == '__main__':
train()
打印结果:
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000, 1)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'numpy.ndarray'>
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000,)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'tensorflow.python.framework.ops.EagerTensor'>
db_train = <ShuffleDataset shapes: ((32, 32, 3), ()), types: (tf.float32, tf.int32)>,type(db_train) = <class 'tensorflow.python.data.ops.dataset_ops.ShuffleDataset'>
db_batch_train = <BatchDataset shapes: ((None, 32, 32, 3), (None,)), types: (tf.float32, tf.int32)>,type(db_batch_train) = <class 'tensorflow.python.data.ops.dataset_ops.BatchDataset'>
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 2, 2, 512) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 1, 1, 512) 0
=================================================================
Total params: 9,404,992
Trainable params: 9,404,992
Non-trainable params: 0
_________________________________________________________________
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 300) 153900
_________________________________________________________________
dense_1 (Dense) (None, 200) 60200
_________________________________________________________________
dense_2 (Dense) (None, 100) 20100
=================================================================
Total params: 234,200
Trainable params: 234,200
Non-trainable params: 0
_________________________________________________________________
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第1个batch step的初始时的:MSE_Loss = 4.605105400085449
grad1:grad.shape = (3, 3, 3, 64),grad.ndim = 4
grad2:grad.shape = (64,),grad.ndim = 1
grad3:grad.shape = (3, 3, 64, 64),grad.ndim = 4
grad4:grad.shape = (64,),grad.ndim = 1
grad5:grad.shape = (3, 3, 64, 128),grad.ndim = 4
grad6:grad.shape = (128,),grad.ndim = 1
grad7:grad.shape = (3, 3, 128, 128),grad.ndim = 4
grad8:grad.shape = (128,),grad.ndim = 1
grad9:grad.shape = (3, 3, 128, 256),grad.ndim = 4
grad10:grad.shape = (256,),grad.ndim = 1
grad11:grad.shape = (3, 3, 256, 256),grad.ndim = 4
grad12:grad.shape = (256,),grad.ndim = 1
grad13:grad.shape = (3, 3, 256, 512),grad.ndim = 4
grad14:grad.shape = (512,),grad.ndim = 1
grad15:grad.shape = (3, 3, 512, 512),grad.ndim = 4
grad16:grad.shape = (512,),grad.ndim = 1
grad17:grad.shape = (3, 3, 512, 512),grad.ndim = 4
grad18:grad.shape = (512,),grad.ndim = 1
grad19:grad.shape = (3, 3, 512, 512),grad.ndim = 4
grad20:grad.shape = (512,),grad.ndim = 1
grad21:grad.shape = (512, 300),grad.ndim = 2
grad22:grad.shape = (300,),grad.ndim = 1
grad23:grad.shape = (300, 200),grad.ndim = 2
grad24:grad.shape = (200,),grad.ndim = 1
grad25:grad.shape = (200, 100),grad.ndim = 2
grad26:grad.shape = (100,),grad.ndim = 1
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第2个batch step的初始时的:MSE_Loss = 4.605042934417725
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
...
...
...
epoch_no = 1, batch_step_no = 25,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (2000, 100)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
MSE_Loss.shape = (2000,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第25个batch step的初始时的:MSE_Loss = 4.540274143218994
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, network.trainable_variables)):结束
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 51.0
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 39.0
epoch_no = 1, batch_step_no = 3,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 41.0
epoch_no = 1, batch_step_no = 4,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 43.0
epoch_no = 1, batch_step_no = 5,X_batch.shpae = (2000, 32, 32, 3),Y_batch.shpae = (2000,)
out_logits_conv.shape = (2000, 1, 1, 512)
Reshape之后:out_logits_conv.shape = (2000, 512)
out_logits_fullcon.shape = (2000, 100)
is_correct_count = 47.0
total_correct = 221---total_num = 10000
第1轮Epoch迭代的准确度: acc = 0.0221
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
Process finished with exit code 0
四、GoogLeNet(2014年)
- 2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。
- VGG继承了LeNet以及AlexNet的一些框架结构(详见 大话CNN经典模型:VGGNet),而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;
- 从模型结果来看,GoogLeNet的性能却更加优越。
- GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet”
- 一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题:
- 参数太多,如果训练数据集有限,很容易产生过拟合;
- 网络越大、参数越多,计算复杂度越大,难以应用;
- 网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
- 所以,有人调侃“深度学习”其实是“深度调参”。
- 解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
- 那么,有没有一种方法既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,就如人类的大脑是可以看做是神经元的重复堆积,因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
- Inception历经了V1、V2、V3、V4等多个版本的发展,不断趋于完善。
1、Inception V1
- 通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。谷歌提出了最原始Inception的基本结构:

- 该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
- 网络卷积层中的网络能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的的输入。
- 还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,在每一个卷积层后都要做一个ReLU操作,以增加网络的非线性特征。
- 然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5x5的卷积核所需的计算量就太大了,造成了特征图的厚度很大,为了避免这种情况,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络结构,如下图所示:

- 从GoogLeNet的实验结果来看,效果很明显,差错率比MSRA、VGG等模型都要低,对比结果如下表所示:

1.1 “1x1”的卷积核的作用
- 1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。
- 比如,上一层的输出为100x100x128,经过具有256个通道的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为128x5x5x256= 819200。而假如上一层输出先经过具有32个通道的1x1卷积层,再经过具有256个输出的5x5卷积层,那么输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256= 204800,大约减少了4倍。
1.2 基于Inception V1构建的GoogLeNet网络结构如下(共22层)
- 对上图说明如下:
- GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
- 网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
- 虽然移除了全连接,但是网络中依然使用了Dropout ;
- 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
1.3 基于Inception V1构建的GoogLeNet网络结构图

- 注:上表中的“#3x3 reduce”,“#5x5 reduce”表示在3x3,5x5卷积操作之前使用了1x1卷积的数量。
- GoogLeNet网络结构明细表解析如下:
1.3.1 输入
- 原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
1.3.1 第一层(卷积层)
- 使用7x7的卷积核(滑动步长2,padding为3),64通道,输出为112x112x64,卷积后进行ReLU操作
- 经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,即56x56x64,再进行ReLU操作
1.3.2 第二层(卷积层)
- 使用3x3的卷积核(滑动步长为1,padding为1),192通道,输出为56x56x192,卷积后进行ReLU操作
- 经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x192,再进行ReLU操作
1.3.3.a 第三层(Inception 3a层)
- 分为四个分支,采用不同尺度的卷积核来进行处理
- 64个1x1的卷积核,然后RuLU,输出28x28x64
- 96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
- 16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
- pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
1.3.3.b 第三层(Inception 3b层)
- 分为四个分支,采用不同尺度的卷积核来进行处理
- 128个1x1的卷积核,然后RuLU,输出28x28x128
- 128个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x128,进行ReLU,再进行192个3x3的卷积(padding为1),输出28x28x192
- 32个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x32,进行ReLU计算后,再进行96个5x5的卷积(padding为2),输出28x28x96
- pool层,使用3x3的核(padding为1),输出28x28x256,然后进行64个1x1的卷积,输出28x28x64。
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为28x28x480
1.3.4 第四层(4a,4b,4c,4d,4e)、第五层(5a,5b)……,与3a、3b类似,在此就不再重复。
2、Inception V2
- GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此GoogLeNet团队又对其进行了进一步地发掘改进,产生了升级版本的GoogLeNet。
- GoogLeNet设计的初衷就是要又准又快,而如果只是单纯的堆叠网络虽然可以提高准确率,但是会导致计算效率有明显的下降,所以如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。
- Inception V2版本的解决方案就是修改Inception的内部计算逻辑,提出了比较特殊的“卷积”计算结构。
2.1 卷积分解(Factorizing Convolutions)
- 大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5x5卷积核的参数有25个,3x3卷积核的参数有9个,前者是后者的25/9=2.78倍。因此,GoogLeNet团队提出可以用2个连续的3x3卷积层组成的小网络来代替单个的5x5卷积层,即在保持感受野范围的同时又减少了参数量,如下图:

- 那么这种替代方案会造成表达能力的下降吗?通过大量实验表明,并不会造成表达缺失。
- 可以看出,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能再分解得更小一点呢?GoogLeNet团队考虑了nx1的卷积核,如下图所示,用3个3x1取代3x3卷积:

- 因此,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。GoogLeNet团队发现在网络的前期使用这种分解效果并不好,在中度大小的特征图(feature map)上使用效果才会更好(特征图大小建议在12到20之间)。

2.2 降低特征图大小
- 一般情况下,如果想让图像缩小,可以有如下两种方式:

- 先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大。为了同时保持特征表示且降低计算量,将网络结构改为下图,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)

2.3 基于Inception V2构建的GoogLeNet网络结构图

- 注:上表中的Figure 5指没有进化的Inception,Figure 6是指小卷积版的Inception(用3x3卷积核代替5x5卷积核),Figure 7是指不对称版的Inception(用1xn、nx1卷积核代替nxn卷积核)。
- 经实验,模型结果与旧的GoogleNet相比有较大提升,如下表所示:

3、Inception V3
- Inception V3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。
- 另外,网络输入从224x224变为了299x299。
4、Inception V4
- Inception V4研究了Inception模块与残差连接的结合。
- ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。
- Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。
- ResNet的残差结构如下:

- 将该结构与Inception相结合,变成下图:
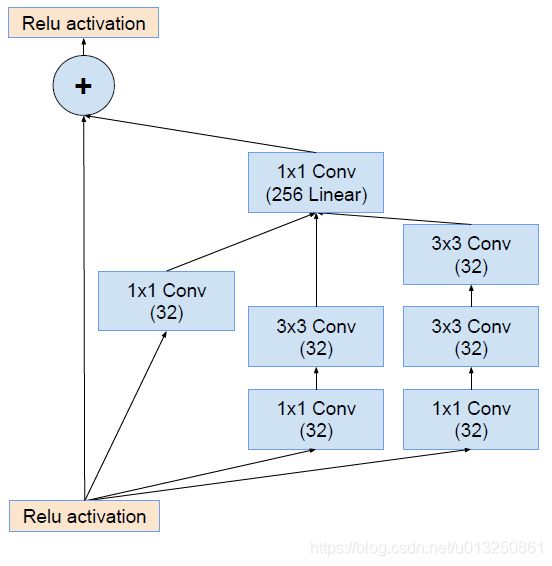
- 通过20个类似的模块组合,Inception-ResNet构建如下:

五、ResNet(2015年)
- 一说起“深度学习”,自然就联想到它非常显著的特点“深、深、深”,通过很深层次的网络实现准确率非常高的图像识别、语音识别等能力。
- 因此,我们自然很容易就想到:深的网络一般会比浅的网络效果好,如果要进一步地提升模型的准确率,最直接的方法就是把网络设计得越深越好,这样模型的准确率也就会越来越准确。
- 那现实是这样吗?
- 先看几个经典的图像识别深度学习模型:

- 这几个模型都是在世界顶级比赛中获奖的著名模型,然而,一看这些模型的网络层次数量,似乎让人很失望,少则5层,多的也就22层而已,这些世界级模型的网络层级也没有那么深啊,这种也算深度学习吗?为什么不把网络层次加到成百上千层呢?
- 带着这个问题,我们先来看一个实验,对常规的网络(plain network,也称平原网络)直接堆叠很多层次,经对图像识别结果进行检验,训练集、测试集的误差结果如下图:
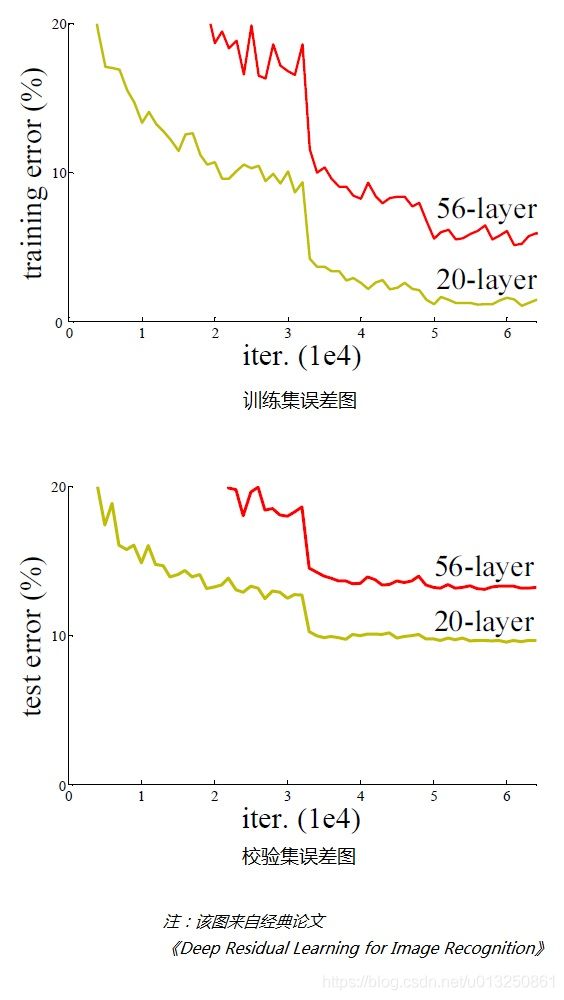
- 从上面两个图可以看出,在网络很深的时候(56层相比20层),模型效果却越来越差了(误差率越高),并不是网络越深越好。
- 通过实验可以发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。
1、为什么随着网络层级越深,模型效果却变差了
- 下图是一个简单神经网络图,由输入层、隐含层、输出层构成:
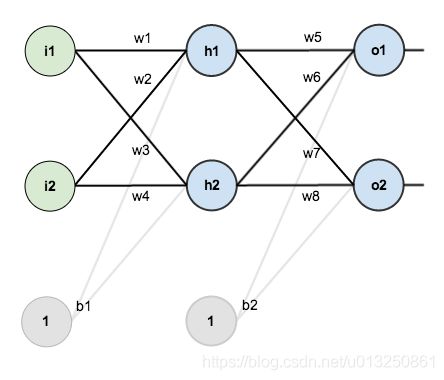
- 回想一下神经网络反向传播的原理,先通过正向传播计算出结果output,然后与样本比较得出误差值 E t o t a l E_{total} Etotal

- 根据误差结果,利用著名的“链式法则”求偏导,使结果误差反向传播从而得出权重 w w w 调整的梯度。下图是输出结果到隐含层的反向传播过程(隐含层到输入层的反向传播过程也是类似):

- 通过不断迭代,对参数矩阵进行不断调整后,使得输出结果的误差值更小,使输出结果与事实更加接近。
- 从上面的过程可以看出,神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
- 那么,如何又能加深网络层数、又能解决梯度消失问题、又能提升模型精度呢?残差网络由此产生。
2、深度残差网络(Deep Residual Network,简称DRN)
-
前面描述了一个实验结果现象,在不断加神经网络的深度时,模型准确率会先上升然后达到饱和,再持续增加深度时则会导致准确率下降,示意图如下:

-
那么我们作这样一个假设:假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(identity mapping,也即 y = x y=x y=x,输出=输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
-
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,该图表示一个 Basic Block:

-
残差网络借鉴了高速网络(Highway Network)的跨层链接思想,但对其进行改进(残差项原本是带权值的,但ResNet用恒等映射代替之)。
-
假定某段神经网络的输入是 x x x,期望输出是 H ( x ) H(x) H(x),即 H ( x ) H(x) H(x) 是期望的复杂潜在映射,如果是要学习这样的模型,则训练难度会比较大;
-
回想前面的假设,如果已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入 x x x 近似于输出 H ( x ) H(x) H(x),以保持在后面的层次中不会造成精度下降。
-
在上图的残差网络结构图中,通过“shortcut connections(捷径连接)”的方式,直接把输入 x x x 传到 输出 作为 “初始结果”,输出结果为 H ( x ) = x + F ( x ) H(x)=x+F(x) H(x)=x+F(x)
其中的 “+” 号表示输出 H ( x ) H(x) H(x) 是 矩阵 x x x 与 F ( x ) F(x) F(x) 的加和。所以 x x x 与 F ( x ) F(x) F(x) 维度要一致。
当 F ( x ) = 0 F(x)=0 F(x)=0 时,那么 H ( x ) = x H(x)=x H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值 H ( X ) H(X) H(X) 和 x x x 的差值,也就是所谓的残差 F ( x ) = H ( x ) − x F(x) = H(x)-x F(x)=H(x)−x
因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。 -
这种残差跳跃式的结构,打破了传统的神经网络 n − 1 n-1 n−1 层的输出只能给 n n n 层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
-
至此,神经网络的层数可以超越之前的约束,达到几十层、上百层甚至千层,为高级语义特征提取和分类提供了可行性。
-
下图最右侧是一个34层的深度残差网络的结构图,
- 每一条箭头曲线包裹的部分是一个 Basic Block
- 每一组不同颜色的部分代表一个 Residual Block,是由多个Basic Block组成(一般2~3个),
- 每个Residual Network 是由多个Residual Block组成:

-
从图可以看出,怎么有一些“shortcut connections(捷径连接)”是实线,有一些是虚线,有什么区别呢?

-
因为经过“shortcut connections(捷径连接)”后, H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,如果 F ( x ) F(x) F(x) 和 x x x 的通道相同,则可直接相加,那么通道不同怎么相加呢。上图中的实线、虚线就是为了区分这两种情况的:
- 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是 3 × 3 × 64 3×3×64 3×3×64 的特征图,由于通道相同,所以采用计算方式为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x
- 虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是 3 × 3 × 64 3×3×64 3×3×64 和 3 × 3 × 128 3×3×128 3×3×128 的特征图,通道不同,采用的计算方式为 H ( x ) = F ( x ) + W x H(x)=F(x)+Wx H(x)=F(x)+Wx,其中 W W W 是卷积操作,用来调整 x x x 维度的。
-
除了上面提到的 两层的 残差学习单元 Basic Block,还有 三层的 残差学习单元 Basic Block,如下图所示:

-
两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。
- 左图是两个 3 × 3 × 256 3×3×256 3×3×256 的卷积,参数数目: 3 × 3 × 256 × 256 × 2 = 1179648 3×3×256×256×2 = 1179648 3×3×256×256×2=1179648,
- 右图是第一个 1 × 1 1×1 1×1的卷积把 256 256 256 维通道降到 64 64 64 维,然后在最后通过 1 × 1 1×1 1×1卷积恢复,整体上用的参数数目: 1 × 1 × 256 × 64 + 3 × 3 × 64 × 64 + 1 × 1 × 64 × 256 = 69632 1×1×256×64 + 3×3×64×64 + 1×1×64×256 = 69632 1×1×256×64+3×3×64×64+1×1×64×256=69632,右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。
- 对于常规的ResNet,比如34层或者更少的网络,使用左图结构;对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
-
经检验,深度残差网络的确解决了退化问题,如下图所示,左图为平原网络(plain network)网络层次越深(34层)比网络层次浅的(18层)的误差率更高;右图为残差网络ResNet的网络层次越深(34层)比网络层次浅的(18层)的误差率更低。

-
ResNet在ILSVRC2015竞赛中惊艳亮相,一下子将网络深度提升到152层,将错误率降到了3.57,在图像识别错误率和网络深度方面,比往届比赛有了非常大的提升,ResNet毫无悬念地夺得了ILSVRC2015的第一名。如下图所示:

-
在ResNet的作者的第二篇相关论文《Identity Mappings in Deep Residual Networks》中,提出了ResNet V2。ResNet V2 和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此“shortcut connection”(捷径连接)的非线性激活函数(如ReLU)替换为 Identity Mappings。同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理后,新的残差学习单元比以前更容易训练且泛化性更强。
3、ResNet案例-cifar100分类数据集
3.1 自定义ResNet神经网络-Tensorflow
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 放在 import tensorflow as tf 之前才有效
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
#==========================================自定义ResNet神经网络:开始==========================================
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# stride>1时(比如stride=2),则通过改层Layer后的FeatureMap的大小减半。strides: An integer or tuple/list of 2 integers
class BasicBlock(layers.Layer):
def __init__(self, filter_count, stride=1):
super(BasicBlock, self).__init__()
# ================================F(x) 部分================================
# Layer01
self.conv1 = layers.Conv2D(filters=filter_count, kernel_size=[3, 3], strides=stride, padding='same') # 如果padding='same'&stride!=1:输出维度是输入维度的stride分之一。
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# Layer02
self.conv2 = layers.Conv2D(filters=filter_count, kernel_size=[3, 3], strides=1, padding='same') # padding='same'&stride==1:输出维度与输入维度一致。
self.bn2 = layers.BatchNormalization()
# ================================identity(x)部分================================
if stride != 1: # 如果 stride != 1,F(x)部分的输入维度减小stride倍。所以利用一层大小为[1×1×filter_count]的卷积层identity_layer设置strides与F(x)部分的stride一致,将输入值x的维度调整为和F(x)的维度一致,即进行SubSampling。然后再进行加和计算 H(x)=x+F(X)
self.identity_layer = layers.Conv2D(filters=filter_count, kernel_size=[1, 1], strides=stride)
else: # 如果 stride = 1,则F(x)输出值与输入值x的维度保持不变(必须保证F(x)部分的padding='same'才能维度不变)。所以identity_layer部分直接可以和F(x)部分进行加和计算,不需要经过卷积层对x进行维度调整。也可减少参数的使用。
self.identity_layer = lambda x: x # lambda匿名函数:输入为x,return x
def call(self, inputs, training=None):
# 前向传播 # [b, h, w, c]
# ================================F(x) 部分================================
# Layer01
F_out = self.conv1(inputs)
F_out = self.bn1(F_out)
F_out = self.relu(F_out)
# Layer02
F_out = self.conv2(F_out)
F_out = self.bn2(F_out)
# ================================identity部分================================
# x=identity(x)
identity_out = self.identity_layer(inputs)
# ================================H(x)=F(x)+x================================
basic_block_output = layers.add([F_out, identity_out]) # layers.add(): A tensor as the sum of the inputs. It has the same shape as the inputs.
basic_block_output = tf.nn.relu(basic_block_output)
return basic_block_output
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count, residualBlock_size, stride=1):
self.filter_count = filter_count
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_not_1 = BasicBlock(self.filter_count, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
basic_block_stride_1 = BasicBlock(self.filter_count, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
residualBlock = Sequential()
residualBlock.add(basic_block_stride_not_1) # 有一个BasicBlock必须是 stride != 1 时的BasicBlock
for _ in range(1, self.residualBlock_size): # 其余的BasicBlock都是 stride == 1 时的BasicBlock
residualBlock.add(basic_block_stride_1)
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
# residualBlock_size_list:[2, 2, 2, 2] 表示该ResidualNet含有4个ResidualBlock,每个ResidualBlock包含2个BasicBlock
# residualBlock_size_list:[3, 4, 6, 3] 表示该ResidualNet含有4个ResidualBlock,第1个ResidualBlock包含3个BasicBlock,第2个ResidualBlock包含4个BasicBlock,第3个ResidualBlock包含6个BasicBlock,第4个ResidualBlock包含3个BasicBlock
class ResidualNet(keras.Model):
def __init__(self, residualBlock_size_list, class_count=100): # class_count:表示全连接层的输出维度,取决于数据集分类的类别总数量(cifar100为100类)
super(ResidualNet, self).__init__()
# ================================预处理Block================================
self.preprocessBlock = Sequential([layers.Conv2D(filters=50, kernel_size=[3, 3], strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# ================================所有ResidualBlock================================
residualBlock01_size = residualBlock_size_list[0]
residualBlock02_size = residualBlock_size_list[1]
residualBlock03_size = residualBlock_size_list[2]
residualBlock04_size = residualBlock_size_list[3]
self.residualBlock1 = ResidualBlock(50, residualBlock01_size, stride=1)() # 第01个ResidualBlock,包含residualBlock01_size个BasicBlock,residualBlock1设置为64通道
self.residualBlock2 = ResidualBlock(150, residualBlock02_size, stride=2)() # 第02个ResidualBlock,包含residualBlock02_size个BasicBlock,residualBlock2设置为128通道
self.residualBlock3 = ResidualBlock(300, residualBlock03_size, stride=2)() # 第03个ResidualBlock,包含residualBlock03_size个BasicBlock,residualBlock3设置为256通道
self.residualBlock4 = ResidualBlock(500, residualBlock04_size, stride=2)() # 第04个ResidualBlock,包含residualBlock04_size个BasicBlock,residualBlock4设置为512通道
# ================================输出层================================
# output: [b, h, w, 500] 以上步骤输出的FeatureMap的大小[h,w]不太方便计算
self.avgpool_Layer = layers.GlobalAveragePooling2D() # 不管输入的每一个FeatureMap的大小[h,w]是多少,取每一个FeatureMap上的所有元素的平均值作为输出。所以该步骤输出的数据维度为[1,500]
# 将上一层的维度为[1,500]的输出传给全连接层进行分类,输出维度为[1,class_count]
self.fullcon_Layer = layers.Dense(class_count)
def call(self, inputs, training=None):
# ================================预处理Block================================
x = self.preprocessBlock(inputs) # 输出维度:[b, h, w, 50]
# ================================所有ResidualBlock================================
x = self.residualBlock1(x) # 输出维度:[b, h, w, 50]
x = self.residualBlock2(x) # 输出维度:[b, h, w, 150]
x = self.residualBlock3(x) # 输出维度:[b, h, w, 300]
x = self.residualBlock4(x) # 输出维度:[b, h, w, 500]
# ================================输出层================================
x = self.avgpool_Layer(x) # 输出维度:[b, 500]
x = self.fullcon_Layer(x) # 输出维度:[b, 100]
return x
def resnet18():
return ResidualNet([2, 2, 2, 2])
def resnet34():
return ResidualNet([3, 4, 6, 3])
#==========================================自定义ResNet神经网络:结束==========================================
# 一、获取数据集
(X_train, Y_train), (X_val, Y_val) = datasets.cifar100.load_data()
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
Y_train = tf.squeeze(Y_train)
Y_val = tf.squeeze(Y_val)
print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
# 二、数据处理
# 预处理函数:将numpy数据转为tensor
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x, y
# 2.1 处理训练集
# print('X_train.shpae = {0},Y_train.shpae = {1}------------type(X_train) = {2},type(Y_train) = {3}'.format(X_train.shape, Y_train.shape, type(X_train), type(Y_train)))
db_train = tf.data.Dataset.from_tensor_slices((X_train, Y_train)) # 此步骤自动将numpy类型的数据转为tensor
db_train = db_train.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
# 从data数据集中按顺序抽取buffer_size个样本放在buffer中,然后打乱buffer中的样本。buffer中样本个数不足buffer_size,继续从data数据集中安顺序填充至buffer_size,此时会再次打乱。
db_train = db_train.shuffle(buffer_size=1000) # 打散db_train中的样本顺序,防止图片的原始顺序对神经网络性能的干扰。
print('db_train = {0},type(db_train) = {1}'.format(db_train, type(db_train)))
batch_size_train = 500 # 每个batch里的样本数量设置100-200之间合适。
db_batch_train = db_train.batch(batch_size_train) # 将db_batch_train中每sample_num_of_each_batch_train张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_train张图片
print('db_batch_train = {0},type(db_batch_train) = {1}'.format(db_batch_train, type(db_batch_train)))
# 2.2 处理测试集:测试数据集不需要打乱顺序
db_val = tf.data.Dataset.from_tensor_slices((X_val, Y_val)) # 此步骤自动将numpy类型的数据转为tensor
db_val = db_val.map(preprocess) # 调用map()函数批量修改每一个元素数据的数据类型
batch_size_val = 500 # 每个batch里的样本数量设置100-200之间合适。
db_batch_val = db_val.batch(batch_size_val) # 将db_val中每sample_num_of_each_batch_val张图片分为一个batch,读取一个batch相当于一次性并行读取sample_num_of_each_batch_val张图片
# 三、构建ResNet神经网络
# 1、构建ResNet神经网络
resnet18_network = resnet18()
resnet18_network.build(input_shape=[None, 32, 32, 3]) # 原始图片维度为:[32, 32, 3],None表示样本数量,是不确定的值。
# 2、打印神经网络信息
resnet18_network.summary() # 打印卷积神经网络network的简要信息
# 四、梯度下降优化器设置
optimizer = optimizers.Adam(lr=1e-3)
# 五、整体数据集进行一次梯度下降来更新模型参数,整体数据集迭代一次,一般用epoch。每个epoch中含有batch_step_no个step,每个step中就是设置的每个batch所含有的样本数量。
def train_epoch(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_train): # 每次计算一个batch的数据,循环结束则计算完毕整体数据的一次梯度下降;每个batch的序号一般用step表示(batch_step_no)
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}------------type(X_batch) = {4},type(Y_batch) = {5}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape, type(X_batch), type(Y_batch)))
Y_batch_one_hot = tf.one_hot(Y_batch, depth=100) # One-Hot编码,共有100类 [] => [b,100]
print('\tY_train_one_hot.shpae = {0}'.format(Y_batch_one_hot.shape))
# 梯度带tf.GradientTape:连接需要计算梯度的”函数“和”变量“的上下文管理器(context manager)。将“函数”(即Loss的定义式)与“变量”(即神经网络的所有参数)都包裹在tf.GradientTape中进行追踪管理
with tf.GradientTape() as tape:
# Step1. 前向传播/前向运算-->计算当前参数下模型的预测值
out_logits = resnet18_network(X_batch) # [b, 32, 32, 3] => [b, 100]
print('\tout_logits.shape = {0}'.format(out_logits.shape))
# Step2. 计算预测值与真实值之间的损失Loss:交叉熵损失
MSE_Loss = tf.losses.categorical_crossentropy(Y_batch_one_hot, out_logits, from_logits=True) # categorical_crossentropy()第一个参数是真实值,第二个参数是预测值,顺序不能颠倒
print('\tMSE_Loss.shape = {0}'.format(MSE_Loss.shape))
MSE_Loss = tf.reduce_mean(MSE_Loss)
print('\t求均值后:MSE_Loss.shape = {0}'.format(MSE_Loss.shape))
print('\t第{0}个epoch-->第{1}个batch step的初始时的:MSE_Loss = {2}'.format(epoch_no, batch_step_no + 1, MSE_Loss))
# Step3. 反向传播-->损失值Loss下降一个学习率的梯度之后所对应的更新后的各个Layer的参数:W1, W2, W3, B1, B2, B3...
# grads为整个全连接神经网络模型中所有Layer的待优化参数trainable_variables [W1, W2, W3, B1, B2, B3...]分别对目标函数MSE_Loss 在 X_batch 处的梯度值,
grads = tape.gradient(MSE_Loss, resnet18_network.trainable_variables) # grads为梯度值。MSE_Loss为目标函数,variables为卷积神经网络、全连接神经网络所有待优化参数,
# grads, _ = tf.clip_by_global_norm(grads, 15) # 限幅:解决gradient explosion或者gradients vanishing的问题。
# print('\t第{0}个epoch-->第{1}个batch step的初始时的参数:'.format(epoch_no, batch_step_no + 1))
if batch_step_no == 0:
index_variable = 1
for grad in grads:
print('\t\tgrad{0}:grad.shape = {1},grad.ndim = {2}'.format(index_variable, grad.shape, grad.ndim))
index_variable = index_variable + 1
# 进行一次梯度下降
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始')
optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)) # network的所有参数 trainable_variables [W1, W2, W3, B1, B2, B3...]下降一个梯度 w' = w - lr * grad,zip的作用是让梯度值与所属参数前后一一对应
print('\t梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束\n')
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 六、模型评估 test/evluation
def evluation(epoch_no):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
total_correct, total_num = 0, 0
for batch_step_no, (X_batch, Y_batch) in enumerate(db_batch_val):
print('epoch_no = {0}, batch_step_no = {1},X_batch.shpae = {2},Y_batch.shpae = {3}'.format(epoch_no, batch_step_no + 1, X_batch.shape, Y_batch.shape))
# 根据训练模型计算测试数据的输出值out
out_logits = resnet18_network(X_batch) # [b, 32, 32, 3] => [b, 100]
print('\tout_logits.shape = {0}'.format(out_logits.shape))
# print('\tout_logits_fullcon[:1,:] = {0}'.format(out_logits_fullcon[:1, :]))
# 利用softmax()函数将network的输出值转为0~1范围的值,并且使得所有类别预测概率总和为1
out_logits_prob = tf.nn.softmax(out_logits, axis=1) # out_logits_prob: [b, 100] ~ [0, 1]
# print('\tout_logits_prob[:1,:] = {0}'.format(out_logits_prob[:1, :]))
out_logits_prob_max_index = tf.cast(tf.argmax(out_logits_prob, axis=1), dtype=tf.int32) # [b, 100] => [b] 查找最大值所在的索引位置 int64 转为 int32
# print('\t预测值:out_logits_prob_max_index = {0},\t真实值:Y_train_one_hot = {1}'.format(out_logits_prob_max_index, Y_batch))
is_correct_boolean = tf.equal(out_logits_prob_max_index, Y_batch.numpy())
# print('\tis_correct_boolean = {0}'.format(is_correct_boolean))
is_correct_int = tf.cast(is_correct_boolean, dtype=tf.float32)
# print('\tis_correct_int = {0}'.format(is_correct_int))
is_correct_count = tf.reduce_sum(is_correct_int)
print('\tis_correct_count = {0}\n'.format(is_correct_count))
total_correct += int(is_correct_count)
total_num += X_batch.shape[0]
print('total_correct = {0}---total_num = {1}'.format(total_correct, total_num))
acc = total_correct / total_num
print('第{0}轮Epoch迭代的准确度: acc = {1}'.format(epoch_no, acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
# 七、整体数据迭代多次梯度下降来更新模型参数
def train():
epoch_count = 1 # epoch_count为整体数据集迭代梯度下降次数
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no)
evluation(epoch_no)
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
if __name__ == '__main__':
train()
打印结果:
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000, 1)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'numpy.ndarray'>
X_train.shpae = (50000, 32, 32, 3),Y_train.shpae = (50000,)------------type(X_train) = <class 'numpy.ndarray'>,type(Y_train) = <class 'tensorflow.python.framework.ops.EagerTensor'>
db_train = <ShuffleDataset shapes: ((32, 32, 3), ()), types: (tf.float32, tf.int32)>,type(db_train) = <class 'tensorflow.python.data.ops.dataset_ops.ShuffleDataset'>
db_batch_train = <BatchDataset shapes: ((None, 32, 32, 3), (None,)), types: (tf.float32, tf.int32)>,type(db_batch_train) = <class 'tensorflow.python.data.ops.dataset_ops.BatchDataset'>
Model: "residual_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 30, 30, 50) 1600
_________________________________________________________________
sequential_1 (Sequential) (None, 30, 30, 50) 91000
_________________________________________________________________
sequential_2 (Sequential) (None, 15, 15, 150) 685650
_________________________________________________________________
sequential_3 (Sequential) (None, 8, 8, 300) 2886300
_________________________________________________________________
sequential_4 (Sequential) (None, 4, 4, 500) 8260500
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 50100
=================================================================
Total params: 11,975,150
Trainable params: 11,967,050
Non-trainable params: 8,100
_________________________________________________________________
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (500, 100)
out_logits.shape = (500, 100)
MSE_Loss.shape = (500,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第1个batch step的初始时的:MSE_Loss = 4.608854293823242
grad1:grad.shape = (3, 3, 3, 50),grad.ndim = 4
grad2:grad.shape = (50,),grad.ndim = 1
grad3:grad.shape = (50,),grad.ndim = 1
grad4:grad.shape = (50,),grad.ndim = 1
grad5:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad6:grad.shape = (50,),grad.ndim = 1
grad7:grad.shape = (50,),grad.ndim = 1
grad8:grad.shape = (50,),grad.ndim = 1
grad9:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad10:grad.shape = (50,),grad.ndim = 1
grad11:grad.shape = (50,),grad.ndim = 1
grad12:grad.shape = (50,),grad.ndim = 1
grad13:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad14:grad.shape = (50,),grad.ndim = 1
grad15:grad.shape = (50,),grad.ndim = 1
grad16:grad.shape = (50,),grad.ndim = 1
grad17:grad.shape = (3, 3, 50, 50),grad.ndim = 4
grad18:grad.shape = (50,),grad.ndim = 1
grad19:grad.shape = (50,),grad.ndim = 1
grad20:grad.shape = (50,),grad.ndim = 1
grad21:grad.shape = (3, 3, 50, 150),grad.ndim = 4
grad22:grad.shape = (150,),grad.ndim = 1
grad23:grad.shape = (150,),grad.ndim = 1
grad24:grad.shape = (150,),grad.ndim = 1
grad25:grad.shape = (3, 3, 150, 150),grad.ndim = 4
grad26:grad.shape = (150,),grad.ndim = 1
grad27:grad.shape = (150,),grad.ndim = 1
grad28:grad.shape = (150,),grad.ndim = 1
grad29:grad.shape = (1, 1, 50, 150),grad.ndim = 4
grad30:grad.shape = (150,),grad.ndim = 1
grad31:grad.shape = (3, 3, 150, 150),grad.ndim = 4
grad32:grad.shape = (150,),grad.ndim = 1
grad33:grad.shape = (150,),grad.ndim = 1
grad34:grad.shape = (150,),grad.ndim = 1
grad35:grad.shape = (3, 3, 150, 150),grad.ndim = 4
grad36:grad.shape = (150,),grad.ndim = 1
grad37:grad.shape = (150,),grad.ndim = 1
grad38:grad.shape = (150,),grad.ndim = 1
grad39:grad.shape = (3, 3, 150, 300),grad.ndim = 4
grad40:grad.shape = (300,),grad.ndim = 1
grad41:grad.shape = (300,),grad.ndim = 1
grad42:grad.shape = (300,),grad.ndim = 1
grad43:grad.shape = (3, 3, 300, 300),grad.ndim = 4
grad44:grad.shape = (300,),grad.ndim = 1
grad45:grad.shape = (300,),grad.ndim = 1
grad46:grad.shape = (300,),grad.ndim = 1
grad47:grad.shape = (1, 1, 150, 300),grad.ndim = 4
grad48:grad.shape = (300,),grad.ndim = 1
grad49:grad.shape = (3, 3, 300, 300),grad.ndim = 4
grad50:grad.shape = (300,),grad.ndim = 1
grad51:grad.shape = (300,),grad.ndim = 1
grad52:grad.shape = (300,),grad.ndim = 1
grad53:grad.shape = (3, 3, 300, 300),grad.ndim = 4
grad54:grad.shape = (300,),grad.ndim = 1
grad55:grad.shape = (300,),grad.ndim = 1
grad56:grad.shape = (300,),grad.ndim = 1
grad57:grad.shape = (3, 3, 300, 500),grad.ndim = 4
grad58:grad.shape = (500,),grad.ndim = 1
grad59:grad.shape = (500,),grad.ndim = 1
grad60:grad.shape = (500,),grad.ndim = 1
grad61:grad.shape = (3, 3, 500, 500),grad.ndim = 4
grad62:grad.shape = (500,),grad.ndim = 1
grad63:grad.shape = (500,),grad.ndim = 1
grad64:grad.shape = (500,),grad.ndim = 1
grad65:grad.shape = (1, 1, 300, 500),grad.ndim = 4
grad66:grad.shape = (500,),grad.ndim = 1
grad67:grad.shape = (3, 3, 500, 500),grad.ndim = 4
grad68:grad.shape = (500,),grad.ndim = 1
grad69:grad.shape = (500,),grad.ndim = 1
grad70:grad.shape = (500,),grad.ndim = 1
grad71:grad.shape = (3, 3, 500, 500),grad.ndim = 4
grad72:grad.shape = (500,),grad.ndim = 1
grad73:grad.shape = (500,),grad.ndim = 1
grad74:grad.shape = (500,),grad.ndim = 1
grad75:grad.shape = (500, 100),grad.ndim = 2
grad76:grad.shape = (100,),grad.ndim = 1
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (500, 100)
out_logits.shape = (500, 100)
MSE_Loss.shape = (500,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第2个batch step的初始时的:MSE_Loss = 5.222436428070068
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束
...
...
...
...
...
epoch_no = 1, batch_step_no = 100,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)------------type(X_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>,type(Y_batch) = <class 'tensorflow.python.framework.ops.EagerTensor'>
Y_train_one_hot.shpae = (500, 100)
out_logits.shape = (500, 100)
MSE_Loss.shape = (500,)
求均值后:MSE_Loss.shape = ()
第1个epoch-->第100个batch step的初始时的:MSE_Loss = 4.207188129425049
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):开始
梯度下降步骤-->optimizer.apply_gradients(zip(grads, resnet18_network.trainable_variables)):结束
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_step_no = 1,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)
out_logits.shape = (500, 100)
is_correct_count = 18.0
epoch_no = 1, batch_step_no = 2,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)
out_logits.shape = (500, 100)
is_correct_count = 27.0
...
...
...
epoch_no = 1, batch_step_no = 20,X_batch.shpae = (500, 32, 32, 3),Y_batch.shpae = (500,)
out_logits.shape = (500, 100)
is_correct_count = 26.0
total_correct = 454---total_num = 10000
第1轮Epoch迭代的准确度: acc = 0.0454
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
Process finished with exit code 0
3.2 自定义ResNet神经网络-Pytorch
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from torch.nn import functional as F
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# filter_count_in≠filter_count_out时,则通过该层Layer后的FeatureMap的大小改变,identity层也需要reshape
class BasicBlock(nn.Module):
def __init__(self, filter_count_in, filter_count_out, stride=1):
super(BasicBlock, self).__init__()
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(in_channels=filter_count_in, out_channels=filter_count_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(filter_count_out)
self.conv2 = nn.Conv2d(filter_count_out, filter_count_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(filter_count_out)
self.identity = nn.Sequential()
if filter_count_in != filter_count_out: # 将输入值x的维度调整为和F(x)的输出维度保持一致 [b, filter_count_in, h, w] => [b, filter_count_out, h, w]
self.identity = nn.Sequential(
nn.Conv2d(filter_count_in, filter_count_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(filter_count_out)
)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
F_out = self.bn2(x)
# short cut
identity_out = self.identity(input) # 调整input的维度与F_out保持一致,然后才能和F_out相加:[b, ch_in, h, w] => [b, ch_out, h, w]
H_out = identity_out + F_out
H_out = F.relu(H_out)
return H_out
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count_in, filter_count_out, residualBlock_size=1, stride=1):
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_eq = BasicBlock(self.filter_count_in, self.filter_count_in, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
basic_block_stride_not_eq = BasicBlock(self.filter_count_in, self.filter_count_out, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
residualBlock = nn.Sequential()
for _ in range(0, self.residualBlock_size - 1): # 其余的BasicBlock都是 filter_count_in == filter_count_out 时的BasicBlock
residualBlock.add_module('basic_block_stride_eq', basic_block_stride_eq)
residualBlock.add_module('basic_block_stride_not_eq', basic_block_stride_not_eq) # 有一个BasicBlock必须是 filter_count_in != filter_count_out 时的BasicBlock
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 ResidualBlock
self.residualBlock1 = ResidualBlock(filter_count_in=64, filter_count_out=128, residualBlock_size=2, stride=2)() # [b, 64, h, w] => [b, 128, h ,w]
self.residualBlock2 = ResidualBlock(filter_count_in=128, filter_count_out=256, residualBlock_size=2, stride=2)() # [b, 128, h, w] => [b, 256, h, w]
self.residualBlock3 = ResidualBlock(filter_count_in=256, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 256, h, w] => [b, 512, h, w]
self.residualBlock4 = ResidualBlock(filter_count_in=512, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 512, h, w] => [b, 1024, h, w]
self.outlayer = nn.Linear(512 * 1 * 1, 10)
def forward(self, X):
X = F.relu(self.conv1(X))
# [b, 64, h, w] => [b, 1024, h, w]
X = self.residualBlock1(X)
X = self.residualBlock2(X)
X = self.residualBlock3(X)
X = self.residualBlock4(X) # [b, 512, 2, 2]
X = F.adaptive_avg_pool2d(X, [1, 1]) # [b, 512, 2, 2] => [b, 512, 1, 1]
X = X.view(X.size(0), -1) # [b, 512, 1, 1] => [b, 512]
X = self.outlayer(X) # [b, 512] => [b, 10]
return X
def main():
batch_size = 200
# 一、获取cifar10训练数据集
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
# 二、设置GPU
device = torch.device('cuda')
# 三、实例化ResNet18神经网络模型
model = ResNet18().to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 六、训练
for epoch in range(3):
# **********************************************************训练**********************************************************
print('**************************训练模式:开始**************************')
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(cifar_train):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_index % 100 == 0:
print('epoch = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch, batch_index, loss.item()))
print('**************************训练模式:结束**************************')
# **********************************************************模型评估**********************************************************
print('**************************验证模式:开始**************************')
model.eval() # 切换至验证模式
with torch.no_grad(): # torch.no_grad()所包裹的部分不需要参与反向传播
# test
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(cifar_test):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
acc = total_correct / total_num
if batch_index % 100 == 0:
print('epoch = {0}, batch_index = {1}, test acc = {2}'.format(epoch, batch_index, acc))
print('**************************验证模式:结束**************************')
if __name__ == '__main__':
main()
打印结果:
Files already downloaded and verified
Files already downloaded and verified
15,826,314 total parameters.
15,826,314 training parameters.
model = ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residualBlock1): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock2): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock3): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock4): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(outlayer): Linear(in_features=512, out_features=10, bias=True)
)
**************************训练模式:开始**************************
epoch = 0, batch_index = 0, loss.item() = 2.784912109375
epoch = 0, batch_index = 100, loss.item() = 1.2591865062713623
epoch = 0, batch_index = 200, loss.item() = 1.2418736219406128
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 0, batch_index = 0, test acc = 0.515
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 1, batch_index = 0, loss.item() = 1.0537413358688354
epoch = 1, batch_index = 100, loss.item() = 1.088006615638733
epoch = 1, batch_index = 200, loss.item() = 1.0332653522491455
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 1, batch_index = 0, test acc = 0.635
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 2, batch_index = 0, loss.item() = 0.9080470204353333
epoch = 2, batch_index = 100, loss.item() = 0.7950635552406311
epoch = 2, batch_index = 200, loss.item() = 0.7487978339195251
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 2, batch_index = 0, test acc = 0.64
**************************验证模式:结束**************************
Process finished with exit code 0
3.3 自定义ResNet18&自定义数据集-Pytorch
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torch.nn import functional as F
import visdom
import csv
import glob
import os
import random
from PIL import Image
from torch.utils.data import Dataset # 自定义数据集的父类
from torchvision import transforms
torch.manual_seed(1234) # 随机种子
device = torch.device('cuda') # 设置GPU
# =============================================================================Pokemon自定义数据集:开始=============================================================================
class Pokemon(Dataset):
# root表示数据位置;resize表示数据输出的size;mode表示训练模式/测试模式
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 给各个类型进行编号
self.name2label = {
} # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)): # 过滤掉不是文件夹的文件
continue
self.name2label[name] = len(self.name2label.keys())
print('self.name2label = {0}'.format(self.name2label)) # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
# 读取已保存的图片+标签数据集
self.img_paths, self.labels = self.load_csv('img_paths.csv') # 数据对(img_path + image_label):img_paths, labels
# 对数据集根据当前模式进行裁剪
if mode == 'train': # 60%
self.img_paths = self.img_paths[:int(0.6 * len(self.img_paths))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 20% = 60%->80%
self.img_paths = self.img_paths[int(0.6 * len(self.img_paths)):int(0.8 * len(self.img_paths))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # 20% = 80%->100%
self.img_paths = self.img_paths[int(0.8 * len(self.img_paths)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
# 1、如果没有csv文件,则创建该csv文件
if not os.path.exists(os.path.join(self.root, filename)):
img_paths = [] # 把所有图片的path都保存在该list中,各个图片的label可以从path推断出来,所有没有单独保存。
for name in self.name2label.keys():
img_paths += glob.glob(os.path.join(self.root, name, '*.png')) # 'pokemon\\mewtwo\\00001.png
img_paths += glob.glob(os.path.join(self.root, name, '*.jpg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.jpeg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.gif'))
print('len(img_paths) = {0}, img_paths = {1}'.format(len(img_paths), img_paths)) # len(img_paths) = 1168, img_paths = ['pokemon\\bulbasaur\\00000000.png','pokemon\\bulbasaur\\00000001.png',...]
random.shuffle(img_paths) # 打乱list中的图片顺序
# 向csv文件保存图片的path+label
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img_path in img_paths: # 'pokemon\\bulbasaur\\00000000.png'
name = img_path.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img_path, label]) # 'pokemon\\bulbasaur\\00000000.png', 0
print('writen into csv file:', filename)
# 2、如果已经有csv文件,则读取该csv文件
img_paths, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img_path, label = row # 'pokemon\\bulbasaur\\00000000.png', 0
label = int(label)
img_paths.append(img_path)
labels.append(label)
assert len(img_paths) == len(labels)
return img_paths, labels
def __len__(self):
return len(self.img_paths)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('denormalize-->mean.shape = {0}, std.shape = {1}'.format(mean.shape, std.shape))
x = x_hat * std + mean
return x
def __getitem__(self, img_idx): # img_idx~[0~len(img_paths)]
img_path, label = self.img_paths[img_idx], self.labels[img_idx] # img_path: 'pokemon\\bulbasaur\\00000000.png';label: 0
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path --> image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15), # rotate如果比较大的话,可能会造成网络不收敛
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 该数值是实践中统计的效果比较好的值
])
img = transform(img_path)
label = torch.tensor(label)
return img, label
# =============================================================================Pokemon自定义数据集:结束=============================================================================
# =============================================================================ResNet18神经网络:开始=============================================================================
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# filter_count_in≠filter_count_out时,则通过该层Layer后的FeatureMap的大小改变,identity层也需要reshape
class BasicBlock(nn.Module):
def __init__(self, filter_count_in, filter_count_out, stride=1):
super(BasicBlock, self).__init__()
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.stride = stride
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(in_channels=filter_count_in, out_channels=filter_count_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(filter_count_out)
self.conv2 = nn.Conv2d(filter_count_out, filter_count_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(filter_count_out)
self.identity = nn.Sequential()
if filter_count_in != filter_count_out: # 将输入值x的维度调整为和F(x)的输出维度保持一致 [b, filter_count_in, h, w] => [b, filter_count_out, h, w]
self.identity = nn.Sequential(
nn.Conv2d(filter_count_in, filter_count_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(filter_count_out)
)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
F_out = self.bn2(x)
# short cut
identity_out = self.identity(input) # 调整input的维度与F_out保持一致,然后才能和F_out相加:[b, ch_in, h, w] => [b, ch_out, h, w]
# print('stride = {0},filter_count_in = {1},filter_count_out = {2},F_out.shape = {3},identity_out.shape = {4}'.format(self.stride, self.filter_count_in, self.filter_count_out, F_out.shape, identity_out.shape))
H_out = identity_out + F_out
H_out = F.relu(H_out)
return H_out
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count_in, filter_count_out, residualBlock_size=1, stride=1):
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_eq = BasicBlock(self.filter_count_in, self.filter_count_in, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
basic_block_stride_not_eq = BasicBlock(self.filter_count_in, self.filter_count_out, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
residualBlock = nn.Sequential()
for _ in range(0, self.residualBlock_size - 1): # 其余的BasicBlock都是 filter_count_in == filter_count_out 时的BasicBlock
residualBlock.add_module('basic_block_stride_eq', basic_block_stride_eq)
residualBlock.add_module('basic_block_stride_not_eq', basic_block_stride_not_eq) # 有一个BasicBlock必须是 filter_count_in != filter_count_out 时的BasicBlock
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
class ResNet18(nn.Module):
def __init__(self, num_class): # num_class 表示最终所有分类数量
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 ResidualBlock
self.residualBlock1 = ResidualBlock(filter_count_in=64, filter_count_out=128, residualBlock_size=2, stride=2)() # [b, 64, h, w] => [b, 128, h ,w]
self.residualBlock2 = ResidualBlock(filter_count_in=128, filter_count_out=256, residualBlock_size=2, stride=2)() # [b, 128, h, w] => [b, 256, h, w]
self.residualBlock3 = ResidualBlock(filter_count_in=256, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 256, h, w] => [b, 512, h, w]
self.residualBlock4 = ResidualBlock(filter_count_in=512, filter_count_out=512, residualBlock_size=2, stride=1)() # [b, 512, h, w] => [b, 1024, h, w]
self.outlayer = nn.Linear(512 * 1 * 1, num_class)
def forward(self, X):
X = F.relu(self.conv1(X))
# [b, 64, h, w] => [b, 1024, h, w]
X = self.residualBlock1(X)
X = self.residualBlock2(X)
X = self.residualBlock3(X)
X = self.residualBlock4(X) # [b, 512, 2, 2]
X = F.adaptive_avg_pool2d(X, [1, 1]) # [b, 512, 2, 2] => [b, 512, 1, 1]
X = X.view(X.size(0), -1) # [b, 512, 1, 1] => [b, 512]
X = self.outlayer(X) # [b, 512] => [b, 5]
return X
# =============================================================================ResNet18神经网络:结束=============================================================================
# =============================================================================训练主体:开始=============================================================================
batch_size = 32
viz = visdom.Visdom() # 在控制台开启Visdom:python -m visdom.server
global_step = 0
# 一、获取Pokemon训练数据集
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle=True, num_workers=0) # num_workers表示开启的线程数量
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=0)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=0)
# 三、实例化ResNet18神经网络模型
model = ResNet18(5).to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train_epoch(epoch_no):
global global_step
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(train_loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch_no, batch_index, loss.item()))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
def evalute(epoch_no, loader):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
val_acc = total_correct / total_num
viz.line([val_acc], [global_step], win='val_acc', update='append')
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, val_acc = {2}'.format(epoch_no, batch_index, val_acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
return val_acc
def main():
epoch_count = 4 # epoch_count为整体数据集迭代梯度下降次数
best_acc, best_epoch = 0, 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no) # 训练
val_acc = evalute(epoch_no, val_loader) # 验证
if val_acc > best_acc:
best_epoch = epoch_no
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('epoch = {0}, best_epoch = {1}, best_acc = {2}'.format(epoch_no, best_epoch, best_acc))
print('**************************验证模式:结束**************************')
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(best_epoch, test_loader) # 测试
print('test acc:', test_acc)
if __name__ == '__main__':
main()
# =============================================================================训练主体:结束=============================================================================

打印结果:
Setting up a new session...
self.name2label = {
'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {
'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {
'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
15,823,749 total parameters.
15,823,749 training parameters.
model = ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residualBlock1): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock2): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock3): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock4): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
)
(outlayer): Linear(in_features=512, out_features=5, bias=True)
)
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, loss.item() = 1.939097285270691
epoch_no = 1, batch_index = 5, loss.item() = 1.332801342010498
epoch_no = 1, batch_index = 10, loss.item() = 1.3339236974716187
epoch_no = 1, batch_index = 15, loss.item() = 0.44973278045654297
epoch_no = 1, batch_index = 20, loss.item() = 0.4216762185096741
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, val_acc = 0.6875
epoch_no = 1, batch_index = 5, val_acc = 0.7395833333333334
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 1, best_epoch = 1, best_acc = 0.7478632478632479
**************************验证模式:结束**************************
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第2轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, loss.item() = 0.5493289232254028
epoch_no = 2, batch_index = 5, loss.item() = 0.6154159307479858
epoch_no = 2, batch_index = 10, loss.item() = 0.6554363965988159
epoch_no = 2, batch_index = 15, loss.item() = 0.4766008257865906
epoch_no = 2, batch_index = 20, loss.item() = 0.45220986008644104
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, val_acc = 0.71875
epoch_no = 2, batch_index = 5, val_acc = 0.8020833333333334
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 2, best_epoch = 2, best_acc = 0.8076923076923077
**************************验证模式:结束**************************
利用整体数据集进行模型的第2轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第3轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, loss.item() = 0.6022523641586304
epoch_no = 3, batch_index = 5, loss.item() = 0.5406889319419861
epoch_no = 3, batch_index = 10, loss.item() = 0.22856442630290985
epoch_no = 3, batch_index = 15, loss.item() = 0.5484329462051392
epoch_no = 3, batch_index = 20, loss.item() = 0.36236143112182617
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.84375
epoch_no = 3, batch_index = 5, val_acc = 0.859375
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 3, best_epoch = 3, best_acc = 0.8589743589743589
**************************验证模式:结束**************************
利用整体数据集进行模型的第3轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第4轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, loss.item() = 0.47427237033843994
epoch_no = 4, batch_index = 5, loss.item() = 0.30755600333213806
epoch_no = 4, batch_index = 10, loss.item() = 0.7977475523948669
epoch_no = 4, batch_index = 15, loss.item() = 0.3868430554866791
epoch_no = 4, batch_index = 20, loss.item() = 0.46423253417015076
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.90625
epoch_no = 4, batch_index = 5, val_acc = 0.8958333333333334
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 4, best_epoch = 4, best_acc = 0.8931623931623932
**************************验证模式:结束**************************
利用整体数据集进行模型的第4轮Epoch迭代结束:**********************************************************************************************************************************
best acc: 0.8931623931623932 best epoch: 4
loaded from ckpt!
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.84375
epoch_no = 4, batch_index = 5, val_acc = 0.828125
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
test acc: 0.8290598290598291
Process finished with exit code 0
3.4 迁移学习 & 预训练ResNet18 & 自定义数据集-Pytorch
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torch.nn import functional as F
import visdom
import csv
import glob
import os
import random
from PIL import Image
from torch.utils.data import Dataset # 自定义数据集的父类
from torchvision import transforms
from torchvision.models import resnet18
torch.manual_seed(1234) # 随机种子
device = torch.device('cuda') # 设置GPU
# =============================================================================Pokemon自定义数据集:开始=============================================================================
class Pokemon(Dataset):
# root表示数据位置;resize表示数据输出的size;mode表示训练模式/测试模式
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 给各个类型进行编号
self.name2label = {
} # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)): # 过滤掉不是文件夹的文件
continue
self.name2label[name] = len(self.name2label.keys())
print('self.name2label = {0}'.format(self.name2label)) # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
# 读取已保存的图片+标签数据集
self.img_paths, self.labels = self.load_csv('img_paths.csv') # 数据对(img_path + image_label):img_paths, labels
# 对数据集根据当前模式进行裁剪
if mode == 'train': # 60%
self.img_paths = self.img_paths[:int(0.6 * len(self.img_paths))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 20% = 60%->80%
self.img_paths = self.img_paths[int(0.6 * len(self.img_paths)):int(0.8 * len(self.img_paths))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # 20% = 80%->100%
self.img_paths = self.img_paths[int(0.8 * len(self.img_paths)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
# 1、如果没有csv文件,则创建该csv文件
if not os.path.exists(os.path.join(self.root, filename)):
img_paths = [] # 把所有图片的path都保存在该list中,各个图片的label可以从path推断出来,所有没有单独保存。
for name in self.name2label.keys():
img_paths += glob.glob(os.path.join(self.root, name, '*.png')) # 'pokemon\\mewtwo\\00001.png
img_paths += glob.glob(os.path.join(self.root, name, '*.jpg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.jpeg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.gif'))
print('len(img_paths) = {0}, img_paths = {1}'.format(len(img_paths), img_paths)) # len(img_paths) = 1168, img_paths = ['pokemon\\bulbasaur\\00000000.png','pokemon\\bulbasaur\\00000001.png',...]
random.shuffle(img_paths) # 打乱list中的图片顺序
# 向csv文件保存图片的path+label
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img_path in img_paths: # 'pokemon\\bulbasaur\\00000000.png'
name = img_path.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img_path, label]) # 'pokemon\\bulbasaur\\00000000.png', 0
print('writen into csv file:', filename)
# 2、如果已经有csv文件,则读取该csv文件
img_paths, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img_path, label = row # 'pokemon\\bulbasaur\\00000000.png', 0
label = int(label)
img_paths.append(img_path)
labels.append(label)
assert len(img_paths) == len(labels)
return img_paths, labels
def __len__(self):
return len(self.img_paths)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('denormalize-->mean.shape = {0}, std.shape = {1}'.format(mean.shape, std.shape))
x = x_hat * std + mean
return x
def __getitem__(self, img_idx): # img_idx~[0~len(img_paths)]
img_path, label = self.img_paths[img_idx], self.labels[img_idx] # img_path: 'pokemon\\bulbasaur\\00000000.png';label: 0
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path --> image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15), # rotate如果比较大的话,可能会造成网络不收敛
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 该数值是实践中统计的效果比较好的值
])
img = transform(img_path)
label = torch.tensor(label)
return img, label
# =============================================================================Pokemon自定义数据集:结束=============================================================================
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
# =============================================================================训练主体:开始=============================================================================
batch_size = 32
viz = visdom.Visdom() # 在控制台开启Visdom:python -m visdom.server
global_step = 0
# 一、获取Pokemon训练数据集
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle=True, num_workers=0) # num_workers表示开启的线程数量
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=0)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=0)
# 三、实例化预训练ResNet18神经网络模型
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1], # 提取已经训练好的resnet18模型的前17层,打散。[b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5)
).to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train_epoch(epoch_no):
global global_step
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(train_loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch_no, batch_index, loss.item()))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
def evalute(epoch_no, loader):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
val_acc = total_correct / total_num
viz.line([val_acc], [global_step], win='val_acc', update='append')
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, val_acc = {2}'.format(epoch_no, batch_index, val_acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
return val_acc
def main():
epoch_count = 4 # epoch_count为整体数据集迭代梯度下降次数
best_acc, best_epoch = 0, 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no) # 训练
val_acc = evalute(epoch_no, val_loader) # 验证
if val_acc > best_acc:
best_epoch = epoch_no
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('epoch = {0}, best_epoch = {1}, best_acc = {2}'.format(epoch_no, best_epoch, best_acc))
print('**************************验证模式:结束**************************')
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(best_epoch, test_loader) # 测试
print('test acc:', test_acc)
if __name__ == '__main__':
main()
# =============================================================================训练主体:结束=============================================================================
打印结果:
Setting up a new session...
self.name2label = {
'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {
'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {
'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
11,179,077 total parameters.
11,179,077 training parameters.
model = Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): AdaptiveAvgPool2d(output_size=(1, 1))
(9): Flatten()
(10): Linear(in_features=512, out_features=5, bias=True)
)
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, loss.item() = 1.664962887763977
epoch_no = 1, batch_index = 5, loss.item() = 0.4224851131439209
epoch_no = 1, batch_index = 10, loss.item() = 0.3056411147117615
epoch_no = 1, batch_index = 15, loss.item() = 0.6770390868186951
epoch_no = 1, batch_index = 20, loss.item() = 0.778434157371521
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, val_acc = 0.875
epoch_no = 1, batch_index = 5, val_acc = 0.7239583333333334
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 1, best_epoch = 1, best_acc = 0.7136752136752137
**************************验证模式:结束**************************
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第2轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, loss.item() = 0.5391928553581238
epoch_no = 2, batch_index = 5, loss.item() = 0.641627848148346
epoch_no = 2, batch_index = 10, loss.item() = 0.28850072622299194
epoch_no = 2, batch_index = 15, loss.item() = 0.44357800483703613
epoch_no = 2, batch_index = 20, loss.item() = 0.15881212055683136
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, val_acc = 0.65625
epoch_no = 2, batch_index = 5, val_acc = 0.7447916666666666
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 2, best_epoch = 2, best_acc = 0.7478632478632479
**************************验证模式:结束**************************
利用整体数据集进行模型的第2轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第3轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, loss.item() = 0.11576351523399353
epoch_no = 3, batch_index = 5, loss.item() = 0.10171618312597275
epoch_no = 3, batch_index = 10, loss.item() = 0.19451947510242462
epoch_no = 3, batch_index = 15, loss.item() = 0.06140638515353203
epoch_no = 3, batch_index = 20, loss.item() = 0.049921028316020966
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.96875
epoch_no = 3, batch_index = 5, val_acc = 0.953125
++