pandas 转化np数据_利用Python进行数据分析(语法篇)
一、数据
结构化数据:
1.多维数组——矩阵
2.表格型数据(关系型数据库中的数据)
3.通过关键列相连接的表
4.间隔平均或者不平均的时间序列
二、关于iPython
三、Numpy学习
numpy是高性能科学计算和数据分析的基础包。它本身没有太多高级分析的功能,重点在于理解Numpy数组以及面向数组的计算。
1.Numpy.ndarray
ndarray中的元素必须都是相同类型,每个数组都有一个shape(一个表示各维度大小的元组,也就是几行几列)+一个dtype(说明数组类型的对象,数字啊还是字母什么的)
列表+np.array(列表) = 数组
嵌套列表(等长)+np.array(列表) = 多维数组
特殊的数组:np.array.zeros(x,y) 产生x行y列的全为0的数组
np.array.ones(x,y)全为1
np.arrary.empty(x,y)产生x行y列的随机数的数组
np.arrange()range的数组版
ps:Numpy中的数组的dtype基本上是浮点数、复数、整数、布尔值....如果需要转换type的话,用np.array.astype()
2.数组与标量之间的运算
数组与标量之间的运算很简单,是每一个数组里面的元素都和标量运算一遍,再返回到原有的索引位置。一维数组长得和列表差不多,很多功能也是很相似的。主要的区别在于:数组切片是原数组的视图,修改了元素之后,数据不会被赋值,而是直接反应到原数组上。(如果想要有副本,用copy()函数)
需要赋值就直接赋值即可,直接会被修改。
3.矩阵中的元素索引
在二维数组中,单一索引代表了是一维数组。要用元素的话索引得是[x][y[,表明寻求x行y列的那个元素。同理,一个索引降一维度,如果是n为数组,需要有[n][b][a]....[1],n个索引才能达到最后的单独的一个元素。
高阶维度的切片是沿着axis来切的。具体可以查阅别的blog.
4.bool型索引
numpy.random.randn()可生成随机数据
给出一个索引,满足索引条件的都会被打印出来。bool型索引可以和切片,整数序列混合使用。data[索引条件,切片](切片不写默认全data),有了这个找一些数据或者调整一些数据就会变得很简单。
5.数组转置和轴对换
T属性(转置)np.arrange.T()
np.dot函数计算转置数组和原数组的内积
对于高维数组,需要得到转置的轴才能进行转置,用transpose方法。transpose进行的操作其实是将各个维度重置。
还有一种swapaxes方法:接受一对轴编号进行变换。
6.通用函数(nfunc)
nfunc是针对ndarray里元素数据执行的函数。算是一般函数的矢量版。
有一元nfunc,针对一组数组。二元nfunc,针对二组数组。
7.利用数组处理数据
用数组表达式代替循环的计算方法,称为矢量化。
单纯的数据计算还是很普通的。学到了np.meshgrid()这样的方法。
8.将逻辑表述转化为数组运算
numpy.where函数是三元表达式(x if condition else y)的矢量化版本。
在数据分析工作中,常常用where来从数组A生成新的数组B。
numpy.where(cond,x,y)其中x,y不一定是数组,单纯的数据也行。where方法也可以进行逻辑上的嵌套。
数学和统计方法
sum,mean,std,var,min,max,argmin,argmax,cumsum,cumprod
这些都是需要考虑axis(轴方向的)。
用于bool型数组的方法
1.sum对bool型数组里面的true和false个数计数(True为1,False为0)
2.any 和all
唯一化以及其他集合逻辑
np.unique()返回数组里面的唯一的元素(滤去重复的)
np.in1d(x,12,3)看x中的数组元素是否有12,3.
9.用于数组以二进制输出输入
针对数组:一般用np.save()和np.load()
针对文本文件:np.loadtxt()和np.savetxt()
10.随机数生成
np.random()函数
四、pandas入门
1.pandas的数据结构介绍
Series和Dataframe
Series是由一组Numpy数组+各个数据的索引标签组成的类似于一维数组的对象。表现形式为左列为索引,右列为数据。
Series.values获得数组,Series.index获得索引。
Numpy数组的正常算法(加减乘除,条件过滤),在pandas中都会保留索引和值之间的连接。
自然有时候也可以把Series看做一种字典。索引可以找到对应的数组。索引也可以通过直接赋值的方式进行修改。
如有已生成的字典A,可以用个B = Series(A)来将字典转换成Series.
在数据丢失的情况下,我们会发现Series出现了NaN(表示数据缺失)。
对应的方法:pd.isnull(),pd.notnull(),Series.isnull()
Series的突出之处:在算数运算中它可以自动对齐不同索引的数据。(就是虽然不对齐,但是你知道应该要对齐的那些数据,很自动,很方便。)
DataFrame是一种表格型数据结构。DataFrame既有行索引也有列索引,且面向行和面向列的操作基本上平衡。
有很多种构建DataFrame的方法:
1.传入几个等长的数组(列表)作为一个整体的data,再用DataFrame(data)即可。和Series一样,DataFrame会自动添加索引。
类似于字典取需要的数据的方法:DataFrame["A"](A为其中的一个列),这样我们就可以得到类似于一个Series的数据,左边是索引,右边是DataFrame中的A列。同样可以进行类似的行操作DataFrame[S](S为某个行的标签)。
在DataFrame中赋值(主要几种)
1可以直接赋值
2也可以用一串数组赋值献给某个列(前提是长度要匹配)。
3也可以用Series进行精确赋值(先建立一个新列A,再创建一个新SeriesB(有数组,有索引),再用DataFrame['A'] = B)
在DataFrame中删除多余的列——del["列名"]
4 将嵌套字典(Series数组也差不多)赋给DataFrame.默认将外层字典的键作为了列名,内层字典的键作为了行索引(如果显示决定了索引,就按显示的来)。
ps:如果设置了DataFrame中index和column中的name属性(DataFrame.index.name())
就会显示出来的。DataFrame.values()的话,就会返回二维ndarray形式。
关于索引对象(略微知道即可)
pandas的索引对象负责管理轴标签和其他元数据(如轴名称),构建Series和DataFrame时,数据标签都会转成index.
index对象是不可修改的。
2.基本功能
重新索引:
Series.reindex(),重新在括号里面写索引index即可。
索引也有两种method:顺序填充,顺序填充ffill和倒序填充bfill.
example:obj.reindex(["1","2","3","4",“5”],method = ffill)
在DataFrame中,reindex可以修改整个行或者整个列。
如果只传了一个序列,就默认是修改行的。如果要修改列的话,需要多加一个column关键字赋值。(A = 序列 ,reindex(column = A))
当然,可以同时对行和列一起进行index的修改。
丢弃指定轴上的数:
在Series中,用Series.drop(index)函数,填哪些index,那一行或者一列就没有了。
在DataFrame中,可以删去任意轴上的index值。(在二维中,axis=0为列,axis=1为行)
关于Series的索引切片,方法类似于Numpy数组的索引,但是
1.索引出来的结果不是整数,会给出series的结果样子
2.切片是首尾的数字都包含的,而不是末尾-1

在DataFrame中,方式也类似。因为DataFrame为二维的表格,会显得更加有逻辑性,可以通过切片data[0:2]或者bool型条件进行选择(类似于data[data["Three"]>5])
DataFrame中有独特的索引方法(选取原DataFrame中的行列子集):
data.ix[["x',“c”],[a,s,d]]前者为行名,后者为列名。(如果是单个行或列,就不需要加括号了)!我实名证明!Data.ix[]是真的好用!
算术运算和数据对齐:
Pandas中的数据相加,自动取并集(能正常计算的就继续计算,不能的就返回一个NaN)
Series就是列并起来,DataFrame就是行和列同时搞定合并。
如果不想返回一个NaN,就在合并的时候用add方法并且多加一个参数fill_value = X,这样就会返回X,而不是NaN了。Data1.add(Data2,fill_value = X)
下面讲一下关于DataFrame和 Series之间的运算:
将series对标DataFrame中的某一行,就可以进行计算。会沿着某一行(之前用ix设定的行)一行行往下传播。
函数应用and映射:
1.Numpy中的nfunc方法可以应用于操作Pandas对象。
2.将函数应用到由各列或者各行组成的一维数组上。用pd.apply(f),f可以为自定义函数。(不太需要用,因为在设计的时候DataFrame的方法很多都可以直接用了 如sum mean)
顺序和排名:
Series——X.sort_index()or X.order()
DataFrame——X.sort_index(axis)#需要多加一个轴,便于排名,有单个/多个列需要给指定的列排序的话X.sort_index(by="列名"or["列名1","列名2"])
需要降序的话,就多加一个参数 ascending = False(这里不是按大小排序,而是按照列标签)
Data.rank()用于排名
带有重复值的轴索引:
某个索引对应多个值,返回一个Series.某个索引对应单指,返回对应的值。
汇总和计算描述统计:
1.用于在Series中提取单值(sum、mean等)
2.用于在DataFrame中提取一个Series。(多了需要考虑行列的方向轴axis)
常见的一些方法:
data.idmax() 返回某个轴的最大值索引或最小值索引。
data.cumsum()一行行或者一列列累加
data.describe()一次性返回很多数据。(针对Series和DataFrame中的Series来返回汇总数据)
相关系数与协方差:
data.A.corr(data.B)表示data中A列和B列之间的相关系数。
data.A.cov(data.B)表示data中A列和B列之间的协方差系数。
如果:data为Series,那就返回的是数据结果。如果是DataFrame,data.corr()返回的是完整的相关系数,data.cov()返回的是完全的协方差矩阵。
具体在DataFrame中某一行或列与其他Series或者其他DataFrame,需要用data.corrrwith()
传入一个Series会返回一个相关系数值Series.
传入一个DataFrame则会按名字返回配对的相关系数。
还有一个很高级的pandas方法:data.value——count(在Series和DataFrame中都可以用,返回出现频率,按计数值降序排列)
处理缺失数据:
Pandas中有专门的符号表示:NaN(表示浮点和非浮点数组中的缺失数据)
如何过滤掉缺失数据:Series.dropna() 返回一个仅含非空数据和索引的Series
对于DataFrame,dropna()默认将所有含有NaN的行列都删去。(有点错杀的感觉)
添加参数 how = ‘all’,这样将一列(行)全部都是NaN才删去
填充缺失数据:
1.用data.fillna()不加参数默认将所有的NaN填入()中的数据。
2.字典方法 data.fillna({列1:数据1;列2,:数据2})
层次化索引:
层次化索引是一种高级功能,使能在一条轴上拥有多个索引级别。(以低维度形式处理高纬度数据)
在DataFrame中,层次化索引很重要:通过unstack()和stack()方法,将一个拥有多重索引的轴的Series可以变成一个DataFrame.如图:

重排分级顺序:
用data.swaplevel(“key1”,“key2”)接受两个不同级别编号或者名称,并返回一个互换级别的对象。、
用data.sortlevel(axis)来进行顺序排序(按大小)
在DataFrame中,data.set_index()可以将一个列或者多个列转变成行索引,并创建一个新的DataFrame. data.resetindex()是data.set_index的逆变化.
Numpy高级用法
ndarray对象的内部机理:
组成:
指向数组的指针+dtype+一个表示数组shape的元组+一个跨度元组(为了前进到当前维度的下一个元素所需要跨过的字节数)
高级数组操作:
1.数组重塑
reshape方法:(一般由低维度数组转到高纬度数组)array = A,A.reshape(x,y)x为外维,y为内维。y=-1是一种特殊表示,表示内维的数据个数,由外围和数组的总数据个数决定(比如总数据有20,外维为4,那么内维就为20/4=5)
reshape的逆方法:
1.raveling(扁平化)表现形式为Data.ravel()——将高纬度数组转到低纬度数组。
2.flatten方法 Data.flatten()类似于ravel,但是不同在于返回的是副本。
原理:数组排列的顺序方式:C和Fortran顺序。
C顺序(行优先):先处理高维度的axis
F顺序(列优先):先处理低维度的axis
2.数组的合并与拆分
numpy.concatenate(arr1,arr2,axis)用来合并数组(可以从不同的方向进行合并)
别的方式:numpy.vstack((arr1,arr2))按列合并
numpy.hstack((arr1,arr2))按行合并
方法split(ary, indices_or_sections, axis=0) :把一个数组从左到右按顺序切分
参数: ary:要切分的数组
indices_or_sections:如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左闭右开) 比如原来的数组是0到9,按数组[1:3]切分:
就会得到[[0],[1,2,],[3,4,5,6,7,8,9]]
3.元素的重复操作:tile和repeat
arr.repeat有几种用法:1.arr.repeat(num) 将原本arr中的元素重复num遍
2.arr.repeat([num1,num2,num3...])针对不同元素重复不同的次数
ps:最好设置axis。
arr.title() 沿着指定axis堆叠副本(类似于铺瓷砖)
广播:(不同形状的数组之间的算数运算方式)
1.数组和数字之间的运算,将运算到数组内的每一个元素中.
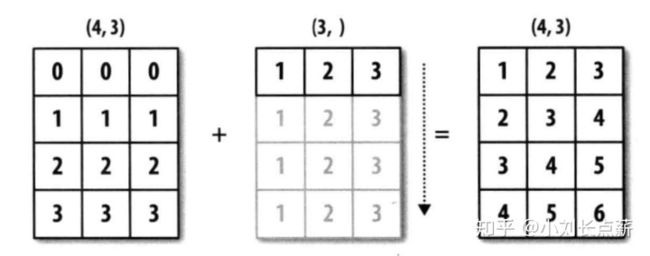
如果两个数组的最末尾开始算起的维度的轴长度相符或其中一方长度为1,那么我们认为这两个数组是兼容的,可以进行广播。
如果是高维的数组,可以广播的条件就是:将低维度的数组需要沿某个轴的方向广播的那个轴,置1.看图:
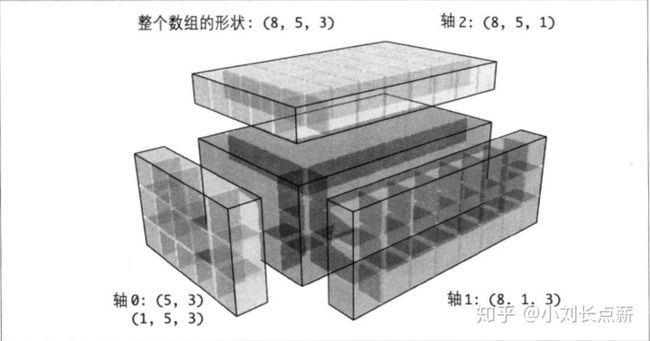
对于低维度的数组,如何插入那个为1的新axis:
arr[:,np.newaxis,:](全切片+newaxis方法)
把newaxis放在前面的时候
以前的shape是5,现在变成了1×5,也就是前面的维数发生了变化,后面的维数发生了变化
而把newaxis放后面的时候,输出的新数组的shape就是5×1,也就是后面增加了一个维数
所以,newaxis放在第几个位置,就会在shape里面看到相应的位置增加了一个维数。如果是前后都要“:”,那就是创建一个新的axis.
Ufunc高级应用:
Numpy的二元nfunc有用于特定矢量化运算的特殊方法。
np.add.reduce() 对数组中的各个元素进行求和。
np.add.accumulate() 产生一个和原数组相同大小的中间累计值的数组。
还有一种方法可以增加维度,不用用newaxis:np.subtract.outer(X,Y)输出的结果维度是X和Y的维度之和。(可以用此升维)
自定义nfunc:
函数向量化的几种方法:
1.np.frompyfunc(func,func中的参数个数,需要返回的参数格个数)此法需要先定义一个func。
2.numpy.vectorize(func)
在有序数组中查找元素:
numpy.searchsorted(可仔细学习)
Numpy的Matrix类
Numpy为了减少繁琐的矩阵运算代码,直接提供了Matrix类:单列或单行会以二维形式返回,使用*符号直接就是矩阵乘法。(ps:没有太多的线性代数运算就可以不太用这个)
Xm = np.matrix(x)
ym= Xm[:,0]#返回的就是二维的形式Matrix的特殊属性:matrix.I(返回矩阵的逆矩阵)
关于matrix类和正常ndarray的转换:Xm = np.matrix(x)
Ym = np.assarray(xm)
高级数组的输出输入
Numpy实现了一个对象:memmap。这个可以将大文件分成小段进行读写,可以用于ndarray的都可以实现在memmap.
mmap = np.memmap(“name”,“type”,“mode”,“shape”)就可创建一个新的mmap了.
其他关于内存映像的没有深入研究。
关于Numpy的性能建议:
1.将python循环和条件循环尽量转变为数组运算和bool数组运算。
2.尽量使用广播
3.避免复制数据,尽量用数据视图(切片)
4.利用ufunc的各种方法。
Matplotlib入门(绘图和可视化)
默认import matplotlib.pyplot as plt
Figure和Subplot
用plt.figure()可创建一个新的figure对象,add_subplot可创建子图
可以通过plt.subplot_adjust()来调整subplot之间的间距。
还有一些可以调标签,自定义标签。
通过label参数可以增加图例。ax.legend(loc = best)一般都用这个来决定label的位置。
在Matplotlib中绘制图像:
pyplot里面有很多图类型库,直接调用+参数就可。
Pandas绘图
pandas绘图有一个很好的地方就是,它的本来读取的数据就已经很有格式化了。有行有列,这样再加上已经造好的matplotlib轮子,绘图会变得很简单很简单。
大体分为两种 Series和DataFrame绘图。
Series的索引对象会自动传到Matplotlib,作为图像的X轴。
DataFrame的plot会自动给每一列数据绘制一条线。
绘图中不加参数,默认为折线图。需要绘制别的图就要加不同的参数:
1.柱状图,plot(kind = 'bar')
2.密度分布图,plot(kind = ‘kde’)
关于散状的scatter图,pandas有自带的pd.scatter_martrix()
举个例子:pd.scatter_matrix(data,diagonal =‘kde’,color =‘k’,alpha = 0.3)
处理数据高级运用:
1.合并数据集
数据集的合并或连接运算是通过一个或多个键将行连接起来的。
pandas的merge函数:(下面默认data都是创建好的DataFrame格式)
pd.merge(data1,data2)(没有指定的话,会自动将重叠的列名当做键进行连接,比如共享一个key列)
合并的方式有很多种,默认为 inner(取数据之间的交集)还有别的:outer(并集),left、right
合并的数据有单对多,多(一个键对n个值)对多(同样的键对m个值),单对多就是排出
merge函数中有个参数选项suffixes(用于指定附加重叠列名上的字符串(类似于改名吧))
之前都是将列名作为键进行Data之间的连接,下面我们将索引变成连接的对象:
1.一般的数据索引对象(无层次化)(left_index=True 或者right_index = True )
2.层次化的索引对象(关于层次化索引已经在Pandas入门中介绍):好像方法同上(后期具体分析哈)
DataFrame中的join方法可以很方便的通过索引来连接不同的数据。例:data.join(data2,how =‘outer’)
轴向合并:Pandas之concat函数
pd.concat(data1,data2,....)可以用来合并没有重复索引值的数据Series,默认是在axis= 0.具体的方法看官方文档。
重塑和轴向旋转
1.重塑层次化索引:pd.stack()将数据的列变为行
pd.unstack()将数据的行变为列
2.移除重复数据:Series.drop_duplicates(默认全部列,可单独筛选['列1','列2'])
重命名轴索引:
1.data.index.map()(在括号里面可以直接修改轴的内容)
2.创建数据集的转换版——data.rename()
1.可以直接用index,column直接赋值给dataFrame
2.可以利用字典的格式,键为原本的某个index,值为新的index,进行赋值。
离散化和元面划分:
pd.cut(A,B)A为目标分组的类别,B为目标被分组的数据,返回的是一个二维数组(数组由每个数据所在的分组构成)+含有以目标分组为名的label属性。默认分组为闭区间(元面边界),如果右边需要开区间,添加参数 right = False)
ps:如果cut传入的是面元数量,会根据数据的最小值和最大值进行面元均分。
qcut和cut类似,不同之处在于他的元面内数据个数相同。(这两个函数很重要,用于分割数据,使数据离散化)
排列和随机采样:
1.numpy.random.permutation()只是将dataFrame或Series中一列数据进行重新排序,具体的顺序应自己给出。np.random.permutation(5)——对于前五列随机排序
一个选取子集的例子:df.take(np.random.permutation(len(df)[:3])
计算指标/哑变量(用于机器学习、数学建模)
将分类变量转变为指标矩阵:如果有个DataFrame一列有7个不同的值,可派生出一个k列矩阵(值全为1或0)pd.get_dummies()
一个统计应用的tip:结合get_dummies和pd.cut等离散化函数。
数据聚合和分组运算
主要是用于对数据集进行分组,并对各个数据集进行某种func运算。
pandas之GroupBy技术
分组运算的过程:split—apply—combine
df.['data1'].groupby["key"]——获取data1中key的所在的列的数据(分组键),并返回一个GroupBy数据。然后可以根据GroupBy数据进行各种运算。
分组键有以下几种:
1.列表与数组,长度与待分组的数据长度相等
2.表示DataFrame中某个列名的值
3.字典或Series,给出值与分组名的关系
4.函数
也可以根据索引级别(多个索引的情况下)进行聚合,通过关键字 level = ‘index名’
df.groupby[sadasd].size() 返回一个含有分组大小的Series.
数据聚合:
定义:能够从数组产生标量值的数据转换过程。(比如mean,sum,count等最基本的方法)
对于Series或DataFrame列的聚合运算其实就是用
1.aggregate(使用自定义函数)
2.mean,sum等方法
更多的其他分组运算:
1.在GroupBy上使用transform方法(将一个函数应用到各个分组,然后将结果放置到适当的位置上) dataframe.groupby('key').transform(np.mean)——这里就是np的平均值方法。
2.apply(对对象的拆分-应用-合并)
小例子:随机采样和排列
从一个大数据集中随机抽取样本以进行蒙特卡罗模拟。
np.random.permutation(N)的前K个元素。K为期望的样本大小,N为完整数据的大小。
交叉表:crosstab 用于计算分组频率的特殊透视表
pd.crosstab(data.index1,data.index2,margins = True) 前面两个参数可以是数组、Series或者数组列表。
数据加载、存储与文件格式
输入输出常分为几个类:
1.读取文本文件或其他更高效的磁盘存储格式
2.加载数据库中的数据,利用web API操作网络资源
pandas有几种可以读取数据的方法,用的比较多的:
1.pd.read_csv(csv文件),默认分割符号为逗号的文件
2.pd.read_table(csv文件,sep = ‘分割标志’)
遇到没有标题行的文件,我们可以自己设置标题 pd.read_csv(文件名,names = ['a','b','c','d....]
希望将多个列做成一个层次化索引,传入列名组成的列表:
pd.readcsv(文件,index_col= ['key'1,'key2']
需要处理有缺失数据的dataframe时,可以传递参数na_values
pd.readcsv(‘文件名’,na_values= ['NULL']) 这个方括号很重要,每次我都容易忘掉。
当文件特别大,不便于一次读取时,可以用 nrow =n,来选择先读取n行。
书p168有一个很好的例子,先选数据,然后利用循环进行聚合。
如何将数据写到文本呢——data.to_csv(文件)
读取Microsoft Excel文件:
pd.ExcelFile(‘data.xls’)——创建一个excelfile实例
pd.ExcelFile.parse(‘sheet1’)读取存放在某个工作表的数据