leetcode第198场周赛题目及题解
leetcode第198场周赛题目及题解
第一题 leetcode1518 换酒问题
题目简介
小区便利店正在促销,用 numExchange 个空酒瓶可以兑换一瓶新酒。你购入了 numBottles 瓶酒。
如果喝掉了酒瓶中的酒,那么酒瓶就会变成空的。
请你计算最多能喝到多少瓶酒。
示例1

输入:numBottles = 9, numExchange = 3
输出:13
解释:你可以用 3 个空酒瓶兑换 1 瓶酒。
所以最多能喝到 9 + 3 + 1 = 13 瓶酒。
数据范围
1 <= numBottles <= 100
2 <= numExchange <= 100
题目分析
这是一道模拟题,我们直接模拟就行了。
代码展示
class Solution {
public:
int numWaterBottles(int numBottles, int numExchange) {
int res=numBottles;
while(numBottles>=numExchange)
{
numBottles-=numExchange-1;
res++;
}
return res;
}
};
第二题 leetcode1519 子树中标签相同的节点数
题目简介
给你一棵树(即,一个连通的无环无向图),这棵树由编号从 0 到 n - 1 的 n 个节点组成,且恰好有 n - 1 条 edges 。树
的根节点为节点 0 ,树上的每一个节点都有一个标签,也就是字符串 labels 中的一个小写字符(编号为 i 的 节点 的标签就
是 labels[i] )
边数组 edges 以 edges[i] = [ai, bi] 的形式给出,该格式表示节点 ai 和 bi 之间存在一条边。
返回一个大小为 n 的数组,其中 ans[i] 表示第 i 个节点的子树中与节点 i 标签相同的节点数。
树 T 中的子树是由 T 中的某个节点及其所有后代节点组成的树。
示例1

输入:n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd"
输出:[2,1,1,1,1,1,1]
解释:节点 0 的标签为 'a' ,以 'a' 为根节点的子树中,节点 2 的标签也是 'a' ,因此答案为 2 。注意树中
的每个节点都是这棵子树的一部分。
节点 1 的标签为 'b' ,节点 1 的子树包含节点 1、4 和 5,但是节点 4、5 的标签与节点 1 不同,故而答案
为 1(即,该节点本身)。
数据范围
1 <= n <= 10^5
edges.length == n - 1
edges[i].length == 2
0 <= ai, bi < n
ai != bi
labels.length == n
labels 仅由小写英文字母组成
题目分析

这道题实质上是一个树形DP的题目,每个节点的子树中标签和这个节点相同的节点数等于各个子树中的标签相同的
节点数+1(自己本身)。所以我们能够得到状态转移方程,f[1]['a']=f[2]['a']+f[3]['a']+f[4]['a']+1。
代码展示
class Solution {
public:
vector<int> ans;
vector<vector<int>> g;
vector<vector<int>> res;
string la;
void dfs(int u,int f)
{
for(int i=0;i<g[u].size();i++)
if(g[u][i]!=f)
{
dfs(g[u][i],u);
for(int j=0;j<26;j++) res[u][j]+=res[g[u][i]][j];//状态转移
}
res[u][la[u]-'a']++; //加上自己本身
}
vector<int> countSubTrees(int n, vector<vector<int>>& edges, string labels) {
la=labels;
g.resize(n);
res.resize(n);
for(int i=0;i<n;i++) res[i].resize(26);
for(auto &edge:edges)
{
int x=edge[0],y=edge[1];
g[x].push_back(y);
g[y].push_back(x);
}
dfs(0,-1);
for(int i=0;i<n;i++) ans.push_back(res[i][labels[i]-'a']);
return ans;
}
};
第三题 leetcode1520 最多的不重复子字符串
题目简介
给你一个只包含小写字母的字符串 s ,你需要找到 s 中最多数目的非空子字符串,满足如下条件:
1. 这些字符串之间互不重叠,也就是说对于任意两个子字符串 s[i..j] 和 s[k..l] ,要么 j < k 要么 i > l 。
2. 如果一个子字符串包含字符 char ,那么 s 中所有 char 字符都应该在这个子字符串中。
请你找到满足上述条件的最多子字符串数目。如果有多个解法有相同的子字符串数目,请返回这些子字符串总长度最小
的一个解。可以证明最小总长度解是唯一的。
请注意,你可以以 任意 顺序返回最优解的子字符串。
示例1
输入:s = "adefaddaccc"
输出:["e","f","ccc"]
解释:下面为所有满足第二个条件的子字符串:
[
"adefaddaccc"
"adefadda",
"ef",
"e",
"f",
"ccc",
]
如果我们选择第一个字符串,那么我们无法再选择其他任何字符串,所以答案为 1 。如果我们选择 "adefadda" ,
剩下子字符串中我们只可以选择 "ccc" ,它是唯一不重叠的子字符串,所以答案为 2 。同时我们可以发现,选择
"ef" 不是最优的,因为它可以被拆分成 2 个子字符串。所以最优解是选择 ["e","f","ccc"] ,答案为 3 。不存
在别的相同数目子字符串解。
数据范围
1 <= s.length <= 10^5
s 只包含小写英文字母。
题目分析
我们首先预处理出来每个极小的待选的字符串,然后再在这些字符串中尽可能地选择更多地不相交的区间,就是答案。
经过分析我们可以知道,这些极小的待选字符串最多只有26个。预处理这些极小的待选的字符串,我们可以通过两步得到。
第一步,扫面一遍字符串,将每个字符的左右边界记录。因为,每个待选字符串如果包含一个字符,那么就必须包含整个
字符串中的所有这个字符,所以我们还需要第二步来进行更新每个待选区间。第二步,一直迭代,直到没有更新为止 。
迭代的主要内容为:依次扫描每个待选字符串,如果这个待选字符串中包含c字符,那么就用c字符的待选区间来更新当前
这个区间。
当我们得到这些待选字符串之后,我们可以发现,这些待选字符串,不存在相交但不包含的关系,一旦相交就必须包含。
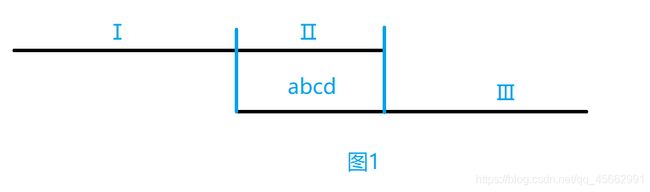
如图1,如果两个区间出现相交的情况,我们假设Ⅱ段为 abcd ,那么Ⅰ和Ⅲ 段一定不包括 abcd 。如果Ⅰ和Ⅲ 段不包括
abcd 那么我们完全可以将 Ⅱ段去掉,得到两个较小的待选字符串,这与我们找出极小的待选字符串矛盾,所以我们可以
知道,我们得到的待选字符串,如果相交就一定是包含关系。因为我们要得到更多的字符串而且要保证字符串的长度尽可
能小。所以我们将包含其他字符串的字符串删掉,剩下的就是答案了。
代码展示
class Solution {
public:
vector<string> maxNumOfSubstrings(string s) {
s=' '+s;
int n=s.size();
vector<vector<int>> sum(26,vector<int>(n));
vector<vector<int>> range(26,{
INT_MAX,INT_MIN});
for(int i=1;i<s.size();i++)
{
int t=s[i]-'a';
for(int j=0;j<26;j++)
{
sum[j][i]=sum[j][i-1];
if(j==t) sum[j][i]++;
}
range[t][0]=min(range[t][0],i);
range[t][1]=max(range[t][1],i); //第一步
}
while(true) //第二步
{
bool ok=true;
for(int i=0;i<26;i++)
{
if(range[i][0]>range[i][1]) continue;
auto cur=range[i];
for(int j=0;j<26;j++)
{
if(sum[j][cur[1]]>sum[j][cur[0]-1])
{
cur[0]=min(cur[0],range[j][0]);
cur[1]=max(cur[1],range[j][1]);
}
}
if(cur!=range[i])
{
ok=false;
range[i]=cur;
}
}
if(ok) break;
}
for(int i=0;i<26;i++) //将包含其他字符串的字符串删掉
for(int j=0;j<26;j++)
{
if(i!=j&&range[j][0]<=range[j][1]&&range[i][0]<=range[j][0]&&range[i][1]>=range[j][1])
range[i]={
INT_MAX,INT_MIN};
}
vector<string> ans;
for(int i=0;i<26;i++)
{
if(range[i][0]<=range[i][1])
ans.push_back(s.substr(range[i][0],range[i][1]-range[i][0]+1));
}
return ans;
}
};
第四题 leetcode1521 找到最接近目标值的函数值
题目简介

Winston 构造了一个如上所示的函数 func 。他有一个整数数组 arr 和一个整数 target ,他想找到让
|func(arr, l, r) - target| 最小的 l 和 r 。
请你返回 |func(arr, l, r) - target| 的最小值。
请注意, func 的输入参数 l 和 r 需要满足 0 <= l, r < arr.length 。
示例1
输入:arr = [9,12,3,7,15], target = 5
输出:2
解释:所有可能的 [l,r] 数对包括 [[0,0],[1,1],[2,2],[3,3],[4,4],[0,1],
[1,2],[2,3],[3,4],[0,2],[1,3],[2,4],[0,3],[1,4],[0,4]], Winston 得到的相应结果为
[9,12,3,7,15,8,0,3,7,0,0,3,0,0,0] 。最接近 5 的值是 7 和 3,所以最小差值为 2 。
数据范围
1 <= arr.length <= 10^5
1 <= arr[i] <= 10^6
0 <= target <= 10^7
题目分析
首先,我们可以知道最优解是不可能出现l>r的情况,因为这种情况会得到10^9的函数值,这样答案就是10^9级别,但
是我们arr数组最大值为10^6,也就是说当l<=r的时候,答案为10^7级别,所以最优解不会出现在l>r的情况里。暴力
解法为:依次枚举每一个l<=r的区间,然后得到这个区间的函数值,这样的时间复杂度为O(n^3),于是我们可以考虑
怎么优化枚举区间和快速得到每个区间的函数值。对于快速得到每个区间的函数值,我们可以通过用前缀和数组记录每
个数位上的0的个数,然后通过判断这个区间的每个数位上是否出现0,来快速得到每个区间的函数值。对于枚举区间,
如图2,每一个区间一定都是以arr上的每个点结尾的,如果我们考虑以i结尾的区间,我们找到一个最靠右的一个点j
使 j i区间里的函数值<=target,那么[j,i]和[j+1,i]就是以i结尾的区间的最优解可能出现的两个区间。当我们考
虑以i+1结尾的区间的时候,j是不用往左走的,因为[j,i]<=target,则[j,i+1]一定<=target,
[j-1,i+1]<=[j,i+1]<=target,所以[j-1,i+1]一定不是以i+1结尾的最优解,所以j只用往右走就行了,所以我们可以
用双指针来枚举每个区间。

代码展示
class Solution {
public:
vector<vector<int>> s;
int get_sum(int l,int r)
{
int res=0;
for(int i=0;i<20;i++)
if(s[i][r]-s[i][l-1]==0)
res+=1<<i;
return res;
}
int closestToTarget(vector<int>& arr, int target) {
int n=arr.size();
s=vector<vector<int>>(20,vector<int>(n+1));
for(int i=0;i<20;i++) //得到每个数位上0的个数的前缀和数组
for(int j=1;j<=n;j++)
{
s[i][j]=s[i][j-1];
if((arr[j-1]>>i&1)==0) s[i][j]++;
}
int res=INT_MAX;
for(int i=1,j=1;i<=n;i++) //双指针枚举每个区间
{
while(j+1<=i&&get_sum(j+1,i)<=target) j++;
res=min(res,abs(get_sum(j,i)-target));
if(j<i) res=min(res,abs(get_sum(j+1,i)-target));
}
return res;
}
};
本篇文章题目简介部分均引自leetcode网站。